和 AE 生成样本的过程类似,但是引入对隐变量的约束,利用高斯混合模型 (GMM) 的概念去逼近真实样本的分布
什么是 VAE ?
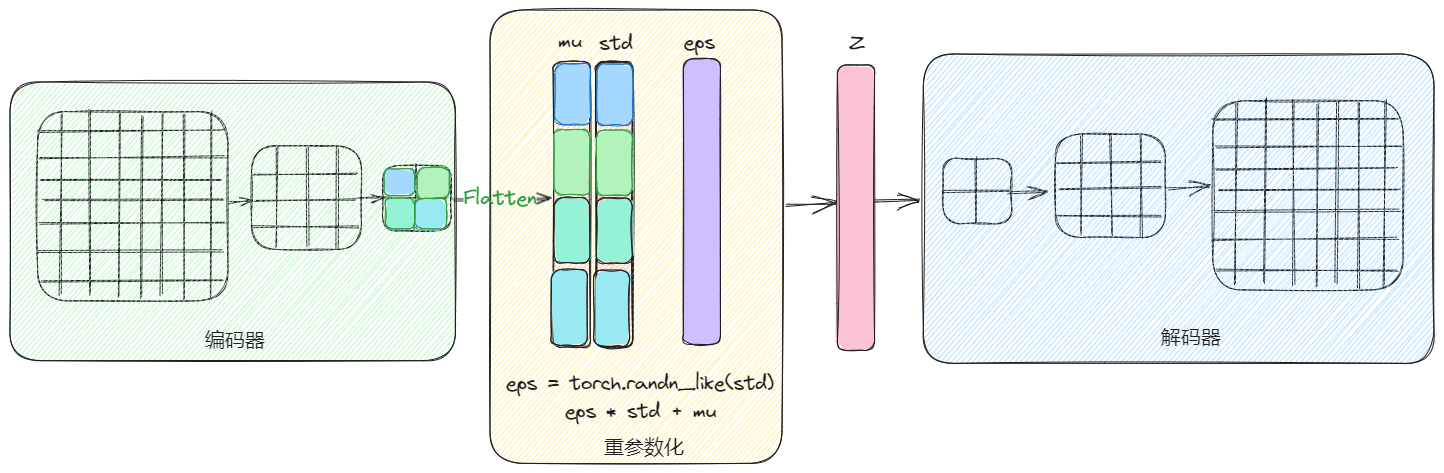
![Drawing-20230926091932.excalidraw]()
- 假设我们有一批样本数据 {X1,X1,...,Xn},类似全概率公式,生成模型的本质是为了得到等于或靠近分布 p (X),如果能得到这个分布,输入任意随机变量就可以生成样本,但是这是不可能的。于是将分布改
p(X)=Z∑p(X∣Z)p(Z)
- 也就是通过另一个随机变量 Z 去生成 X,并且假设 p(Z)=N(0,I),也就是先从标准正态分布采样一个 Z,然后根据 Z 去算 X
- 上图是先由 X 生成隐变量,然后通过采样方差和均值,生成服从正太分布的 Z,即通过多组正太分布的组合去逼近 X 的真实分布,这里使用了高斯混合模型 (GMM) 的概念
VAE 的重参数化技巧?
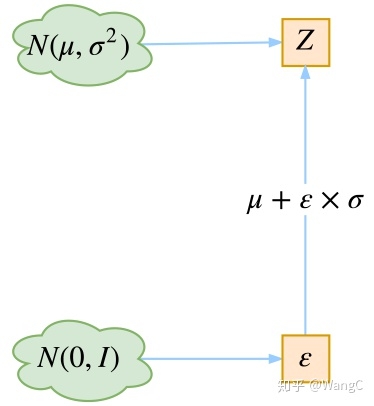
![]()
- 若希望从高斯分布 N(μ,σ2) 中采样,可以先从标准分布 N(0,1) 采样出 z ,再得到 σ∗z+μ,这就是我们想要采样的结果。这样做的好处是将随机性转移到了 z 这个常量上,而 σ 和 μ 则当作仿射变换网络的一部分
- 同样 VAE 已知正态分布采样得到隐变量 Z,但是直接采样无法实现梯度反向传播的,因此因此不通过 y∼N(μ,σ2) 采样,而是使用 ϵ∼N(0,1)
1
2
3
4
5
6
|
def noise_reparameterize(mean,logvar):
eps = torch.randn(mean.shape).to(device)
z = mean + eps * torch.exp(logvar)
return z
|
VAE 的损失函数?
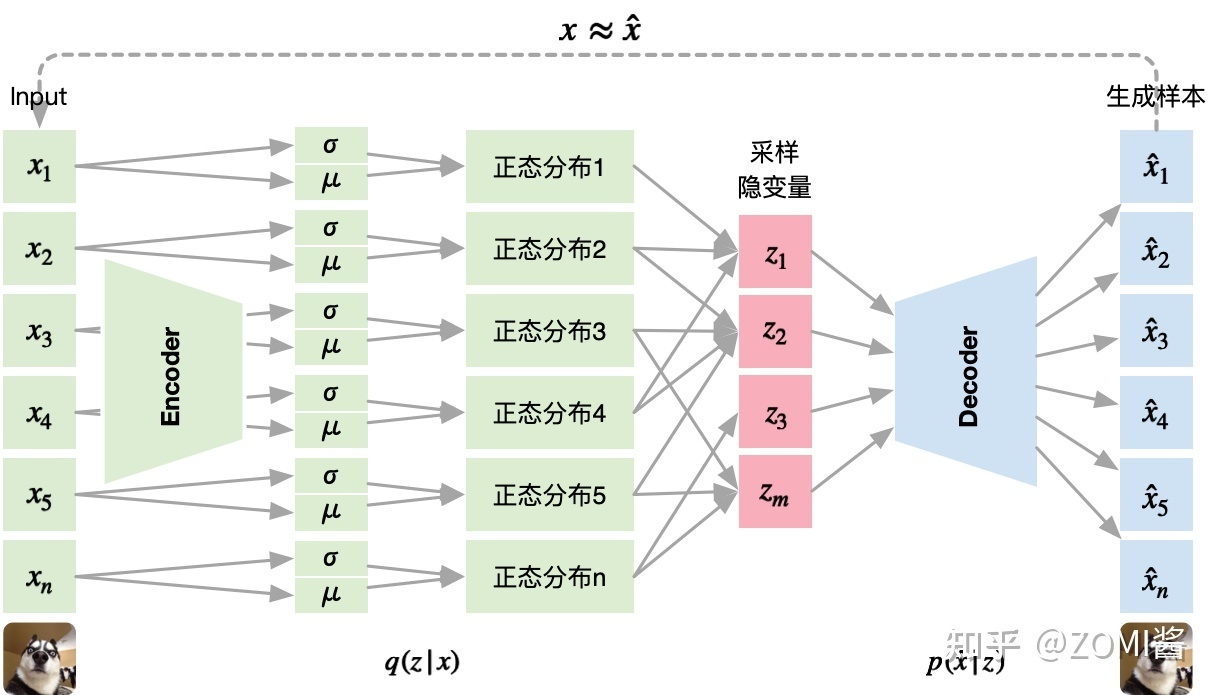
![]()
- (1) 已知模型输出分布计算如下:对 latency space 随机采样 m 个点,其中 m 服从多项式分布p(x),每采样一个点 m,将其对应到一个高斯分布N(μm,σm),于是一个多项式分布利用高斯混合模型 GMM 可以表示
p(x)=m∑p(m)p(x∣m)=∫zp(z)p(x∣z)dz
Maxinumlogp(x)=∫zq(z∣x)logp(x)dz=∫zq(z∣x)log(p(z∣x)p(z,x))dz=∫zq(z∣x)log(q(z∣x)p(z,x)p(z∣x)q(z∣x))dz=∫zq(z∣x)log(q(z∣x)p(z,x))dz+∫zq(z∣x)log(p(z∣x)q(z∣x))dz=∫zq(z∣x)log(q(z∣x)p(z,x))dz+KL(q(z∣x)∥p(z∣x))(4)
- (3) 损失的下确界:公式右边的 KL 散度是一个 >=0 的部分,于是logp(x) 的下确界由以上公式的左边定义,
logp(x)≥∫zq(z∣x)log(q(z∣x)p(x∣z)p(z))dz
- (4) 下确界分析:由下确界的定义可知,最大化logp(x) 等价于最大化下确界,
Lb=∫zq(z∣x)log(P(z∣x)P(z,x))dz=∫zq(z∣x)log(q(z∣x)P(x∣z)P(z))dz=∫zq(z∣x)log(q(z∣x)P(z))dz+∫zq(z∣x)logP(x∣z)dz=−KL(q(z∣x)∥P(z))+∫zq(z∣x)logP(x∣z)dz
- (5) 损失分析:以上公式左边是一个 KL 散度,表示的是生成的隐变量分布和隐变量先验分布的差距,其实就是生成的隐变量分布和标准正太分布的差距,由于是负值,所以需要最小化 KL 散度,也即隐变量分布和标准正太分布越接近越好。等式右边是重建损失,表示期望 Encoder 输出q(z∣x) 的情况下 Decoder 输出 p (x|z) 尽可能的大。即需要从编码器 Encoder 得到的隐变量空间中采样隐变量 z,对采样得到的隐变量 z 进行解码 Decoder,使得解码得到的x^ 分布中,对应是输入 x 的概率尽可能
Maximum∫zq(z∣x)logp(x∣z)dz=MaximumEq(z∣x)[logp(x∣z)]
- 总的来说,VAE 以最大化对数似然的下界(Evidence Lower Bound,ELBO) 为目的,通过 KL 散度和重建损失完成模型的训练
VAE 与 AE 的区别?
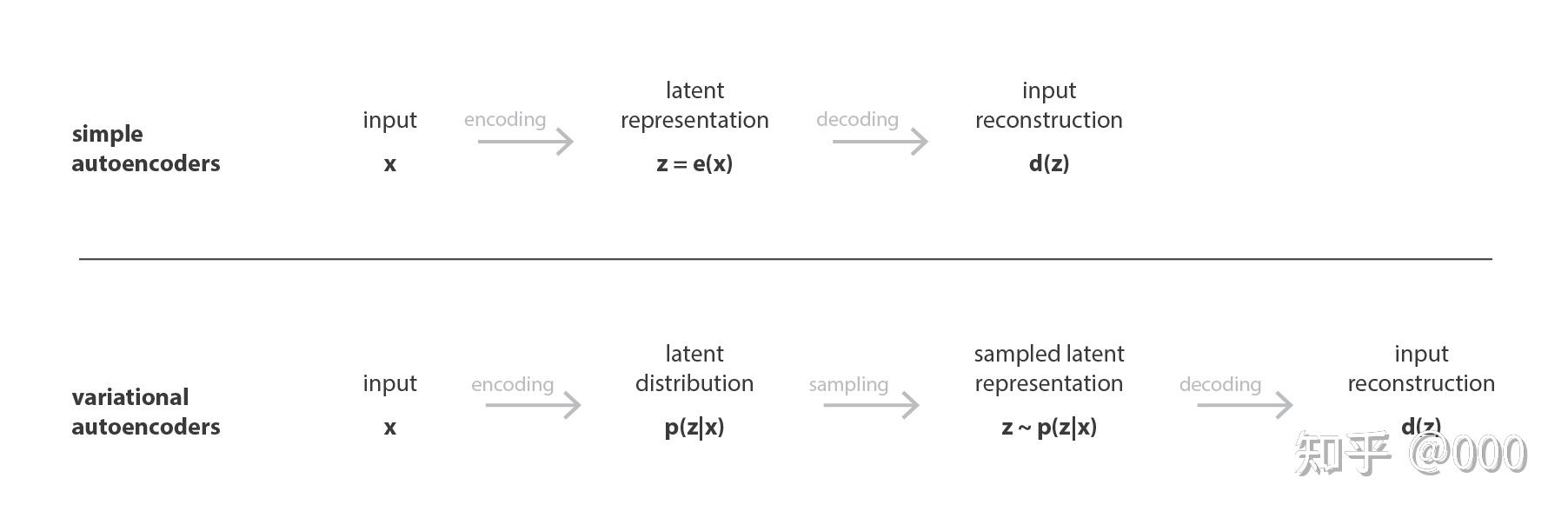
![]()
- 与自编码器是直接生成确定隐变量 z 不同,在 VAE 中,encoder 输出隐向量 z 的分布的均值 μ 与标准差 σ,再从这个分布中采样得到隐向量 z。
- 换句话说,AE 将输入 encode 成隐空间里的单个点,而 VAE 则是将输入 encode 成隐空间里的分布 (distribution)
- AE 更容易过拟合训练过的数据,对没见过的数据生成效果差。而 VAE 直接学习原始数据隐空间的分布,其隐变量鲁棒性更强
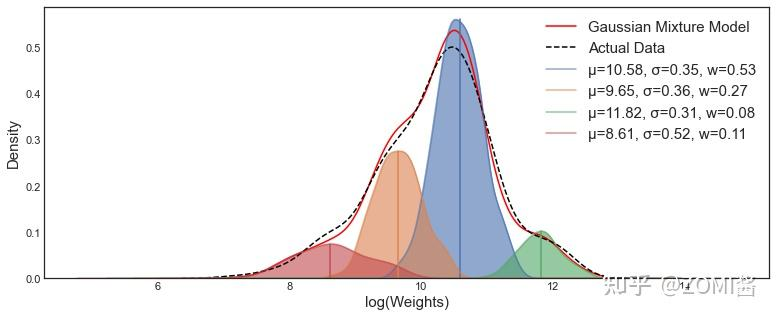
什么是高斯混合模型 GMM?
![]()
- 一种聚类算法,通过多个高斯分布函数的线性组合,理论上可以逼近任意类型的分布。上图虚线是真实分布,红线是通过 4 个高斯分布拟合出来的曲线,可以看出很接近真实分布
- GMM 一般使用 EM 优化算法去估计参数的隐变量 Z
参考:
- VAE: 学习高维数据分布 - 知乎
- 生成模型 | VAE | 原理 | 实现 - 知乎
- GAN 和 VAE 的本质区别是什么?为什么两者总是同时被提起? - 知乎
- Variational AutoEncoder, and a bit KL Divergence, with PyTorch | by Tingsong Ou | Medium
- Fetching Title#im00
- AE, VAE, VQ-VAE, VQ-VAE-2 - 知乎
- DDPM 解读(一)| 数学基础,扩散与逆扩散过程和训练推理方法 - 知乎