SOTR:Segmenting Objects with Transformers
SOTR 利用 transformer 将实例分割任务简化为 2 个过程,一是通过 transformer 预测每个实例的类别,二是通过多级上采样模块动态生成分割掩码
什么是 SOTR?
![]()
- SOTR 利用 transformer 将实例分割任务简化为 2 个过程,一是通过 transformer 预测每个实例的类别,二是通过多级上采样模块动态生成分割掩码
- 图片经过 FPN 的特征,对其进行序列化后得到 NxN 的序列,经过 transformer 后输出 NxN 个序列的结果,将原图 gt 实例某个序列上,计算损失并更新网络
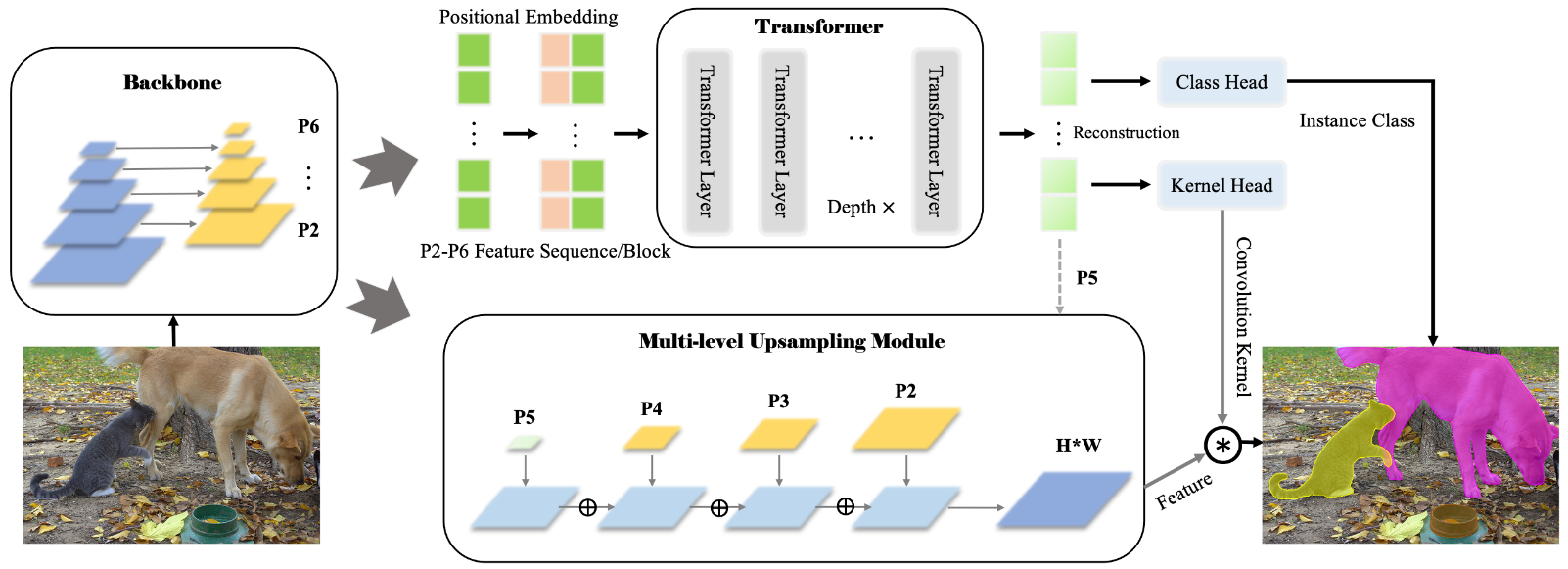
SOTR 的模型结构?
![]()
- BackBone:使用 FPN 生成 P2-P6 的多尺度特征
- Transformer:P2-P6 特征添加添加 Positional Embedding 后,输入 Transformer 进行学习,得到每张图的预测集合
- Multi-Level Upsampling Module:取出 BackBone 的 P 2、P 3、P 4 和 Transformer 的 P5,一起上采样到 P 2 分辨率进行合并,然后输出
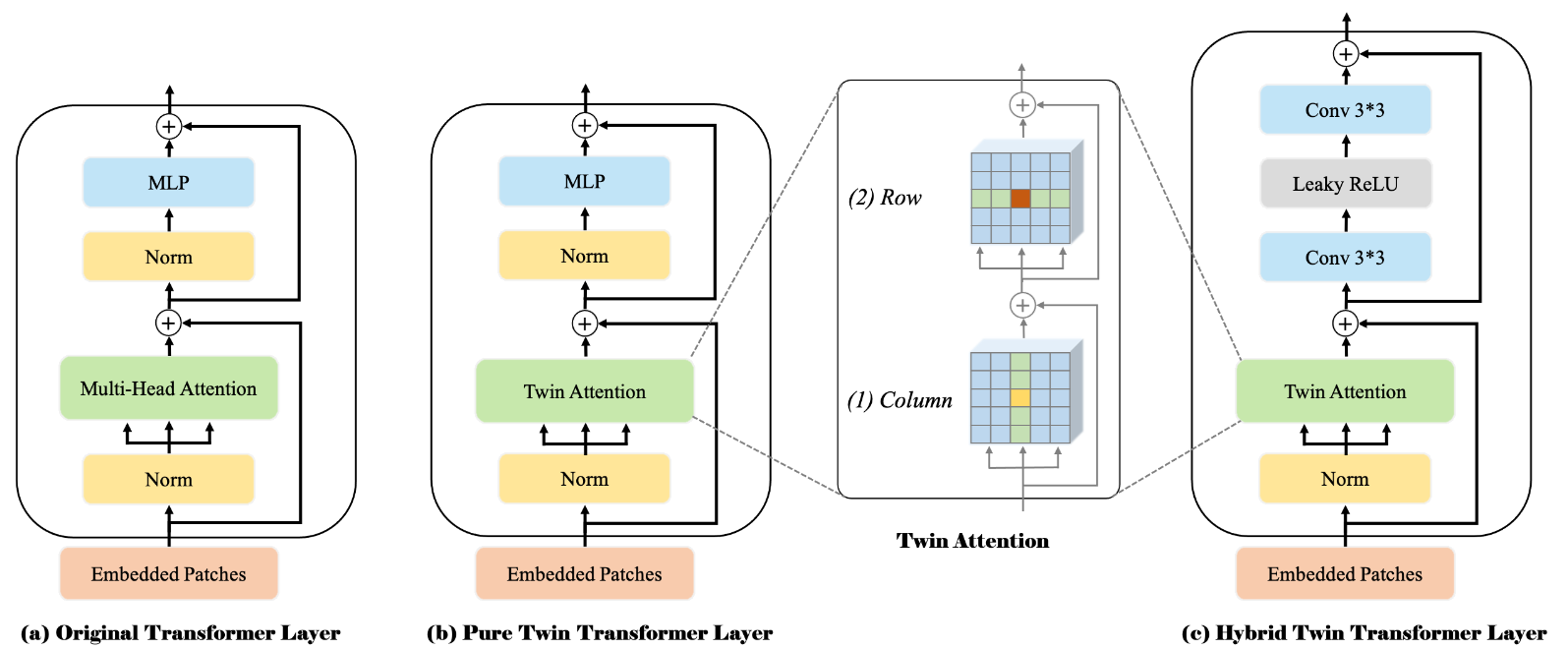
SOTR 的 Twin attention 模块?
![]()
- 为了降低原始 transformer block 的计算成本,SOTR 将生成注意力的过程转为 2 次生成注意力的过程,第一次是生成行注意力,第二次生成列注意力。使得针对 HxW 个 token 生成序列时,复杂度由 O (HWxHW) 变为 O (H^2 W+HW^2)
- FFN 部分由 Linear 变为卷积实现
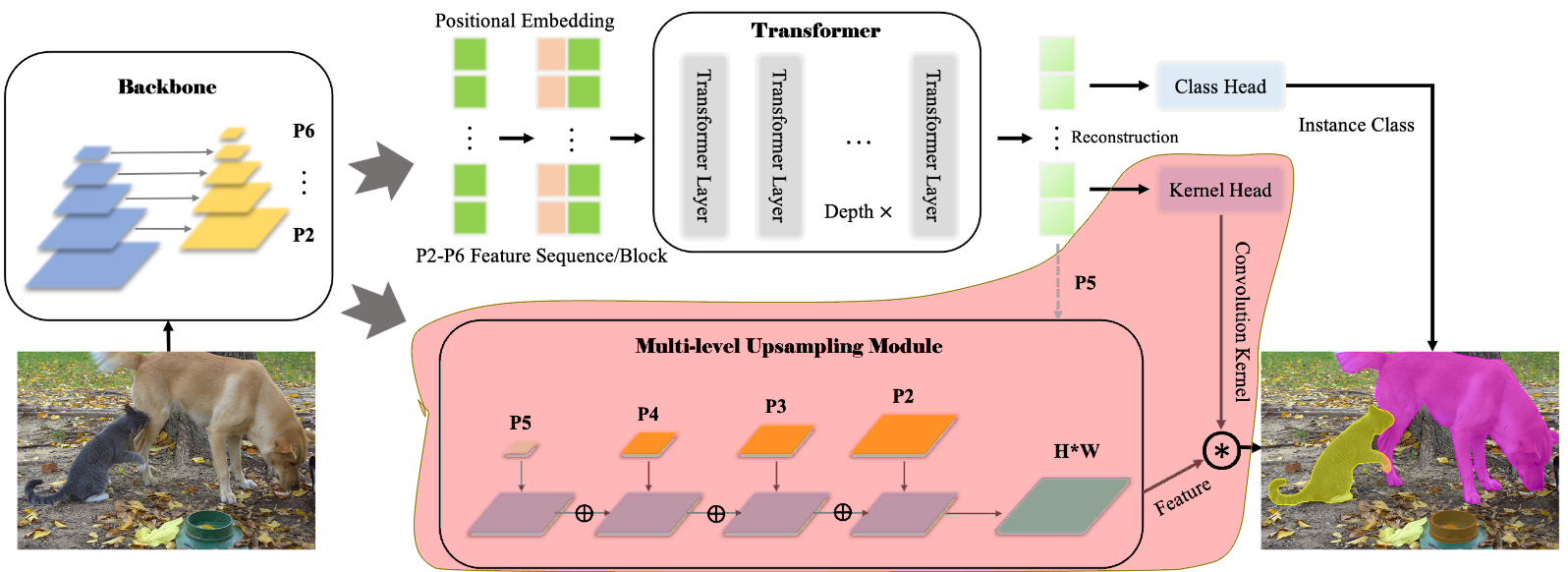
SOTR 的 Multi-Level updampling module?
![]()
- 原始特征:取出 BackBone 的 P 2、P 3、P 4 和 Transformer 的 P5,一起上采样到 P 2 分辨率进行合并
- 动态卷积核:动态卷积核由 transformer 生成
SOTR 的样本匹配?
- 图片经过 FPN 的特征,对其进行序列化后得到 NxN 的序列,经过 transformer 后输出 NxN 个序列的结果,将原图 gt 实例某个序列上,计算损失并更新网络
- 直接使用位置映射样本,是因为 SOTR 只使用 transformer 的 encoder 部分,transformer 不会打乱序列的顺序,只会使用自注意力机制更新自己的隐向量
参考:
- 【论文笔记】SOTR: Segmenting Objects with Transformers_m0_61899108 的博客 - CSDN 博客
- 【分割 Transformer】SOTR: Segmenting Objects with Transformers - 知乎
- [SOTR:Segmenting Objects with Transformers [ICCV 2021] | Tianliang (starlg.cn)](SOTR:Segmenting Objects with Transformers [ICCV 2021] | Tianliang