SDG
什么是 SDG ?
![]()
- 基于 classifier guidance DM 后,把分类器替换成其它任意的判别器,也即更换引导条件,从而实现利用不同的语义信息来指导扩散模型的去噪过程。比如说可以实现 text-guidance 和 image-guidance 等

SDG 的原理?
![]()
![]()
- 实质上就是把 classifier guidance 的条件推广,生成图像过程表达如下,其中 表示新的引导条件,其实也可以换成相似度之类的分数指标,比如图像引导、文本引导、图像 + 文本引
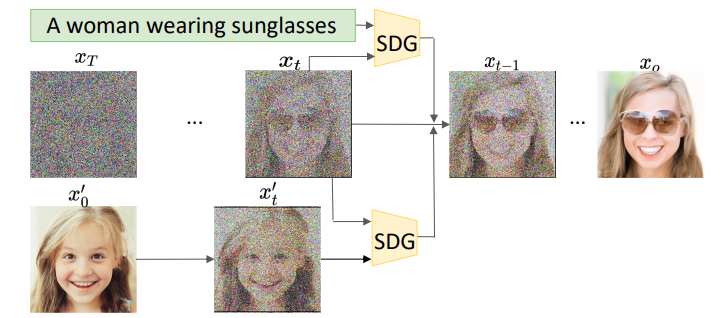

- 引导器的 要求使用加躁过程中的图片重新训练引导器,所以本文使用重新训练了 CLIP
SDG 的引导器如何训练?
- 借助 CLIP 模型里文本和图像之间对齐的表征来做一些损失计算了
- 文本引导:每一步都计算现在的图像表征和文本表征的距离,使用方程的梯度来计算缩小这个距离的方向,最简单的方式莫过于余弦距离
- 图像引导:在图像上,如果只使用余弦距离没有考虑到空间信息和风格信息。论文在这里使用了更加具体的损失。一个是考虑空间布局的对应特征图里对应位置的 L2 范式差,和考虑风格信息的对应特征图的量化感知损失
SDG 、 IVLR 的区别?
![]()
- 同样是图片引导,IVLR 的引导只能固定整体的图片布局。而 SDG 既可以生成更加多样的姿态,也可以保留相应的姿态,对于文本引导的生成其生成的图像也更为多样
- 但是随着 GLIDE 提出的隐式分类器引导的图像生成,SDG 不再是主流

参考: