StableDiffusion-LDM
StableDiffusion 利用 autoencoder 模型将图片编码到潜在空间,然后使用 classfier-free 的 DM 模型在潜在空间进行 diffusion,假设了 DM 模型生成速度慢的问题,为落地提供帮助
什么是 StableDiffusion?
![]()
- Stable diffusion 是一个基于 Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型
- Latent Diffusion Models 通过在一个潜在表示空间中迭代 “去噪” 数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级 GPU 上,在 10 秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火
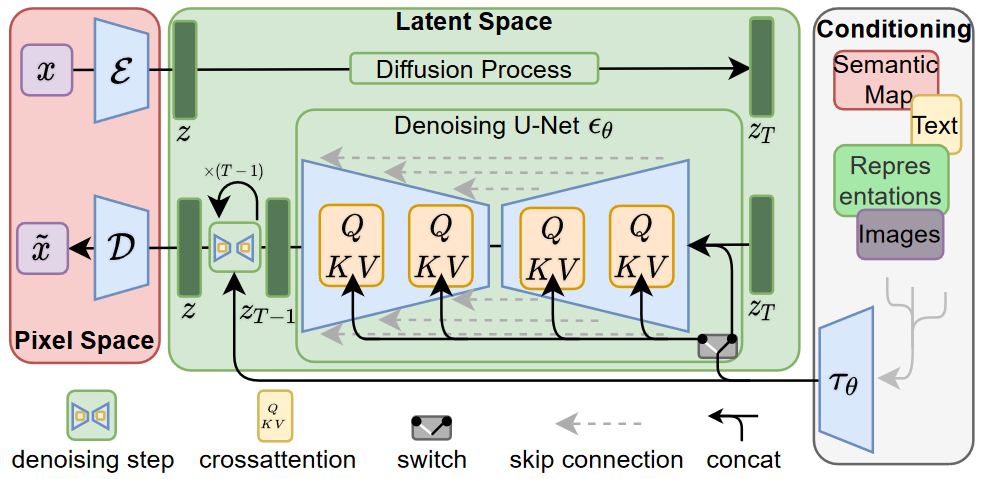
StableDiffusion 的原理?
![]()
- 首先需要训练好一个自编码模型(AutoEncoder),用于将图片压缩到潜在空间,然后在潜在表示空间上做 diffusion 操作,最后我们再用解码器恢复到原始像素空间即可
- 图片感知压缩(Perceptual Image Compression):感知压缩主要利用一个预训练的自编码模型(AutoEncoder),该模型能够学习到一个在感知上等同于图像空间的潜在表示空间
- 潜在扩散模型(Latent Diffusion Models):在潜在表示空间上做 diffusion 操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet
- 条件机制(Conditioning Mechanisms):除了无条件图片生成外,我们也可以进行条件图片生成,这主要是通过拓展得到一个条件时序去噪自编码器(conditional denoising autoencoder) 来实现的,这样一来我们就可通过 y 来控制图片合成的过程
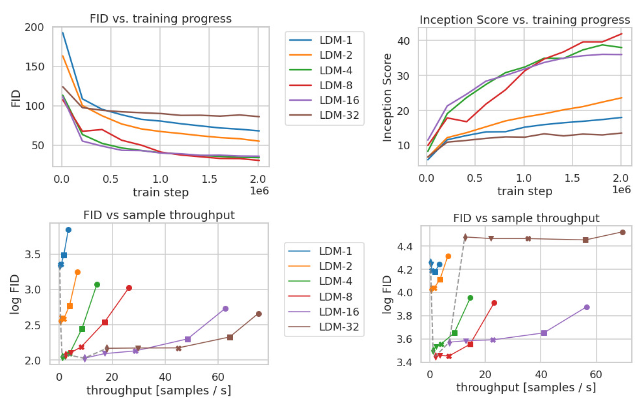
StableDiffusion 的感知压缩权衡(Perceptual Compression Tradeoffs)?
![]()
- LDMs 在潜空间的下采样系数 ,也就是 autoencoder 的下采样因子 f ,其中 ,如果 f=1 那就等于没有对输入的像素空间进行压缩,如果 f 越大,则信息压缩越严重,可能会噪声图片失真,但是训练资源占用的也越少
- 由图可以看出,发现 f 在 {4−16} 之间可以比较好的平衡压缩效率与视觉感知效果
参考: