本文是 OCR 的样本生成模型,包括风格迁移模块、前景文字去除模块及融合模块,其中风格迁移模块目地是将文本按照目标风格渲染出来,前景文字去除模块用于去掉目标图片上的文字,融合模块用于融合目标文本和目标背景
什么是 SRNet ?
![]()
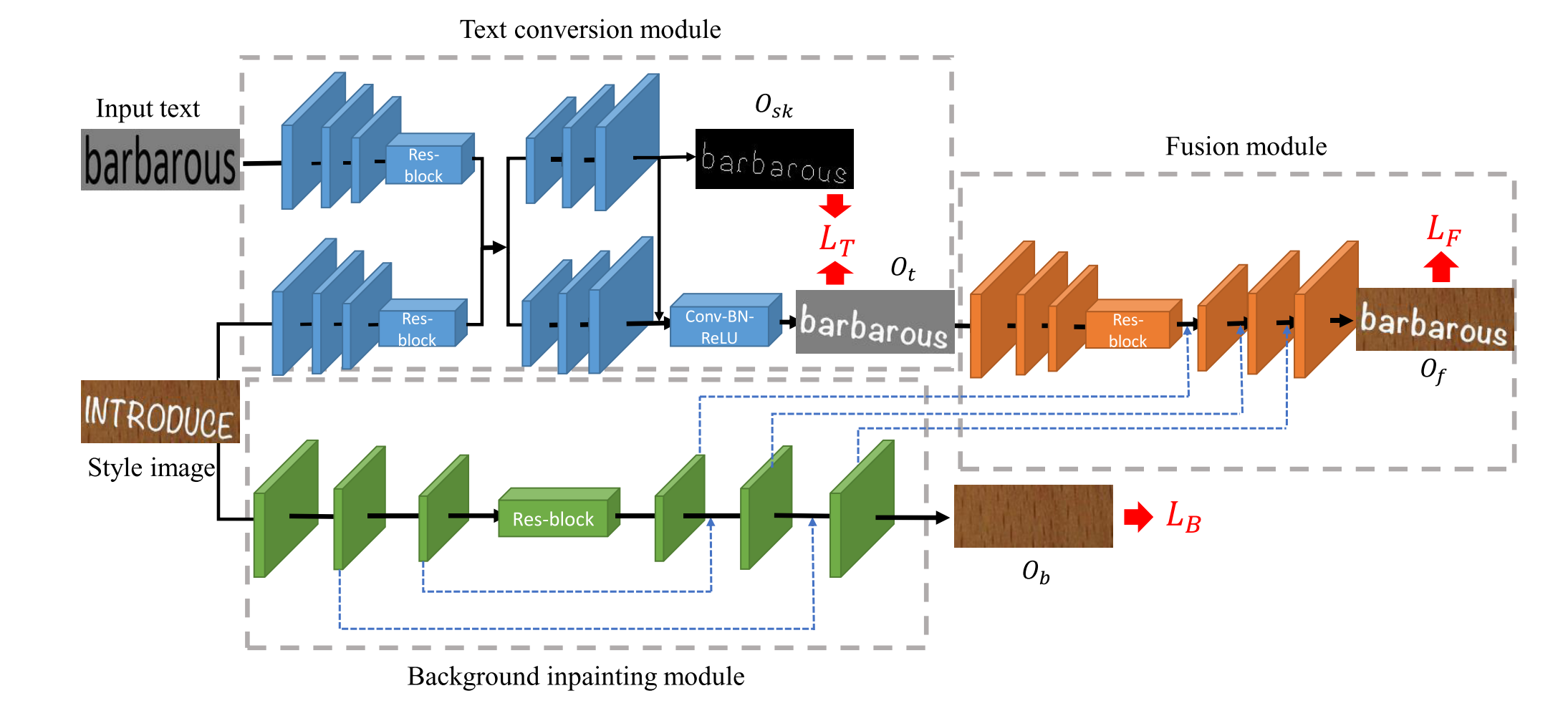
- SRNet 是一个利用 GAN 网络完成风格迁移的网络,利用该网络可以将文字按照目标图片的风格渲染到目标图片上
- 其核心包括 3 部分:(1)文本风格转换模块;(2)背景修复模块;(3)融合模块
SRNet 的网络结构?
![]()
- 文本风格转换模块:完成文本 + 目标图片 => 按照目标图片文字风格的图片,此时图片还没有背景
- 背景修复模块:目标图片 => 去掉文字的图片,相当于完成目标背景的提取
- 融合模块:目标风格的文字 + 目标背景 => 文字迁移到新背景上,并且文字风格类似
SRNet 的训练?
![]()
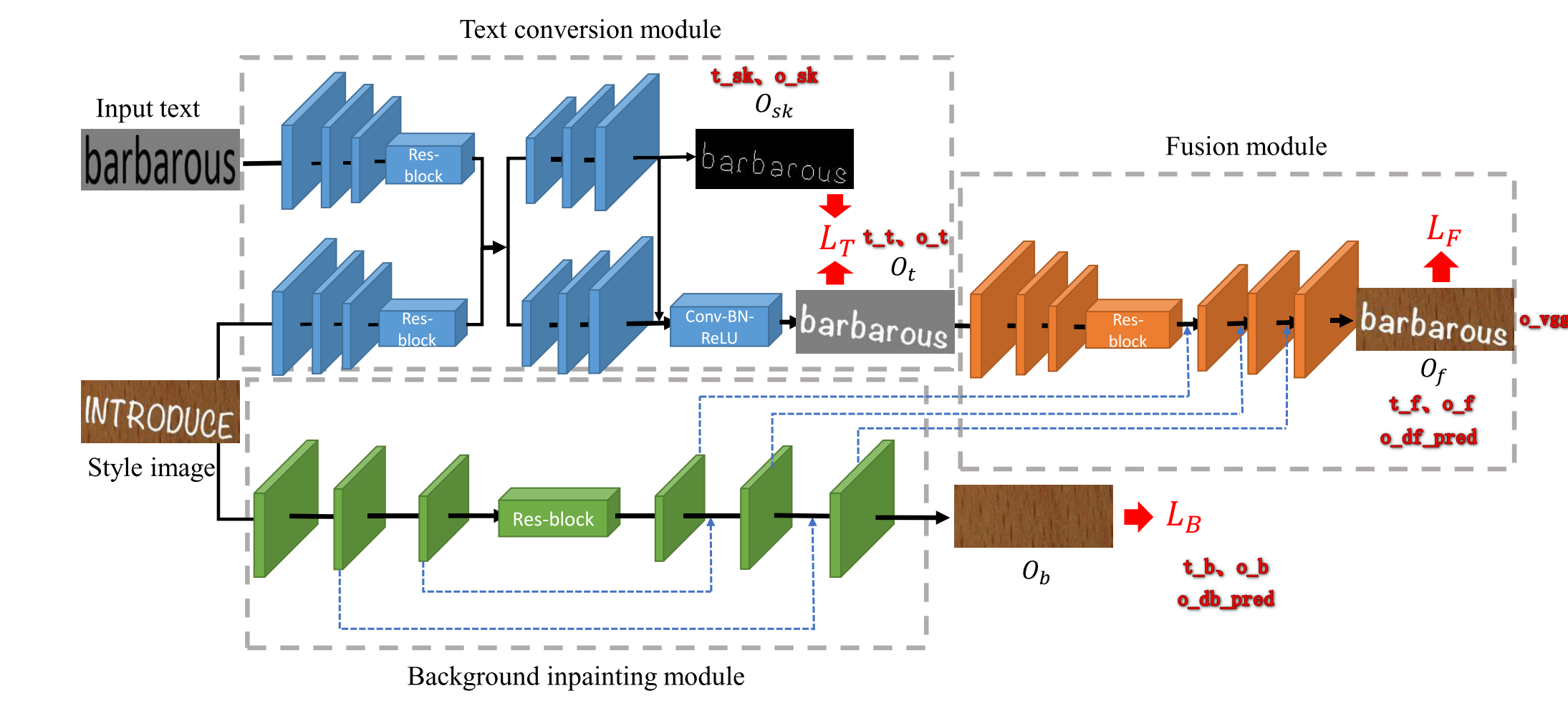
- SRNet 借鉴 GAN 的训练方式,即通过训练
Discriminator-Generator 完成训练 - Discriminator 训练目地是区分真实样本和生成样本,所以分别在Ob、Of使用两个生成器训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| i_db_true = torch.cat((t_b, i_s), dim = 1)
i_db_pred = torch.cat((o_b, i_s), dim = 1)
i_df_true = torch.cat((t_f, i_t), dim = 1)
i_df_pred = torch.cat((o_f, i_t), dim = 1)
o_db_true = D1(i_db_true)
o_db_pred = D1(i_db_pred)
o_df_true = D2(i_df_true)
o_df_pred = D2(i_df_pred)
db_loss = build_discriminator_loss(o_db_true, o_db_pred)
df_loss = build_discriminator_loss(o_df_true, o_df_pred)
|
- Generator 训练目地是使得生成样本更接近真实样本,所以在osk、ot、ob、of四个位置计算损失,并且使用不参与训练的 VGG 计算of与tf,目地是计算真实图片和目标图片在多尺度下风格、内容的一致性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
l_t_sk = build_dice_loss(t_sk, o_sk)
l_t_l1 = build_l1_loss(t_t, o_t)
l_t = l_t_l1 + l_t_sk
l_b_gan = build_gan_loss(o_db_pred)
l_b_l1 = build_l1_loss(t_b, o_b)
l_b = l_b_gan + l_b_l1
l_f_gan = build_gan_loss(o_df_pred)
l_f_l1 = build_l1_loss(t_f, o_f)
l_f_vgg_per, l_f_vgg_style = build_vgg_loss(o_vgg)
l_f = l_f_gan + l_f_vgg_per + l_f_vgg_style + l_f_l1
loss = cfg.lt * l_t + cfg.lb * l_b + cfg.lf * l_f
|
参考:
- 读论文 ——(Styletext)Editing Text in the Wild-CSDN 博客