SnapFusion
什么是 SnapFusion ?
![]()
- 已知 Stable Diffusion 模型分为三部分:VAE decoder, text encoder, UNet,由上图可知,主要是 Unet 的迭代导致模型推理时间过长
- SnapFusion 通过优化 UNet、VAE decoder 实现在手机上 2 秒的推理速度,

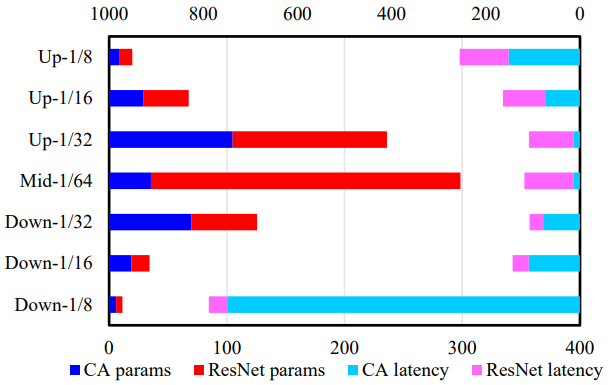
SnapFusion 的 Unet 过程的参数与推理时延分析?
![]()
- 参数量:就 Unet 的参数量而言,靠近中间层的参数量最多,因为这里通道数量多,Resnet 参数多
- 推理时延:就推理时延来说,第一次下采样最高,因为此时分辨率最大,交叉注意力最耗时
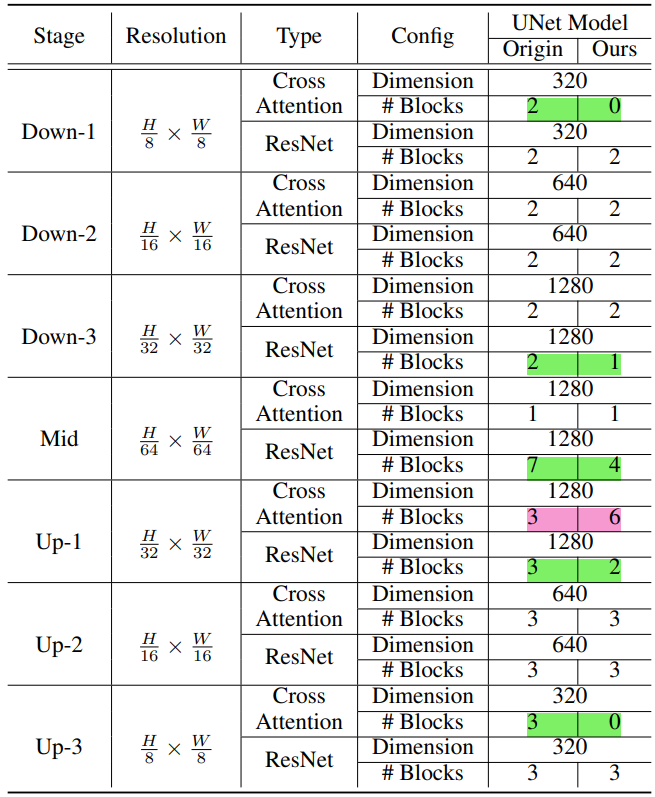
SnapFusion 如何构建出 Efficient UNet ?
![]()
- 想要找到一个高效的 UNet 结构,直接采用传统的剪枝或 NAS 方法会非常耗时,因为 SD 的训练时间很长。为了解决这个问题,这里采用了 robust training 的方法,在前向传播的过程中以一定的概率用 identity mapping 替换交叉注意力 (CA) 模块和 ResBlock,这样做的目的是评估网络中不同模块的作用
- 在 robust training 进行到一定轮数后对当前网络进行评估:通过计算删除某一个模块前后,CLIP 分数变化和延迟变化的比值,如果当前网络的延迟高于目标要求,就挑选出得分最低(贡献低延迟高)的模块,从网络中删除;反之,挑选出得分最高的模块,复制一份添加到这个模块的后面。然后在新的网络结构上继续 robust training,训练结束后的网络即为最终结构,无需重新训练
![]()

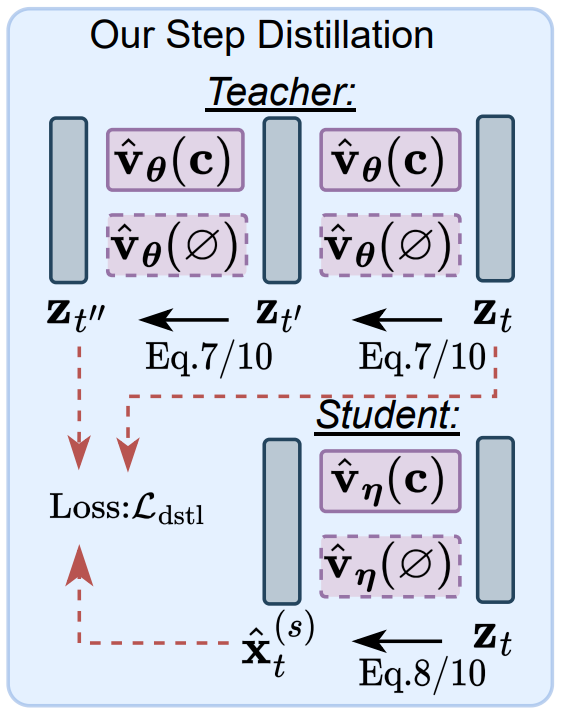
SnapFusion 如何对 Unet 蒸馏?
![]()
- 减少需要扩散的次数可以更进一步减少 UNet 的耗时,借鉴 step distillation 思想,用教师模型多步的输出蒸馏学生们模型单步的输出,从而减少学生模型需要扩散的步数
- 1)使用 32-step 的 SD-v1.5 模型跨步蒸馏得到 16-step 的 SD-v1.5 模型
- 2)使用 32-step 的 efficient UNet 模型跨步蒸馏得到 16-step 的 efficient UNet 模型
- 3)使用步骤 1 中的 16-step 的 SD-v1.5 作为教师模型,使用步骤 2 中的 16-step 的 Efficient UNet 模型作为学生模型的初始化,跨步蒸馏得到 8-step 的 efficient UNet 模型,即最终模型
- 蒸馏损失函数由两部分组成 Vanilla Step Distillation 和 CFG-Aware Step Distillation,这两个损失函数以随机采样的方式交替训练
- 教师模型的 UNethical 进行两步 DDIM 去噪,即从
- Vanilla 是无条件的扩散模型的蒸馏损失,即没有文本特征输入,可以有效降低蒸馏模型的 FID
- CFG-Aware 是有条件的扩散模型的蒸馏损失,有文本特征输入,可以有效提升蒸馏模型的 CLIP score
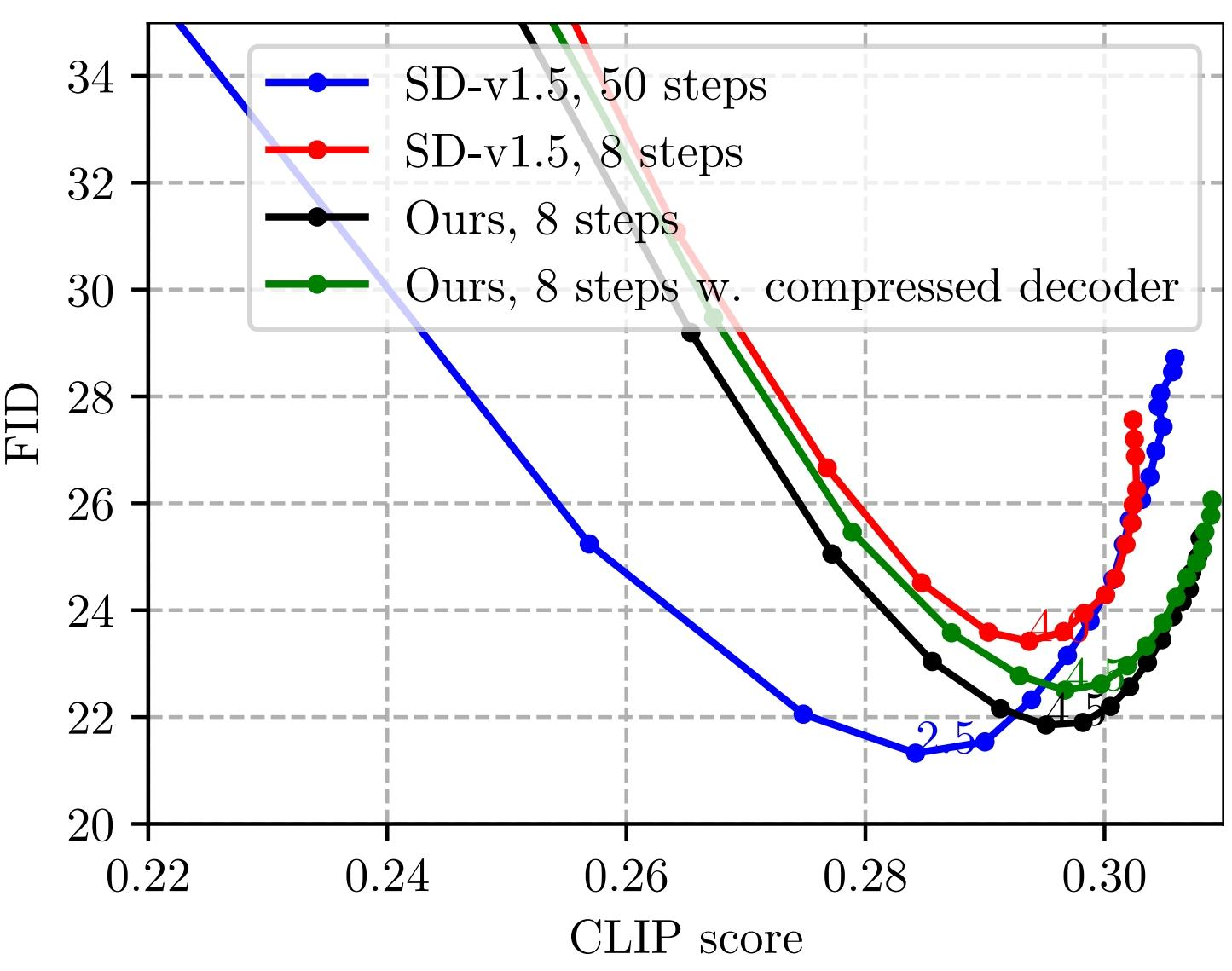
SnapFusion 如何加速 VAE Decoder 过程?
![]()
- SnapFusion 使用了 Efficient VAE Decoder,加速方式是裁剪通道蒸馏,即将 SD-v1.5 的 VAE Decoder 裁剪 50% 的通道数量。蒸馏训练采用单独训练 VAE Decoder 的方式,即学生和教师的 VAE Decoder 同时输入 SD-v1.5 的 UNet 经过 50 个 steps 的 latent,计算生成的两张图片间的 MSE
- 压缩后的 VAE Decoder(绿线)有与原模型(黑线)相近的 FID 和 CLIP score,生成效果也看起来差不多
![]()

参考: