VDM
就是原生 DDPM 过程,但是为了处理 3 D 数据,提出一个时空注意力分离的 3 D Unet 网络,最后使用条件引导自回归生成比输入更长帧数
什么是 VDM ?
![]()
- 第一个使用扩散模型进行视频生成任务的论文工作,这里的视频生成任务包括无条件和有条件两种设定
- 针对扩散模型中的 UNet 网络结构进行修改,使其适用于视频生成任务,提出了 3D UNet,该架构使用到了 space-only 3D 卷积和时空分离注意力
- 为了生成比训练时帧数更多的视频,论文还展示了如何使用梯度条件法进行重构指导采样,从而可以自回归地将模型扩展到更长的时间步长和更高的分辨率
VDM 的原理?
![]()
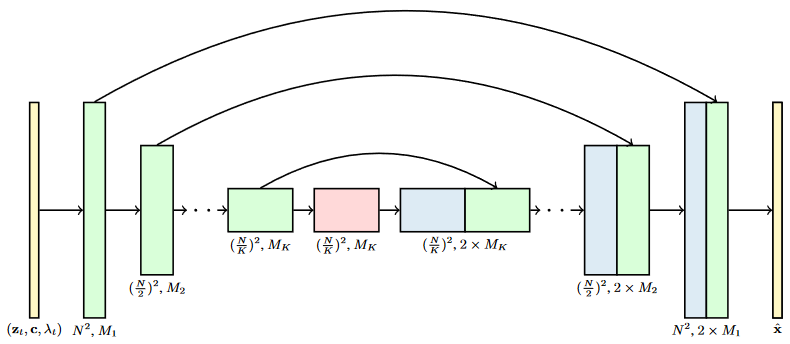
- Video Diffusion Models 提出了 3D UNet 架构。具体来说,该架构将原 UNet 中的 2D 卷积替换成了 space-only 3D 卷积(space-only 3D convolution),举例来说,如果原来用的是 3x3 卷积,那么现在就要把它替换为 1x3x3 卷积(其中第一个维度对应视频帧,即时间维度,第二个和第三个维度对应帧高和帧宽,即空间维度,由于第一个维度是 1 所以对时间没有影响只对空间有影响)
- 随后的空间注意块仍然保留,但只针对空间维度进行注意力操作,也就是把时间维度 flatten 为 batch 维度。在每个空间注意块之后,新插入一个时间注意块(temporal attention block),该时间注意块在第一个维度即时间维度上执行注意力,并将空间维度 flatten 为 batch 维度
- 论文在每个时间注意力块中使用相对位置嵌入(relative position embeddings),以便让网络能够不依赖具体的视频帧时间也能够区分视频帧的顺序。这种先进行空间注意力,再进行时间注意力的方式,可以称为时空分离注意力
比较替换方法和重构引导方法?
![]()
- 修改了扩散模型的采样过程,使用基于梯度优化的方式来改善去噪数据的条件损失,从而可以让生成的视频通过自回归地方式扩展至更长的时间步和更高的分辨率。由于梯度条件法中所使用的附加梯度项可以解释为一种额外的指导,而这种指导其实基于模型对条件数据的重建,因此论文将该方法称为重建引导采样或简单地称为重建指导
- 文章对比了重构引导(reconstruction)和替换引导(replacement)。上图分别展示的是左替换、右重构。替换方法明显的缺乏时间相关性,因为每个帧块都可能来自不同的样本,但重构方法的时间连续性明显更好

参考: