VQ-VAE-2:Generating Diverse High-Fidelity Images with VQ-VAE-2
VQ-VAE 因在潜在表示空间使用自回归神经网络,捕捉到了更多的结构化的全局关联信息;VQ-VAE-2
将顶层全局与底层局部信息分离开来,生成全局自洽,局部高清的图像
(图 A->z)->z’ (离散化)-> 图 A’,随机图片
什么是 VQ-VAE-2 ?
![]()
- 使用多层的 VQ-VAE,生成更高清晰度的图片
- VQ-VAE 因在潜在表示空间使用自回归神经网络,捕捉到了更多的结构化的全局关联信息;VQ-VAE-2 将顶层全局与底层局部信息分离开来,生成全局自洽,局部高清的图像

VQ-VAE-2 的网络结构?
![]()
- VQ-VAE-2 是两层的 VQ-VAE,其中上层潜在空间 32 x 32, 下层潜在空间大小 64 x 64。上层首先进行分层量子化,得到量子化后的字典向量
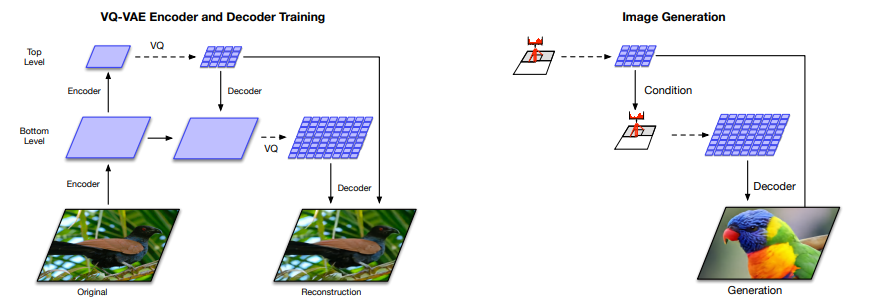
- 训练时:使用上层量化 作为条件,与输入 x 一起,计算下层潜在空间的量子化形式。最后将上层和下层量子化选中的字典向量 和 同时输入解码器,计算之前定义的损失函数,更新编码解码网络,以及字典向量的权重
- 推理时:自定义输入,依次查询上层 codebook 和下层 codebook,最后使用解码器生成图片
VQ-VAE-2 与 VQ-VAE 的区别?
- VQ-VAE 因在潜在表示空间使用自回归神经网络,捕捉到了更多的结构化的全局关联信息
- VQ-VAE-2 将顶层全局与底层局部信息分离开来,生成全局自洽,局部高清的图像
- 两者的目的都是训练 Encoder + VQ + Decoder 其实就是在寻找隐空间,找到隐空间之后,在隐空间上训练 PixelCNN 自回归模型做生成
参考: