SAST:A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning
属于 EAST 的演进版本,还是类似 anchor-free 的方式预测文本行,除了输出 grid 的 score + 边框预测外,还输出更多的文本实例信息,比如 grid 到实例矩形四角、中心点、四边的距离,使得 SAST 可以检测弯曲文本行、中间有间隔的文本行
什么是 SAST ?
![]()
- 属于 EAST 的演进版本,还是类似 anchor-free 的方式预测文本行,但是除了输出 grid 的 score + 边框预测外,还输出更多的文本实例信息,比如 grid 到实例矩形四角、中心点、四边的距离
- 每个 grid 更加复杂的输出,可以让 SAST 检测更为复杂场景下的文本行,比如弯曲文本行、中间有间隔的文本行
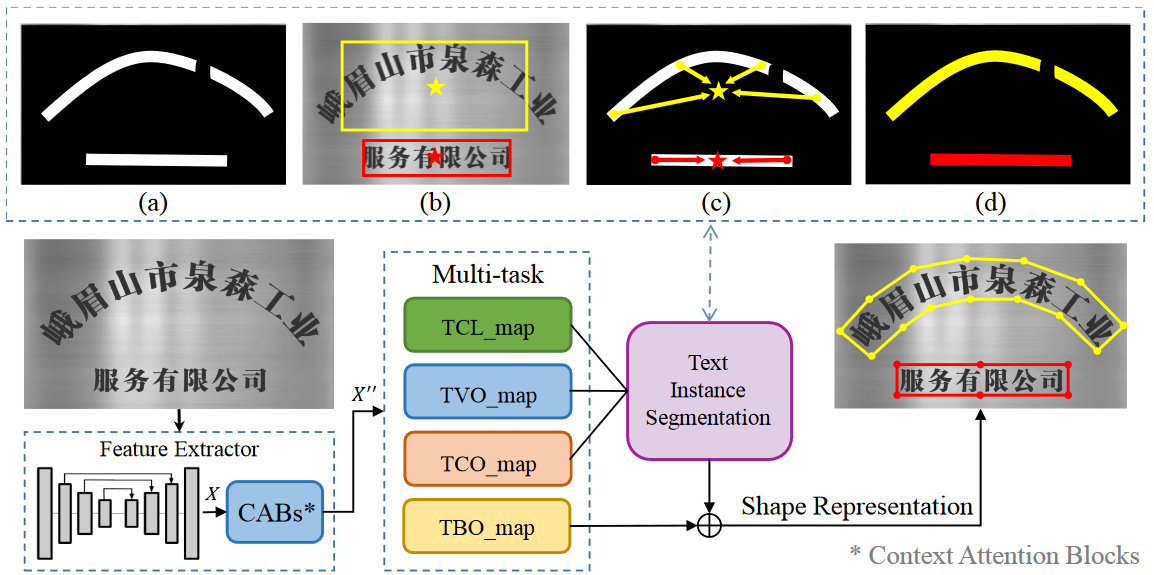
SAST 的网络结构?
![]()
- Featrue Extractor:BackBone 部分,通过类似 SegNet 的过程提取特征
- CABs:交叉注意力模块,用于整合 BackBone 的特征
- TCL map (1 xHxW): grid 属于文本中心线像素点的概率
- TCO map (2 xHxW): 文本中心点偏置,grid 距其所属的文本实例矩形框中心的 xy 方向距离
- TVO map (8 xHxW): 文本四顶点偏置,grid 距其所属的文本实例矩形框四顶点的 xy 方向距离
- TBO map (4 xHxW): 文本边界偏置,grid 距其所属的文本实例上下边界框的 xy 方向距离
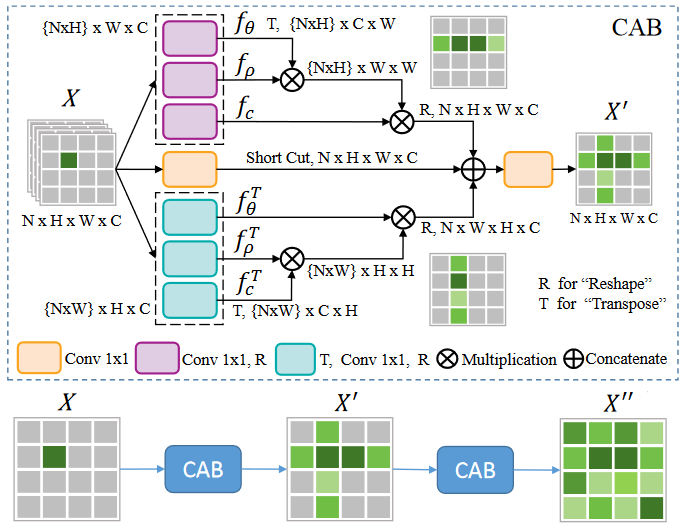
SAST 的 CAB 模块?
![]()
- 交叉注意力模块,用于整合 BackBone 的特征,该模块分为上下两部分,上部分构建水平方向注意力,下部分构建垂直方向注意力,整合水平方向注意力和垂直方向注意力得到全局注意力
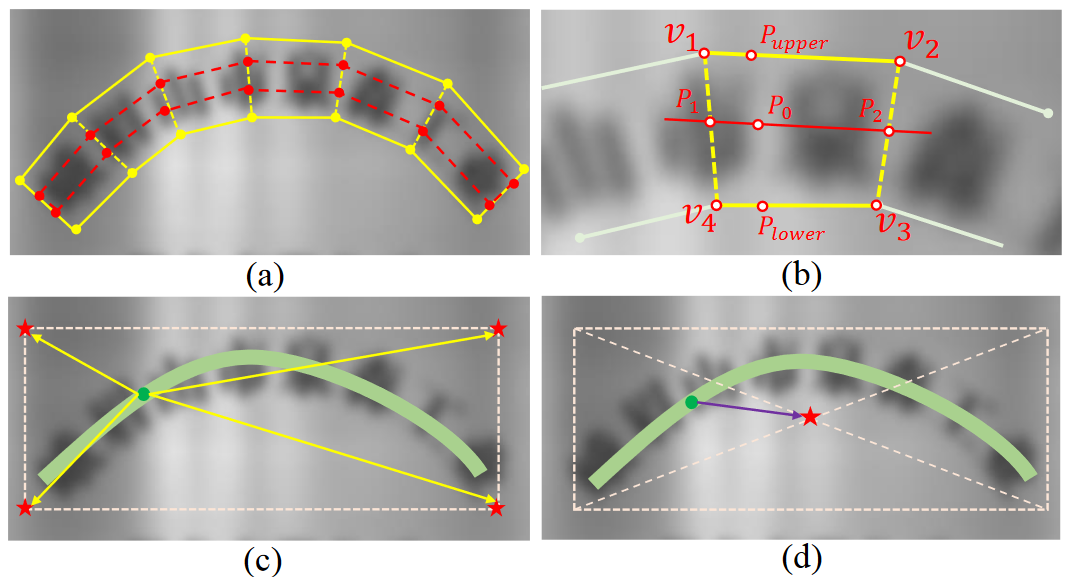
SAST 样本制作?
![]()
- a). TCL map (1 xHxW):文本中心线区域,文本行上下边界收缩 20% 后得到的区域,而左右边界仍保持不变
- b). TBO map (4 xHxW):文本边界偏置,首先计算斜率 k 1 (v 1, v 2) 与斜率 k 1 (v 4, v 3) 的平均值,对于一个给定的点 P 0,可容易地计算出斜率为 (k 1+k 2)/2、过点 P 0 的直线,由此该直线与线段 (v 1, v 4) 和线段 (v 2, v 3) 的交点 P 1 与 P 2 很容易得出,故 P 0 的上下边界点 和 的坐标可由线段比例关系得到,整理得到 P 0 点到四边距离的 TBO 为 {, ,,}
- c). TVO map (8 xHxW):文本顶点偏置,文本最小矩形框按根据一定规则由文本标注信息计算得到,计算文本中心区域中某像素点到文本矩形框四顶点的直线距离(包括 x 方向和 y 方向),所以共计给每个 grid 生成 8 个 TVO 预测
- d). TCO map (2 xHxW):文本中心点偏置,计算文本中心区域内某像素点到文本最小矩形框中心点的距离 (x 方向和 y 方向)
SAST 的损失函数?
- (1) TCL map: 使用 Minimizing the Dice loss 作为分割 loss, 用于描述两个轮廓的相似程度
- (2) TVO/TCO/TBO: 使用 Smooth L 1 Loss 作为几何图 geometry map 的回归 loss
解析 SAST 的输出 1 - 生成文本实例?
![]()
- a) 根据 TCL 获得文本实例包含的像素点 -> 文本行 Mask,阈值过滤将置信率低于某值的假阳性像素点剔除,得到合适的 TCL map;
- b) 根据 TVO+NMS 获得文本实例 -> 文本矩形框:将经过处理的 TCL map 中每个像素点,根据 TVO 文本实例顶点偏置图,得到对应的文本矩形框四顶点坐标,并进行非最大值抑制 NMS,得到所需的文本实例矩形框及其中心点
- b+c=d) 根据 TCO 合并文本实例 -> 文本行 Mask :计算 TCL 中属于文本的像素点的所属文本实例的几何中心点,该中心点将作为低层级像素信息,当步骤 c 计算所得的几何中心点与步骤 b 所得矩形框中心点重合或相近时,该像素点将被归类给步骤 b 中矩形框对应的文本实例,通过此步骤重新合并断开的文本行
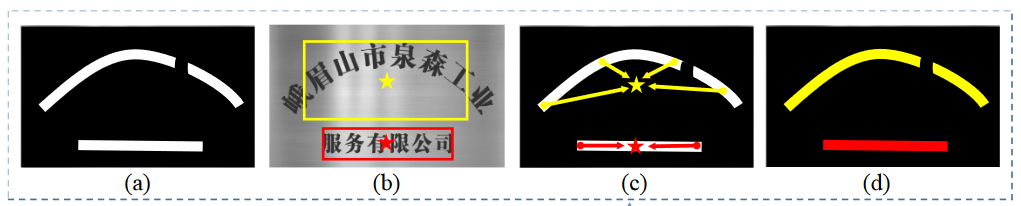
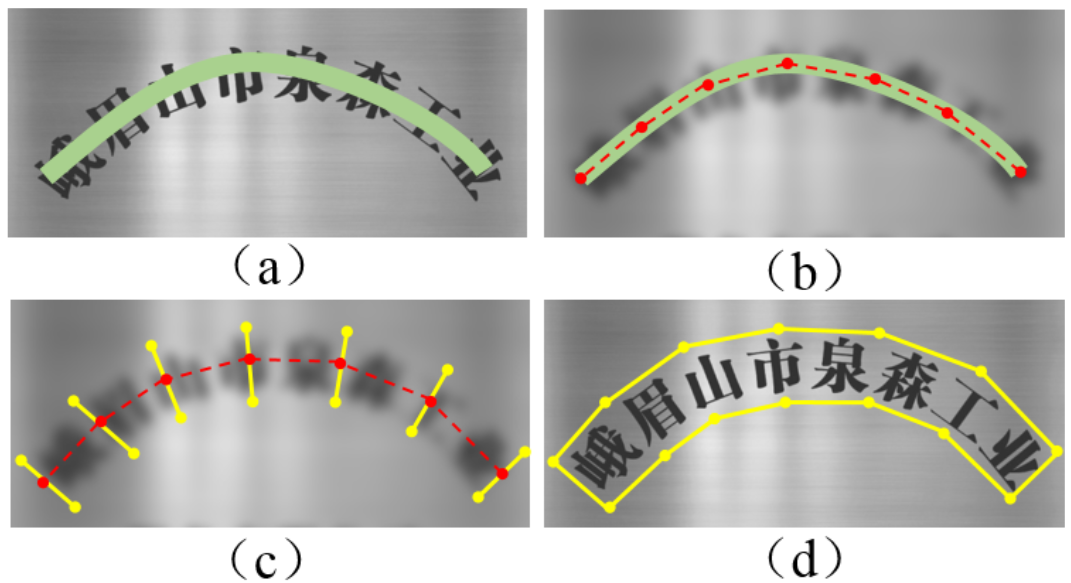
解析 SAST 的输出 2 - 生成文本边框?
![]()
- a) 前面解析得到的文本实例
- b) 对文本中心线采样,采样点的间距相同,则得到的采样点数目与文本线的长度有关,故称之为自适应采样
- c) 根据文本边界偏置图 TBO 所提供的信息,计算文本中心线的采样点上的上下边界定位点
- d) 将步骤 b 所得的边界定位点按照从左上角开始的顺时针方向依次进行连接,得到最终的文本边界框
参考: