ONNXRuntime
onnxruntime 运行原理及步骤
使用 ONNX 常见的使用路线?
- Pytorch -> ONNX -> TensorRT
- Pytorch -> ONNX -> TVM
- TF –> ONNX –> ncnn
- Pytorch -> ONNX -> tensorflow
- Pytorch -> ONNX -> ONNX Runtime
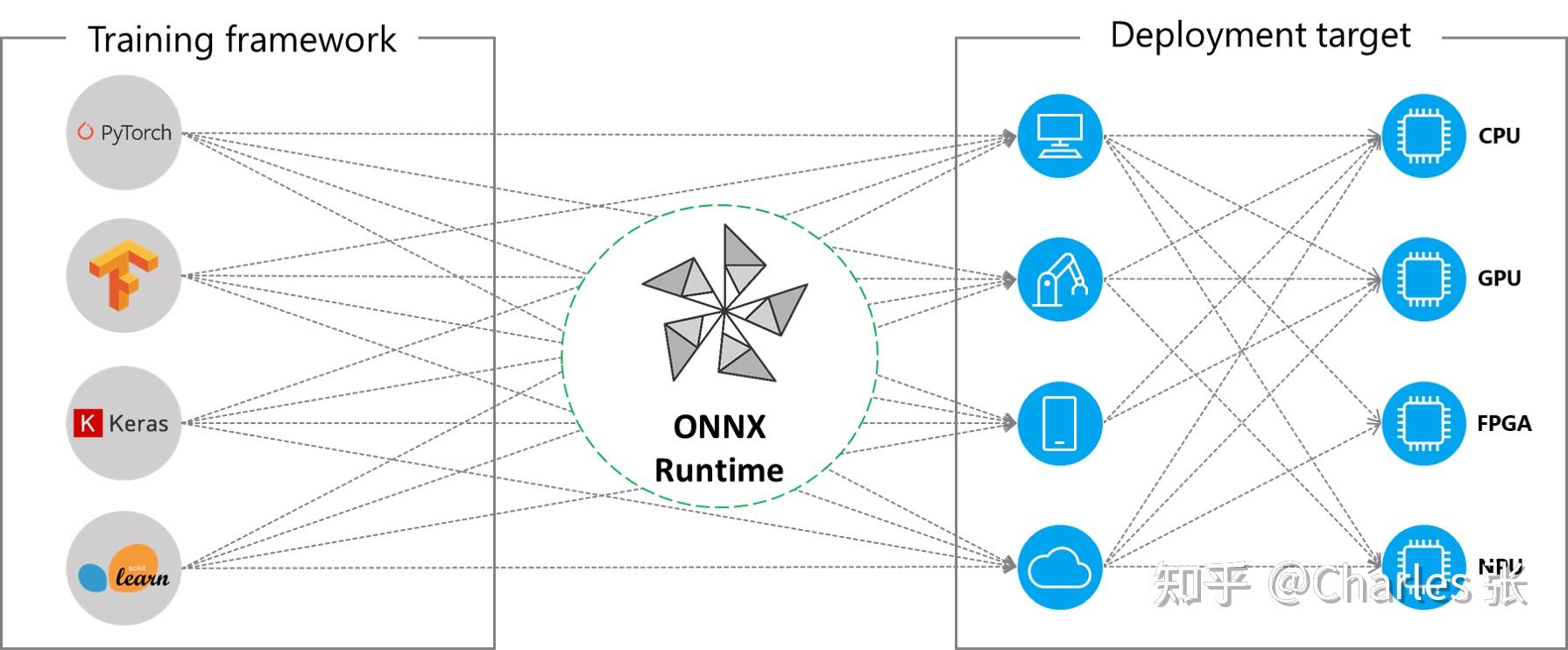
什么是 ONNX Runtime?
![]()
- ONNX Runtime 是由微软维护的一个跨平台机器学习推理加速器,它直接对接 ONNX,可以直接读取.onnx 文件并实现推理,不需要再把 .onnx 格式的文件转换成其他格式的文件
- 适用于 Linux、Windows 和 Mac。编写 C++,它还具有 C、Python 和 C# api
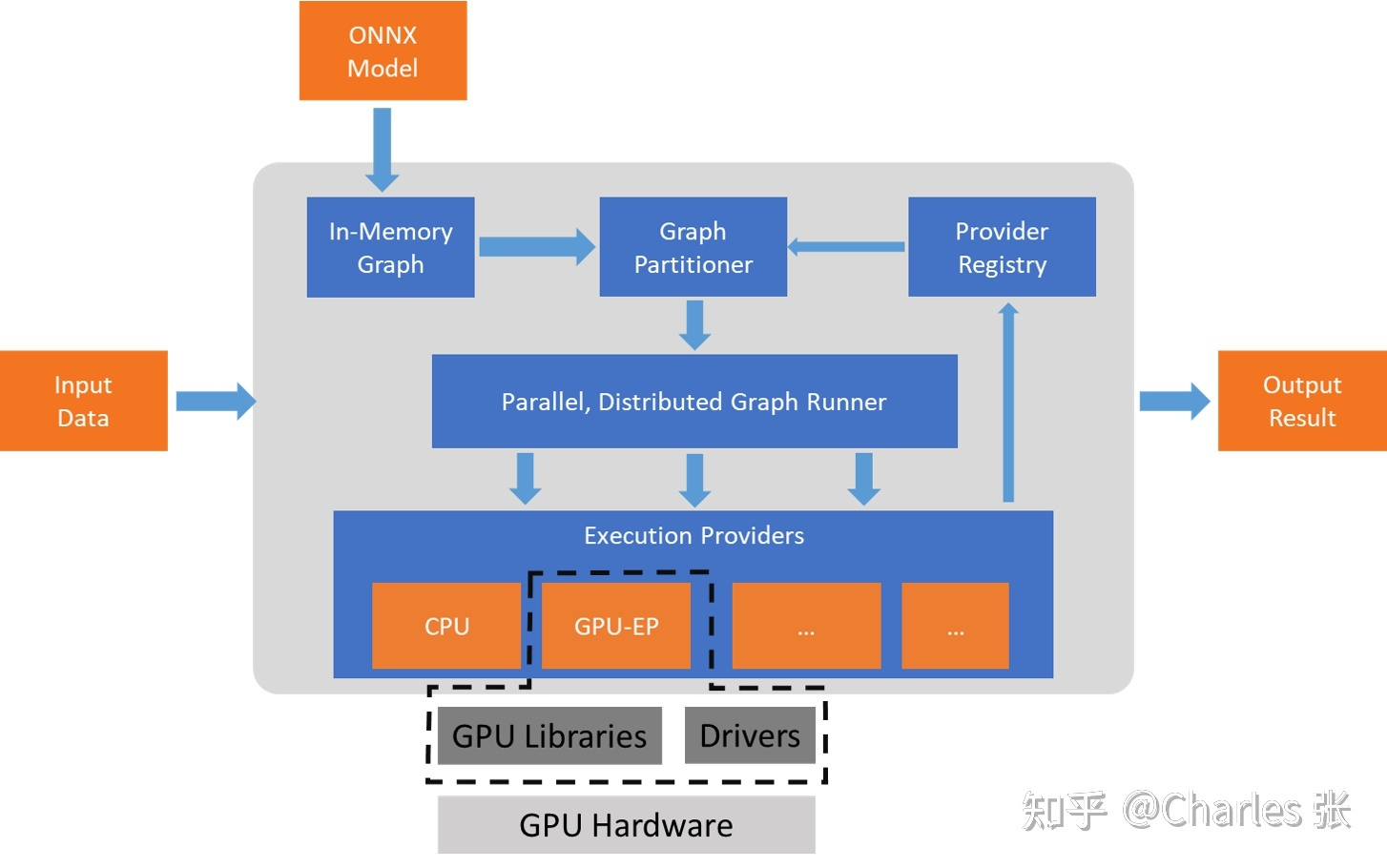
ONNX Runtime 的原理?
![]()
- 从 ONNX 模型开始,ONNXRuntime 首先将模型图转换为其内存中的图表示形式
- 然后,应用 graph transformations 转换,包括:a)执行一组独立于提供程序的优化,例如 float16 和 float32 之间的转换转换;b)根据可用的 execution provider 将图形划分为一组子图
- 每个子图都分配给一个 execution provider。通过使用 GetCapabilityAPI 查询 execution provider 的功能,使得我们确保可以由对应的 execution provider 执行子图
- 将子图分配给不同硬件设备执行,以保证执行速度为目标,期间还涉及不同分支或者 OP 内部的并行计算
ONNXRuntime 的 Execution Providers (EP)?
- ONNX Runtime 通过提供不同的 Execution Providers (EP) 支持多种硬件加速库,以实现同一个模型部署在不同的软件和硬件平台,并充分使用平台的计算资源和加速器,如 CUDA、DirectML、Arm NN、NPU 等
- ONNX Runtime 则把计算图的节点分配到对应的计算平台进行计算。但是,加速器可能无法支持全部的算子(Operator),而只是支持其中一个子集,因此对应的 EP 也只能支持该算子子集。如果要求 EP 执行一个完整的模型,则无法使用该加速器。因此,ONNX Runtime 的设计并不要求 EP 支持所有的算子,而是把一个完整的计算图拆分为多个子图,尽可能多地把子图分配到加速平台,而不被支持的节点则使用默认的 EP(CPU)进行计算
ONNXRuntime 执行推理三个步骤的原理?
- Session 构造:创建一个 InferenceSession 对象,包括负责 OpKernel 管理的 KernelRegistryManager 对象,持有 Session 配置信息的 SessionOptions 对象,负责图分割的 GraphTransformerManager,负责 log 管理的 LoggingManager 等。这个时候 InferenceSession 就是一个空壳子,只完成了对成员对象的初始构建
- 模型初始化:将 onnx 模型加载到 InferenceSession 中并进行进一步的初始化
- 模型运行:即 InferenceSession 每次读入一个 batch 的数据并进行计算得到模型的最终输出。然而其实绝大多数的工作早已经在 InferenceSession 初始化阶段完成。细看下源码就会发现 run 阶段主要是顺序调用各个 node 的对应 OpKernel 进行计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import psutil
import onnxruntime
import numpy
assert 'CUDAExecutionProvider' in onnxruntime.get_available_providers()
device_name = 'gpu'
# 1.Session构造
sess_options = onnxruntime.SessionOptions()
sess_options.optimized_model_filepath = os.path.join(output_dir, "optimized_model_{}.onnx".format(device_name))
sess_options.intra_op_num_threads=psutil.cpu_count(logical=True)
# 2.模型加载与初始化
session = onnxruntime.InferenceSession(export_model_path, sess_options,providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider'])
# onnxruntime.InferenceSession(onnx_path,providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'])
# 3.模型运行
# 构造输入,这里3输入
data=batch_data[i]
ort_inputs = {
'input_ids': data[0].cpu().reshape(1, max_seq_length).numpy(),
'input_mask': data[1].cpu().reshape(1, max_seq_length).numpy(),
'segment_ids': data[2].cpu().reshape(1, max_seq_length).numpy()
}
# 推理
ort_outputs = session.run(None, ort_inputs)
ONNXRuntime 模型初始化的原理?
- 模型加载:在 C++ 后端会调用对应的 Load () 函数,InferenceSession 一共提供了 8 种 Load 函数。包读从 url,ModelProto,void* model data,model istream 等读取 ModelProto
- Providers 注册:在 Load 函数结束后,InferenceSession 会调用函数 RegisterExecutionProviders (),该函数会完成 ExecutionProvider 的注册工作。这里解释一下 ExecutionProvider,ONNXRuntime 用 Provider 表示不同的运行设备比如 CUDAProvider 等。目前 ONNXRuntimev1.0 支持了包括 CPU,CUDA,TensorRT,MKL 等七种 Providers。通过调用 sess->RegisterExecutionProvider () 函数,InferenceSession 通过一个 list 持有当前运行环境中支持的 ExecutionProviders
- InferenceSession 初始化:在 Load 函数结束后,InferenceSession 会调用函数 sess->Initialize (),这时 InferenceSession 会根据自身持有的 model 和 execution providers 进行进一步的初始化(在第一阶段 Session 构造时仅仅持有了空壳子成员变量)。该步骤是 InferenceSession 初始化的核心,一系列核心操作如内存分配,model partition,kernel 注册等都会在这个阶段完成
ONNXRuntime 的 “InferenceSession 初始化” 原理?
- 首先,session 会根据 level 注册 graph optimization transformers,并通过 GraphTransformerManager 成员进行持有
- 接下来 session 会进行 OpKernel 注册,OpKernel 即定义的各个 node 对应在不同运行设备上的计算逻辑。这个过程会将持有的各个 ExecutionProvider 上定义的所有 node 对应的 Kernel 注册到 session 中,session 通过 KernelRegistryManager 成员进行持有和管理
- 然后 session 会对 Graph 进行图变换,包括插入 copy 节点,cast 节点等
- 接下来是 model partition,也就是根运行设备对 graph 进行切分,决定每个 node 运行在哪个 provider 上
- 最后,为每个 node 创建 ExecutePlan,运行计划主要包含了各个 op 的执行顺序,内存申请管理,内存复用管理等操作
ONNXRuntime 的三等级的图优化 (Graph Optimization)?
- Basic (基础):平台无关的优化,在拆分子图之前进行。Basic 优化主要是冗余的节点和计算,包括 Constant Folding(常量折叠)、Redundant node eliminations(冗余节点消除)、Semantics-preserving node fusions(节点融合)
- Extended (扩展):发生在拆分子图之后,实现更复杂的节点融合,目前只支持 CPU 和 CUDA 的 EP
- Layout Optimizations (结构优化):需要改变数据的结构,以获得更高的计算性能提升,目前只支持 CPU 的 EP
ONNXRuntime 1.8 在 C++ 上的使用流程?
- 模型初始化:基于 onnx 模型初始化 runtime Session
1
2
3
4
5
6
7
8// 创建会话参数、会话
Env mEnv;
SessionOptions sessionOptions = SessionOptions(); // SessionOptions;
Ort::Session* mSession=nullptr;
onnx_path="xxxx/xxx.onnx"
// 使用文件的方式创建会话
session = new Ort::Session(mEnv, onnx_path.c_str(), sessionOptions); - 图像处理:根据训练模型的前处理方式处理数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
cv::Mat imageBGR = cv::imread(imageFilepath, cv::ImreadModes::IMREAD_COLOR);
cv::Mat resizedImageBGR, resizedImageRGB, resizedImage, preprocessedImage;
cv::resize(imageBGR, resizedImageBGR,
cv::Size(inputDims.at(2), inputDims.at(3)),
cv::InterpolationFlags::INTER_CUBIC);
cv::cvtColor(resizedImageBGR, resizedImageRGB,
cv::ColorConversionCodes::COLOR_BGR2RGB);
resizedImageRGB.convertTo(resizedImage, CV_32F, 1.0 / 255);
cv::Mat channels[3];
cv::split(resizedImage, channels);
// Normalization per channel
// Normalization parameters obtained from
// https://github.com/onnx/models/tree/master/vision/classification/squeezenet
channels[0] = (channels[0] - 0.485) / 0.229;
channels[1] = (channels[1] - 0.456) / 0.224;
channels[2] = (channels[2] - 0.406) / 0.225;
cv::merge(channels, 3, resizedImage);
// HWC to CHW
cv::dnn::blobFromImage(resizedImage, preprocessedImage); - 构建输入输出:将预处理后的数据整理成 onnxruntime 的格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 若要使用 ONNX 运行时运行推理,用户负责创建和管理输入和输出缓冲区
# 这些缓冲区可以通过 std::vector 创建和管理。应将线性格式的输入数据复制到缓冲区
# 输入缓冲区
size_t inputTensorSize = vectorProduct(inputDims);
std::vector<float> inputTensorValues(inputTensorSize);
inputTensorValues.assign(preprocessedImage.begin<float>(),
preprocessedImage.end<float>());
# 输出缓冲区
size_t outputTensorSize = vectorProduct(outputDims);
assert(("Output tensor size should equal to the label set size.",
labels.size() == outputTensorSize));
std::vector<float> outputTensorValues(outputTensorSize);
# 创建缓冲区后,它们将用于创建实例,其 Ort::Value 实例是 ONNX 运行时的张量格式
# 有多少个输入,创建多少个Ort::Value
std::vector<Ort::Value> inputTensors;
std::vector<Ort::Value> outputTensors;
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(
OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, inputTensorValues.data(), inputTensorSize, inputDims.data(),
inputDims.size()));
outputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, outputTensorValues.data(), outputTensorSize,
outputDims.data(), outputDims.size())); - 模型推理:使用 Session 推理
1
2
3
4// https://github.com/microsoft/onnxruntime/blob/rel-1.6.0/include/onnxruntime/core/session/onnxruntime_cxx_api.h#L353
session.Run(Ort::RunOptions{nullptr}, inputNames.data(),
inputTensors.data(), 1, outputNames.data(),
outputTensors.data(), 1); - 解析返回:解析推理后的结果
1 | # 这里获取第一个输出口的结果 |
参考:
- YOLOv5 在 C++ 中通过 Onnxruntime 在 window 平台上的 cpu 与 gpu 推理_lazyoneguy 的博客 - CSDN 博客
- Deploying PyTorch Model into a C++ Application Using ONNX Runtime | by Huili Yu | Medium
- 一、ONNX Runtime 的设计理念_onnxruntime_丶 Shining 的博客 - CSDN 博客
- 模型部署入门教程(五):ONNX 模型的修改与调试 - 知乎
- ONNXRuntime 整体概览 - 知乎
- ONNXRuntime 源码之 OpKernel 注册 - 知乎
- AI 模型部署 (1) - ONNX - 知乎
- AI 模型部署 (2) - ONNX Runtime - 知乎
- [5. ONNXRuntime 概述 - 知乎 (zhihu. com)]([ONNX 从入门到放弃] 5. ONNXRuntime 概述 - 知乎
- [推理模型部署 (一):ONNX runtime 实践 - 知乎]( https://zhuanlan.zhihu.com/p/582974246 [[ONNX 从入门到放弃] 1. ONNX 协议基础 - 知乎 (zhihu. com)
- onnxruntime 的 C++ api 如何实现 session 的多输入与多输出? - 知乎
- lite.ai.toolkit/deeplabv3_resnet101.cpp at main · DefTruth/lite.ai.toolkit · GitHub
- YOLOv5+TensorRT+OnnxRuntime+Visual Studio+CmakeLists 实现推理: YOLOv5 在 C++ 中通过 TensorRT 或者 Onnxruntime 在 Visual Studio+CmakeLists 上实现推理,用了 spdlog 实现输出,需提前下好。
- ONNX Runtime C++ Inference - Lei Mao’s Log Book