StyleGAN
StyleGAN 通过映射网络解决 “特征纠缠” 问题,通过向不同网络层输入噪声,控制不同层次的特征,比如可以实现单独控制头发的功能
什么是 StyleGAN ?
- StyleGAN 是 ProGAN 的升级版本,StyleGAN 观察到 ProGAN 渐进层的一个潜在好处是,如果使用得当,它们能够控制图像的不同视觉特征。图层(和分辨率)越低,其影响的特征越粗糙
- 粗 - 分辨率高达 8 * 8:影响姿势、一般发型、面部形状等
- 中等 - 分辨率 16 * 16 到 32 * 32:影响更精细的面部特征、发型、睁眼 / 闭眼等
- 精细 - 分辨率为 64 * 64 到 1024 * 1024:影响配色方案(眼睛、头发和皮肤)和微观特征
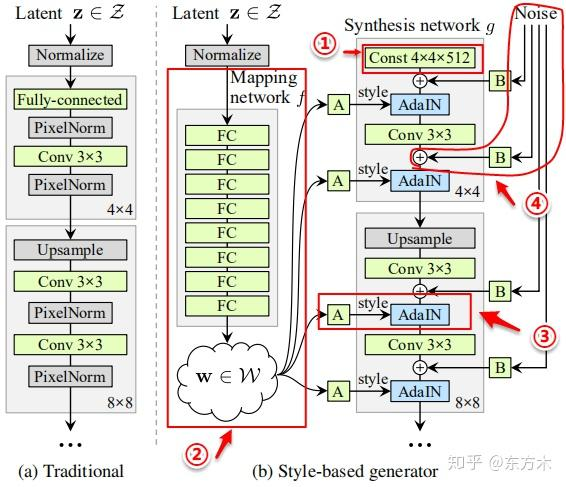
StyleGAN 的网络结构?
![]()
- 移除了传统的输入:传统的生成器 a)使用 latent code(随机输入)作为生成器的初始输入;StyleGAN 抛弃了这种设计,将一个可学习的常数作为生成器的初始输入
- 映射网络 (Mapping network):映射网络由 8 个全连接层组成,其输出 w 与输入 z 大小相同 (512×1)。映射网络的目标是将输入向量编码为中间向量,中间向量 W 的不同元素控制不同的视觉特征
- 综合网络 (Synthesis):W 通过每个卷积层的 AdaIN 输入到生成器的每一层中
- Noise:通过加入噪声为生成器生成随机细节
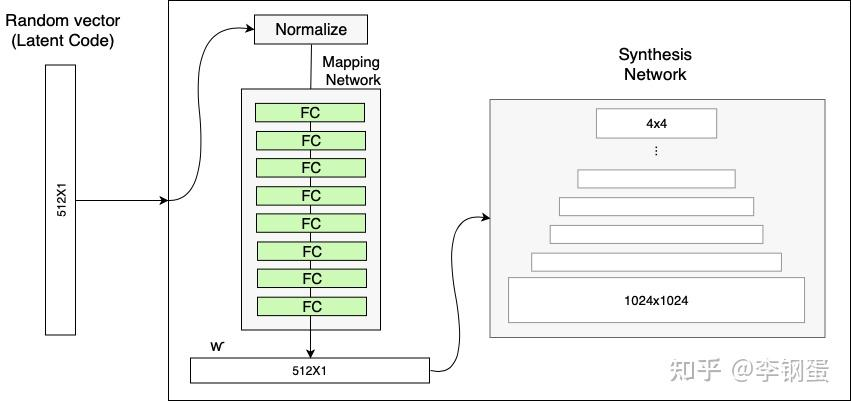
StyleGAN 的 “特征纠缠”?
![]()
- 使用输入向量控制视觉特征的能力是有限的,因为它必须遵循训练数据的概率密度。例如,如果黑发人的图像在数据集中更常见,则更多输入值将映射到该特征。因此,该模型无法将部分输入(向量中的元素)映射到特征,这种现象称为特征纠缠
- 通过使用另一个神经网络,该模型可以生成一个不必遵循训练数据分布的向量,并且可以减少特征之间的相关性。映射网络由 8 个完全连接的层组成,其输出与输入层的大小纬度相同(512×1)
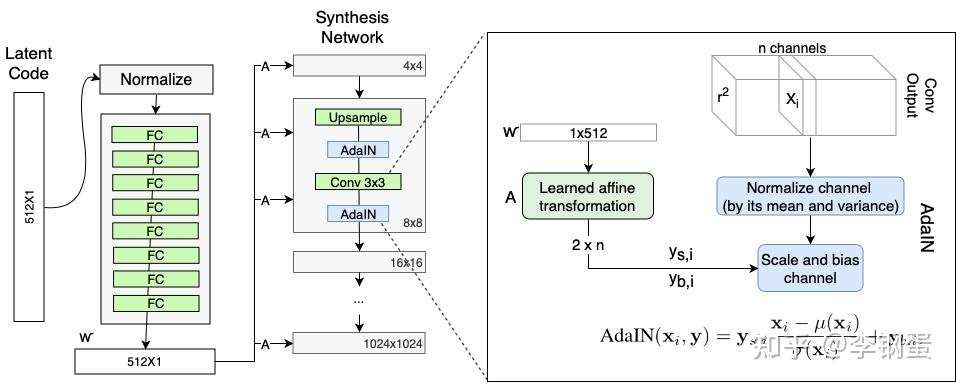
StyleGAN 的 Style 模块?
![]()
- AdaIN(自适应实例规范化)模块传输由映射网络创建的编码信息ⱳ, 进入生成的图像。该模块被添加到合成网络的每个分辨率级别,并定义该级别中特征的视觉表达
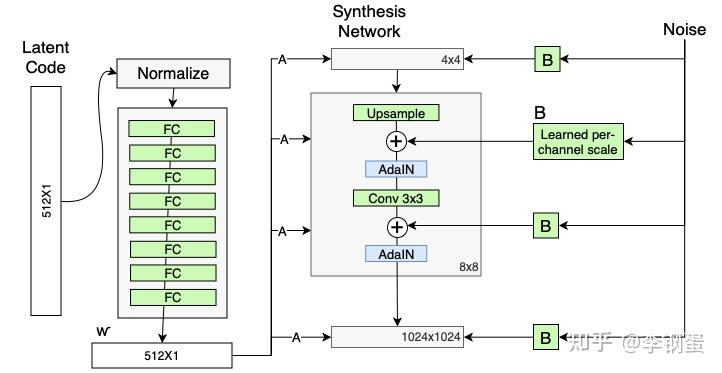
StyleGAN 的随机变异?
![]()
- 人的脸有很多的特征都很小且可以看作是随机的,例如雀斑、头发的精确位置、皱纹等,这些可以使图像更逼真的,并增加输出的多样性。将这些小特征插入 GAN 图像的常用方法是向输入向量添加随机噪声。然而,在许多情况下,由于上述特征纠缠现象,很难控制噪声效果,这会导致图像的其他特征受到影响
- StyleGAN 中的噪声以与 AdaIN 机制类似的方式添加,即在 AdaIN 模块之前向每个通道添加控制缩放的噪声,并稍微改变其操作分辨率级别特征的视觉表达
参考: