PP-YOLOE
基于 YOLOv 5 提出的更适合工业场景的目标检测模型,主要改进是使用 anchor-free,使用类别、定位一致的检测头
基于 YOLOv 5 提出的更适合工业场景的目标检测模型,主要改进是使用 anchor-free,使用类别、定位一致的检测头
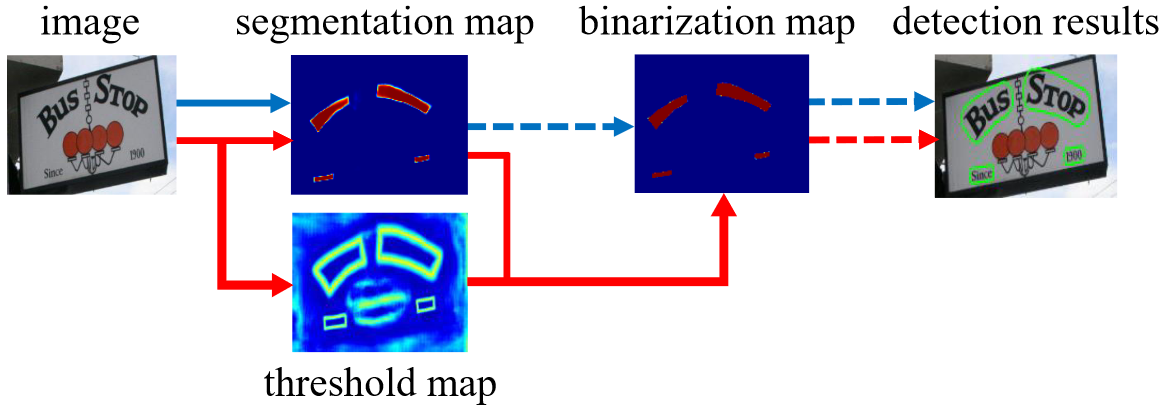
本文介绍两个文本检测模型: DB 及它的升级版本 DB++,主要的原理就是将 “二值化” 的过程做成网络可学习、可微分的一个模块,然后向网络中插入这个模块自适应去学习二值化阈值,最终预测文字区域的一个核心部分,然后再通过公式放大这个核心部分,得到目标区域
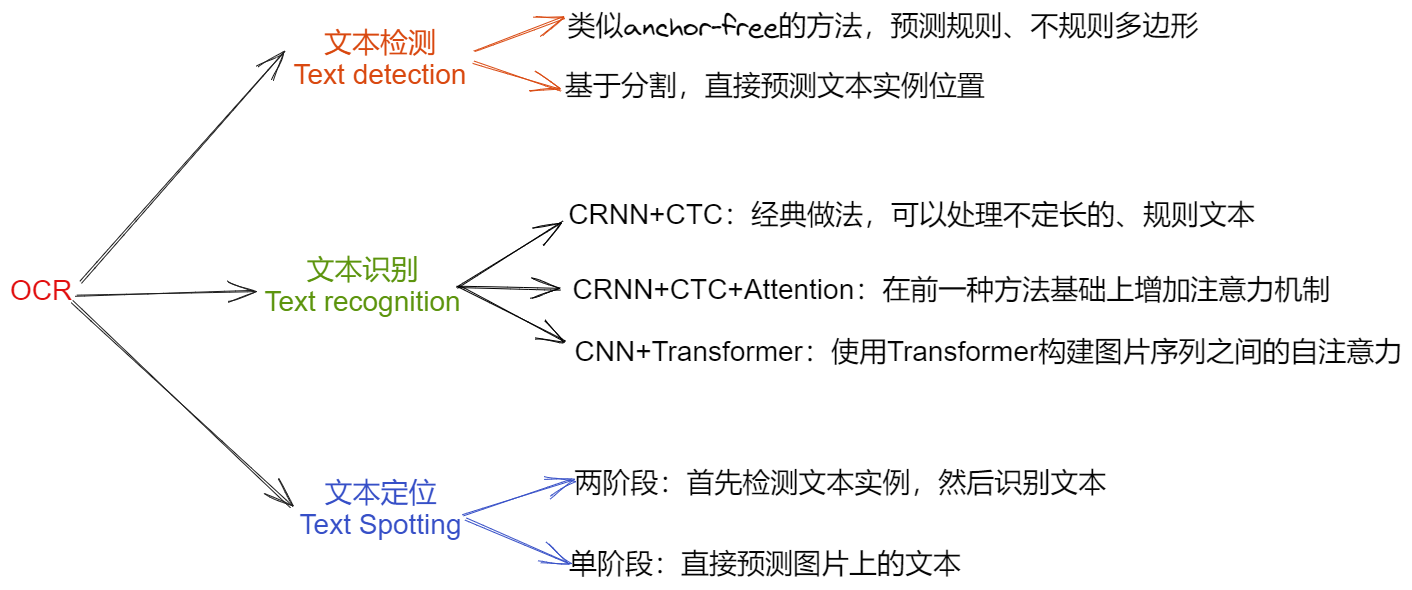
本文总结自己目前对 OCR 的认识,和学习过程
传统的文本识别算法是 CNN+RNN,但是由于 LSTM 的效率较低,很多移动设备对 LSTM 的加速效果并不好,所以在实际的应用场景中也存在诸多限制,SVTR 利用 swin transformer 替代构建局部和全局混合块,提取多尺度的特征,使得不需要 RNN 去构建序列依赖也能实现更好的效果
本文是 OCR 的样本生成模型,包括风格迁移模块、前景文字去除模块及融合模块,其中风格迁移模块目地是将文本按照目标风格渲染出来,前景文字去除模块用于去掉目标图片上的文字,融合模块用于融合目标文本和目标背景
属于 EAST 的演进版本,还是类似 anchor-free 的方式预测文本行,除了输出 grid 的 score + 边框预测外,还输出更多的文本实例信息,比如 grid 到实例矩形四角、中心点、四边的距离,使得 SAST 可以检测弯曲文本行、中间有间隔的文本行
onnxruntime 运行原理及步骤

第一个端到端解决文本识别的模型,相比较两阶段的文本定位方法,它的检测速度更快,基本思路是通过文本检测分支实现文本行区域的提取,然后通过 RoIRotate 模块实现文本行的 “摆正”,最后使用 CRNN+CTC 的模式实现文本行的字符识别
本文研究为什么残差网络 ResNet 可以构建深层网络的原因,提出残差网络不同于以前 “串式” 网络结构的视觉模型,其分层提取特征的概念不在 ResNet 中体现,因为:(1) 删除任意一层,对效果影响不大:比较 VGG 删除任意一层和 ResNet 删除任意一层,ResNet 仅删除下采样模块性能变差明显,说明残差网络层之间不是相互依赖的;(2) 随机删除 ResNet 的任意数量模块:性能平滑变差,说明残差网络的层表现出整体现象;(3) 随机打乱残差网络的层顺序:性能平滑变差,说明残差网络可以在运行时配置网络;(4)梯度贡献在短路径上:在训练期间贡献梯度通过网络的路径比预期的要短。事实上,训练期间不需要深路径,因为它们不提供任何梯度