CILP:Learning Transferable Visual Models From Natural Language Supervision
CLIP 通过文本 - 图像对实现对模型预训练,上图是是 3 个文本 - 图像对,每个文本 - 图像对由一段文本 + 一张片表示,文本描述了这个图片的内容(对象类别),CLIP 模型收集 **4 亿(400million)个文本 - 图像对
什么是 CILP ?
![]()
- Contrastive Language-Image Pre-training (CLIP) 是一个联通文本和图像的模型,比如输入图片和提示文本,模型输出图片类别
- CLIP 通过文本 - 图像对实现对模型预训练,上图是是 3 个文本 - 图像对,每个文本 - 图像对由一段文本 + 一张图片表示,文本描述了这个图片的内容(对象类别),CLIP 模型收集 **4 亿(400 million)个文本 - 图像对

CILP 的网络结构?
![]()
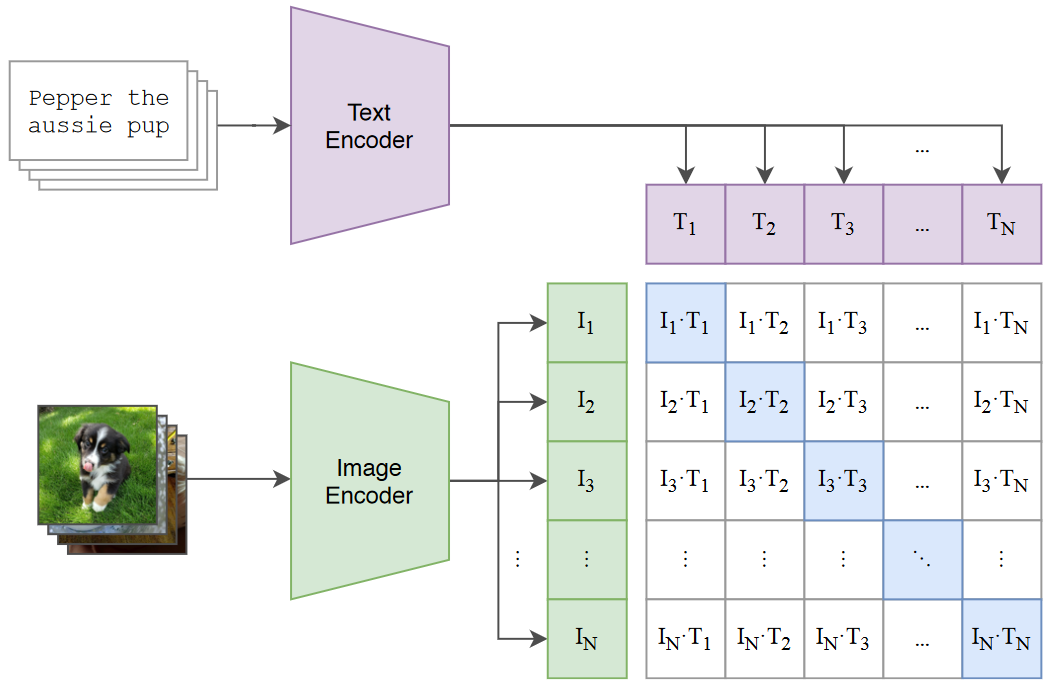
- CLIP 模型包含两部分,即文本编码器 (Text Encoder) 和图像编辑器 (Image Encoder),Text Encoder 选择的是 Text Transformer 模型;Image Encoder 选择了两种模型,一是基于 CNN 的 ResNet(对比了不同层数的 ResNet),二是基于 Transformer 的 ViT
- 编码器作用:假设一次输入 N 个文本对,N 个文本首先经过文本编码器 (Text Encoder) ,输出 [],每个文本的输出是长度为 的向量,对应的 N 个图片经过图像编辑器 (Image Encoder),输出 [],每张图片输出也是长度为 的向量
- 自监督训练:得到 [] 和 [] 两两组合构成一个矩阵,其中 与 匹配,否则不匹配,将匹配的文本 - 图片对标记为正样本,共计 N 个,不匹配的文本 - 图像对标记为负样本,共计 N^2-N 个。通过正负样本可训练 Text Encoder 和 Image Encoder
- 损失函数:对于每个文本 - 图片对的输出,其都是长度为 的向量,计算损失时通过余弦相似度计算损失即可,对于匹配的文本 - 图片对,其损失越小越好,对于不匹配的文本图片对,其损失越大越好,即
文本编码器和图像编码器为什么只输出一维特征?
![]()
- 编码器输出:对于每个文本 - 图片对,正常 N 个长度为 S 的文本输入 transformer,其输出是 (N, S, di),同理图片输出应该是 (N, S’, dt),如果只输出 (N, di) 或 (N, dt),那就是类似 Vit 的情况,增加一个 class token 汇总所有 tokens 的信息,或者平均所有的 S 作为输出;
- 输出映射:即使文本编码器输出 (N, di),图片编码器输出 (N, dt),最后一维还是长度不一样的,此时分别学习一个 W_i(di, de)、W_t(dt, de)的嵌入,与前面两个输出点乘都得到长度为 (n, de) 的输出,然后才能计算模型输出的余弦相似度损失
- 输出映射相当于 transformer 的 decoder 的输入,可以认为是文本或图片的 quies 查询向量,找出有用特征计算损失

CILP 的 zero-shot 分类?
![]()
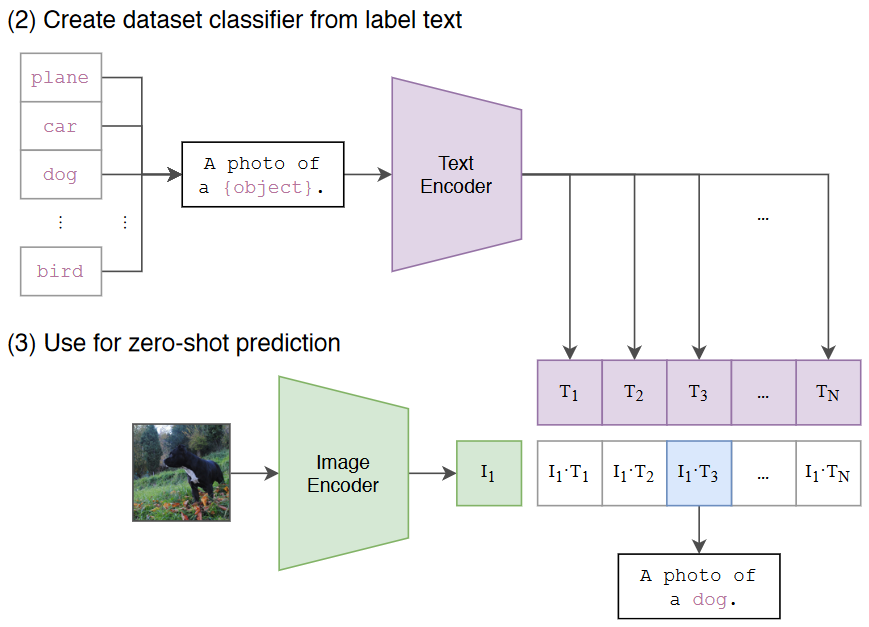
- 生成类别特征:根据所迁移的数据集将所有类别转换为文本。这里以 Imagenet 有 1000 类为例,我们得到了 1000 个文本:
A photo of {label}。我们将这 1000 个文本全部输入 Text Encoder 中,得到 1000 个编码后的向量 , 这被视作文本特征 - 生成图片特征:将需要分类的图像(单张图像)输入 Image Encoder 中,得到这张图像编码后的向量
- 计算余弦相似度:将 与得到的 1000 个文本特征分别计算余弦相似度。找出 1000 个相似度中最大的那一个(上图中对应的为 (),那么评定要分类的图片与第三个文本标签(dog)最匹配,即可将其分类为狗
参考: