模型部署基础知识
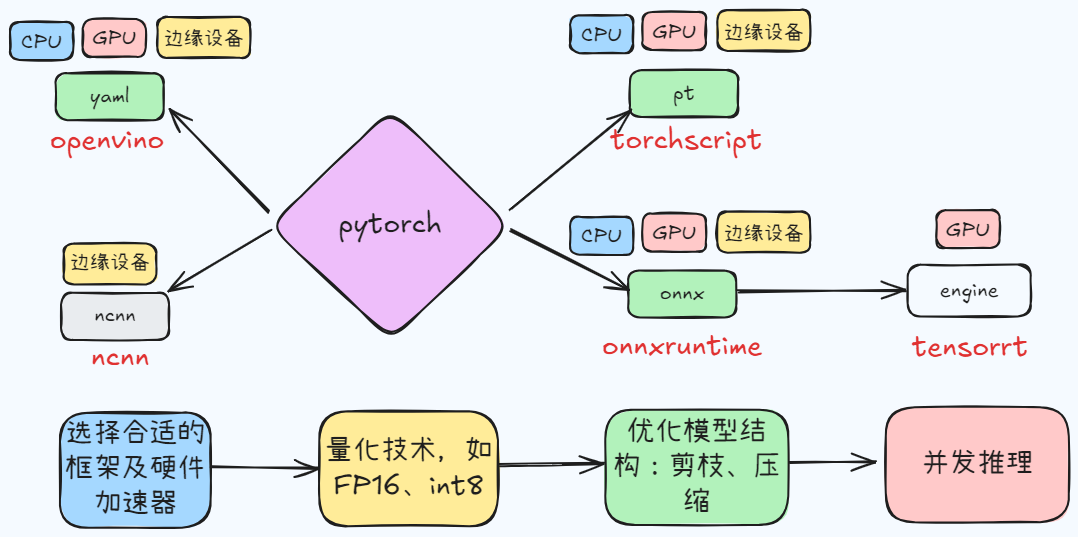
从模型部署的转换、压缩讲起,然后总结移动端的模型部署,目前部署思路如上
从模型部署的转换、压缩讲起,然后总结移动端的模型部署,目前部署思路如上
只在宿主机安装 cuda 时,在 docker 还无法利用 GPU,还需要安装 nvidia-container-toolkit
将 CNN 的思想引入 GAN,使得样本生成质量更高
噪声 -> 随机图片,随机图片
不使用成对图片,通过两对 GAN 完成两个域的图片转换
图 A + 图 B-> 实现 A->B 或者 B->A,图生图
将类别信息 + 随机数作为生成器输入,使得生成器生成内容有指向性
(图 A->z)->z’ (离散化)-> 图 A’,随机图片
Docker,这个近年来在软件开发和运维领域广受追捧的技术,究竟是什么?它如何实现资源隔离?它的运行方式是否类似于 Java 虚拟机(JVM)?Docker 的组成又是什么?本文将一一解答这些问题。
(图 A->z)->z’ (离散化)-> 图 A’,随机图片
记录 docker 常用命令
VQ-VAE 因在潜在表示空间使用自回归神经网络,捕捉到了更多的结构化的全局关联信息;VQ-VAE-2
将顶层全局与底层局部信息分离开来,生成全局自洽,局部高清的图像
(图 A->z)->z’ (离散化)-> 图 A’,随机图片