FOTS:Fast Oriented Text Spotting with a Unified Network

第一个端到端解决文本识别的模型,相比较两阶段的文本定位方法,它的检测速度更快,基本思路是通过文本检测分支实现文本行区域的提取,然后通过 RoIRotate 模块实现文本行的 “摆正”,最后使用 CRNN+CTC 的模式实现文本行的字符识别
什么是 FOTS ?
- 第一个端到端解决文本识别的模型,相比较两阶段的文本定位方法,它的检测速度更快,基本思路是通过文本检测分支实现文本行区域的提取,然后通过 RoIRotate 模块实现文本行的 “摆正”,最后使用 CRNN+CTC 的模式实现文本行的字符识别
- RoIRotate 模块要通过仿射变换转换文本区域,所以 FOTS 只能识别文字中心在一个线上的文本行,无法处理弯曲文本行
FOTS 的网络结构?
![]()
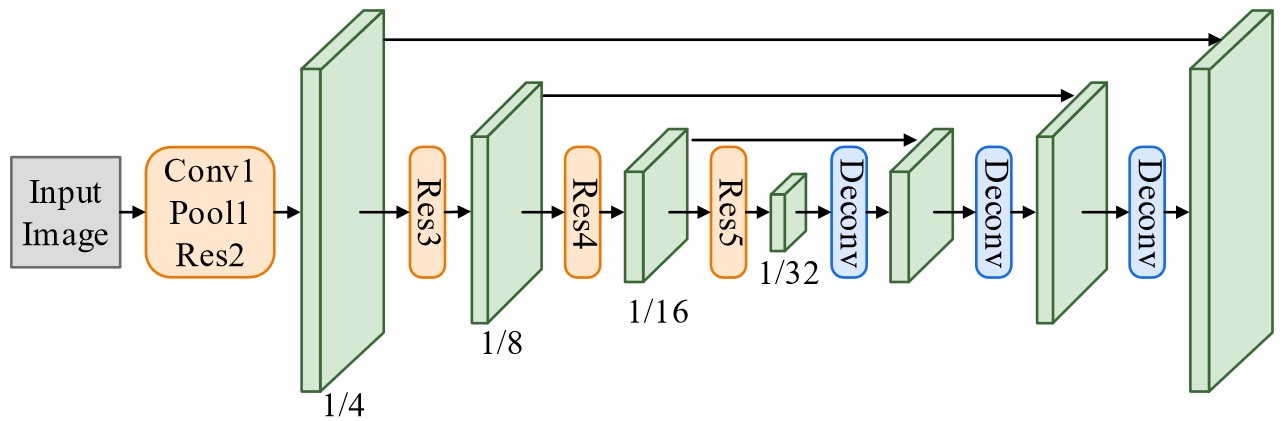
- shared convolutions:使用 Resnet 搭建,首先使用下采样,然后使用反卷积上采样,并且使用类似 SegNet 的高分辨率连接到低分辨率的连接
- 文本检测分支:使用类似 anchor-free 的目标检测方式,将 shared convolutions 的每个 grid 视为文本行中心,然后预测其文本行的宽高
- RoIRotate:根据文本检测分支的输出 + shared convolutions 输出,将文本行转为横向文本
- 文字识别分支:基于 CRNN+CTC 的方式学习和识别文本行

FOTS 的 shared convolutions 模块?
![]()
- 首先通过 ResNet 提取特征,然后通过反卷积上采样,类似 SegNet 一样中间使用残差连接,最后输出 C 2 特征
FOTS 的文本检测分支?
![Drawing 2023-04-09 20.21.26.excalidraw]()
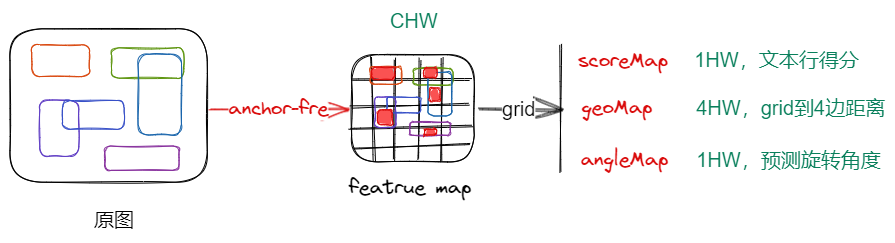
- 使用类似 anchor-free 的目标检测方式,将 shared convolutions 的每个 grid 视为文本行中心,然后预测其文本行的宽高
- 假设 shared convolutions 输出是 的特征,文本检测分支输出 3 个分支,分别表示文本行的得分、该 grid 到四边的距离和该文本行的旋转角度
FOTS 的 RoIRotate 模块?
![]()
- 使用目标检测的后处理获得文本行,根据文本行的宽高及旋转角得到四个角点的位置,假设四个点是 (, ),(, ),(, ),(, ),现在要将这个区域转到 (0,0) 起点,宽高 (wh) 的区域,可以通过仿射变换实现
- 仿射变换矩阵需要变换前后的 3 对点求得,不妨取 (, )->(0,0),(, )->(w, 0),(, )->(w, h),求取方法是调用 opencv 的 getAffineTransform 函数即可,仿射矩阵变换后,文本的中心线平行 x 轴

FOTS 的文字识别分支?
![]()
- 文字识别是在 RoIRotate 模块输出的基础上进行的,就是得到平行文本行的基础上进行的,其过程有 4 个
- CNN 提取特征:使用轻量化网络 MobileNetv 3,其中输入图像的高度统一设置为 32,宽度可以为任意长度,经过 CNN 网络后,特征图的高度缩放为 1
- 双向 LSTM(BiLSTM)对特征序列进行预测:学习序列中的每个特征向量并输出预测标签分布。这里其实相当于把特征向量的宽度视为 LSTM 中的时间维度
- 全连接层分类:使用全连接层对每个序列进行 N+1 类别预测,获取模型的预测结果
- CTC:解码模型输出的预测结果,得到最终输出

FOTS 的损失函数?
- 网络的损失分为两部分,即文本行识别损失 、文本行字符识别损失 ,通过参数 控制两者的权重
参考: