PGNet
什么是 PGNet ?
![]()
- PGNet 提出了一种简单但功能强大的任意形状的文本检测识别器,它不需要字符级标注,没有 NMS 和 RoI 操作,在端到端性能方面取得了很好的性能、运行速度
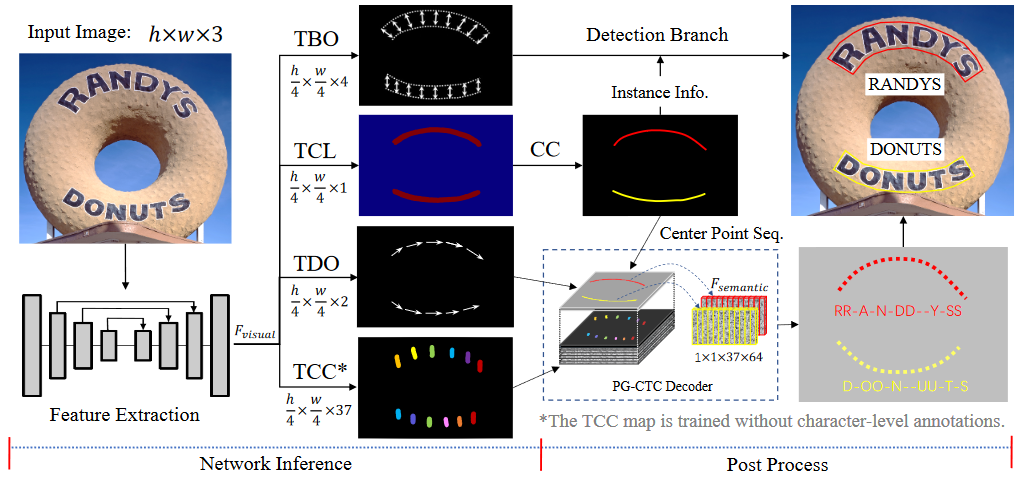
PGNet 的网络结构?
![]()
- Featrue Extraction:输入图像输入到带有 FPN 的主干中以产生特征 Fvisual。然后 Fvisual 用于通过多任务并行学习以输入图像的 1/4 大小预测 TCL、TBO、TDO 和像素级 TCC 图
- 文本边框偏移 (TBO):类似 SAST, 表示了 TCL 中每个像素关于上下边界的偏移量,是为了在文字识别时控制识别范围
- 文本中心线 (TCL):类似 SAST,文本中心线,文本行上下边界收缩 20% 后得到的区域,而左右边界仍保持不变
- 文本方向偏移 (TDO):每一个 TCL 上的像素指向下一个阅读点的方向
- 文本字符分类图 (TCC):对每个像素的字符类别预测概率,一共 37 个字符,包括 26 个字母、10 个数字和 1 个背景
- Detection Branch:文本实例检测分支,包括位置与大小
- PG-CTC Decoder:训练像素级 TCC 图,以解决字符级标注的缺失
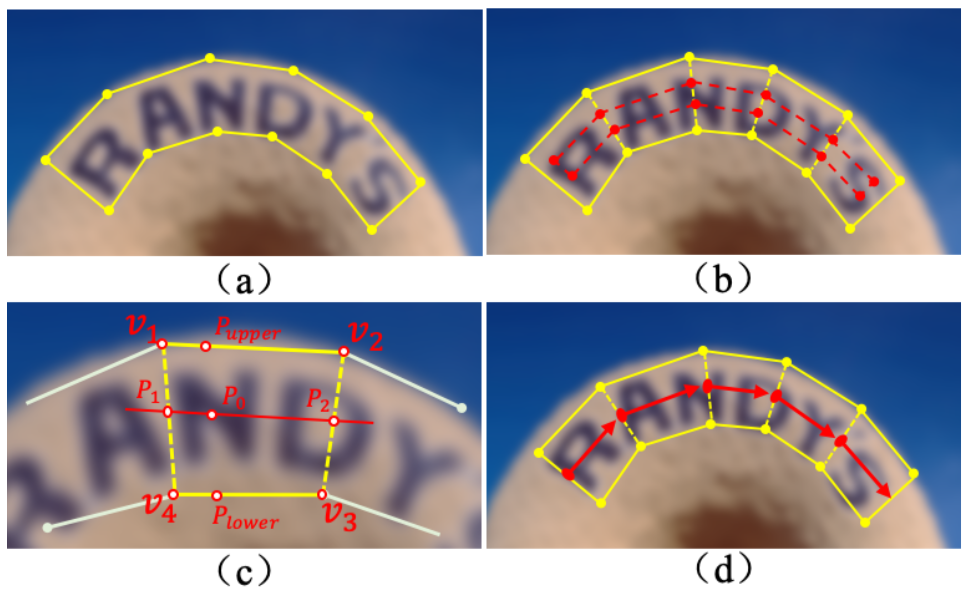
PGNet 的标签制作?
![]()
- 文本边框偏移 (TBO):类似 SAST,表示了 TCL 中每个像素关于上下边界的偏移量,是为了在文字识别时控制识别范围
- 文本中心线 (TCL):类似 SAST,文本中心线,文本行上下边界收缩 20% 后得到的区域,而左右边界仍保持不变
- 文本方向偏移 (TDO):每一个 TCL 上的像素指向下一个阅读点的方向
- 文本字符分类图 (TCC):对每个像素的字符类别预测概率,一共 37 个字符,包括 26 个字母、10 个数字和 1 个背景
PGNet 的 PG-CTC Decoder?
![]()
- 采样输出点:模型从 TCL 中提取采样点,通过 TDO 的信息对这些采样点进行排序
- CTC 解析输出点:取出对应位置 TCC 采样的预测概率,然后使用 CTC 计算损失或者解析输出
PGNet 的图修正模块 (GRM)?
![]()
- 输入 TCC map+ +NxN 的邻接矩阵,输出 (N, 37),邻接矩阵使用以下公式定
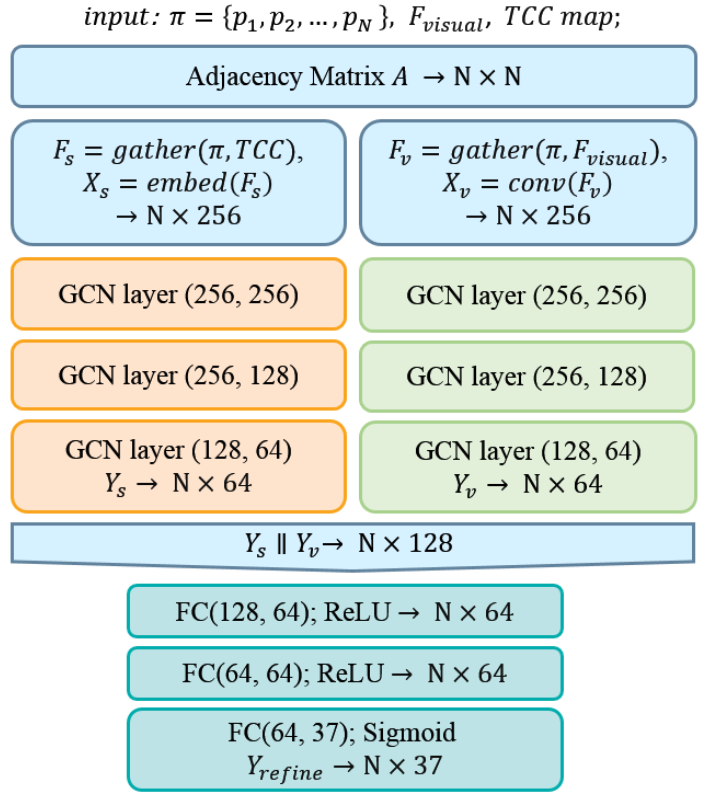
- 特征经过 3 层的 GCN,每个节点的隐变量由 256 变为 64,最后变为 37(类别数量)
PGNet 的模型输出解析?
- 1)提取文本实例:从 TCL 中提取每个文本实例的中心点序列,借助来自 TBO 的相应边界偏移信息,可以通过多边形恢复对每个文本实例的检测
- 2)从文本实例采样:借助 TDO 从文本实例按照正确的阅读顺序提取 N 个中心点序列,从而得到中心序列 π,得到 N 个预测结果,如 “RR-A-N-DD–Y-SS”
- 3)简单后处理:去掉间隔符号和间隔中间重复字符,得到预测结果,如上步骤的结果是 “RANDYS”
PGNet 的损失函数?
参考: