Segment Anything
SAM 通过 transformer 将点、框、Mask、文本等 prompt 和图片进行编码学习,可以实现对图片任意目标的分割
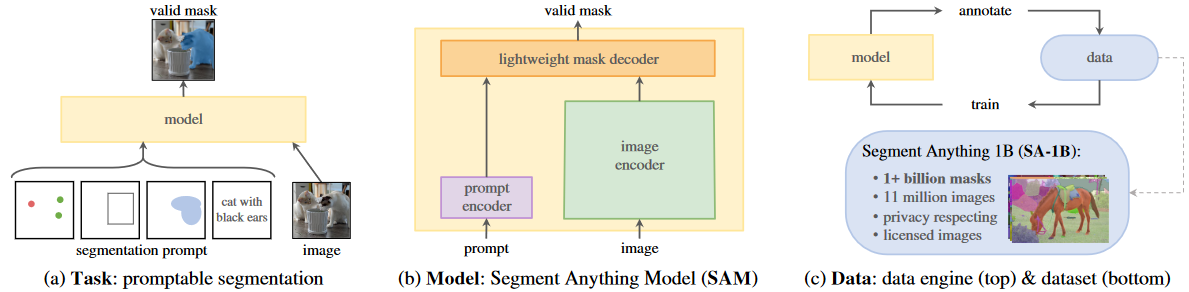
什么是 SAM ?
![]()
- a) SAM 利用 “图片 - 分割提示” 实现对图片上任意目标的分割,分割提示包括:点、框、Mask、文本
- b) SAM 首先利用 prompt encoder 编码 "分割提示",利用 image encoder 编码 “图片”,然后通过 Mask decoder 解析输出 Mask
- c) SAM 利用数据驱动去做模型训练,模型输出结果后再输入模型训练
SAM 的网络结构?
![]()
- image encoder:类似 VIT 的过程,输入 image (1,3, H, W), 输出 image_embedding (1, C, H/16, W/16),即 (1, HW/256, C) 的 tokens 表示
- mask:mask prompt,直接和 image_embedding 相加即可
- prompt encoder:包含 3 种提示的编码过程,其中点、框按位置被编码为 Pos embedding (1,N,C),文本通过 clip 模型被编码为 Pos embedding (1,M,C)
- mask decoder:根据 image_embedding 和 prompt encoder 输出,结合 IOU tokens (1,1,C) 和 mask tokens (1,P,C),解析出目标 mask (1,1+P+N+M, H/16, W/16) 和 iou (1,1+P+N+M)

SAM 的 image encoder?
- 类似 VIT 的 encoder 过程,输入 image (1,3, H, W), 输出 image_embedding (1, C, H/16, W/16),即 (1, HW/256, C) 的 tokens 表示
1
2
3
4
5image_encoder=ImageEncoderViT(..)
# batched_input={List,List} -> torch.Size([2, 3, 1024, 1024])
input_images = torch.stack([preprocess(x["image"]) for x in batched_input], dim=0)
# torch.Size([2, 3, 1024, 1024]) -> torch.Size([2, 256, 64, 64])
image_embeddings = image_encoder(input_images)
SAM 的 prompt encoder?
- 包含 3 种提示的编码过程,其中点、框按位置被编码为 Pos embedding (1, N, C),文本通过 clip 模型被编码为 Pos embedding (1, M, C),最终输出(1,N+M,C ) 的稀疏编码 sparse_embeddings
- point&box:每个点编码为 1 个 pos embedding,每个 box 编码为 2 个 pos embedding(box 被两个点定义)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24embed_dim=256
num_point_embeddings: int = 4 # pos/neg point + 2 box corners
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(num_point_embeddings)]
point_embeddings = nn.ModuleList(point_embeddings)
not_a_point_embed = nn.Embedding(1, embed_dim)
# point prompt
points = points + 0.5 # Shift to center of pixel
# 根据点位置points,在输入(1024,1024)的基础上生成pos embedding
point_embedding = pe_layer.forward_with_coords(points, input_image_size) #torch.Size([1,3,2])+(1024,1024)->torch.Size([1,3,256])
# 点有3类,-1表示非嵌入点,此时不使用pos embedding,0表示正样本点,1表示负样本点
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += not_a_point_embed.weight
point_embedding[labels == 0] += point_embeddings[0].weight
point_embedding[labels == 1] += point_embeddings[1].weight
# box prompt
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2) # 一个框肯定2个点
corner_embedding = pe_layer.forward_with_coords(coords, input_image_size)
corner_embedding[:, 0, :] += point_embeddings[2].weight #框第一个点
corner_embedding[:, 1, :] += point_embeddings[3].weight #框第二个点
# 汇总point、box编码
sparse_embeddings = torch.empty((1, 0, embed_dim))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1) - text:通过 CLIP 模型将文本编码到 (1,M,C)
SAM 的 mask prompt 如何处理?
- mask 利用 CNN 输出和 image_embedding (1,C,H/16,W/16) 一样大小的编码,后续直接相加
1 | mask_downscaling = nn.Sequential( |
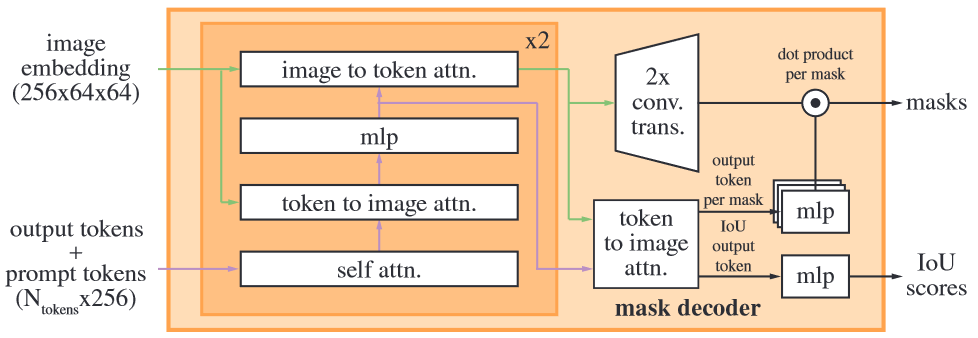
SAM 的 mask decoder?
![]()
- 输入:image_embedding (1, C, H/16, W/16)、image_embedding 大小的位置编码 image_pe (1, C, H/16, W/16)、稀疏提示编码 sparse_prompt_embeddings (1, N, C)、密集提示编码 dense_prompt_embeddings (1,C,H/16, W/16)
- (1) tansformer 整合所有编码: 将 image_embedding+dense_prompt_embeddings 视为 transformer encoder 的 k,image_pe 视为 pos embedding,sparse_prompt_embeddings 视为 decoder 的 q,并且参考 VIT 的 class_token,不直接使用 sparse_prompt_embeddings 输出作为最终结果,而是另外生成 1 个 iou token 和 P 个 mask token 作为最终结果,所以输入 transformer decoder 的 token 变为 (1,1+P+N,C),经过 transformer 后 decoder 和 encoder 分别输出 hs (1,1+P+N,C), src (1,HW/256,C);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18num_multimask_outputs=3
transformer_dim=256
iou_token = nn.Embedding(1, transformer_dim)
num_mask_tokens = num_multimask_outputs + 1
mask_tokens = nn.Embedding(num_mask_tokens, transformer_dim)
# Concatenate output tokens
output_tokens = torch.cat([iou_token.weight, mask_tokens.weight], dim=0) # torch.Size([5, 256])
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1) # torch.Size([1, 5, 256])
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1) # torch.Size([1, 12, 256])
# Expand per-image data in batch direction to be per-mask
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0) # torch.Size([1, 256, 64, 64]) -》torch.Size([1, 256, 64, 64])
src = src + dense_prompt_embeddings # torch.Size([1, 256, 64, 64])+torch.Size([1, 256, 64, 64])
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0) # torch.Size([1, 256, 64, 64])
b, c, h, w = src.shape
# Run the transformer torch.Size([1, 256, 64, 64]),torch.Size([1, 256, 64, 64]),torch.Size([1, 12, 256])
hs, src = transformer(src, pos_src, tokens) # torch.Size([1, 12, 256]) torch.Size([1, 4096, 256]) = q,k
iou_token_out = hs[:, 0, :] # torch.Size([1, 256])
mask_tokens_out = hs[:, 1 : (1 + num_mask_tokens), :] # torch.Size([1, 4, 256]) - (2) 生成 Mask 预测:取 hs 的第 1-P 个 token 作为预测结果 mask_tokens_out,src 经过反卷积上采样 4 倍,输出 upscaled_embedding (1,HW/16,C’),mask_tokens_out 经过 MLP 操作,将隐变量长度变为 C’, 即输出 hyper_in (1,P,C’),hyper_in 与 upscaled_embedding 点乘后输出 masks (1,P,HW/16),表示 p 个 mask
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
self.output_hypernetworks_mlps = nn.ModuleList(
[MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3) for i in range(self.num_mask_tokens)])
# Upscale mask embeddings and predict masks using the mask tokens
src = src.transpose(1, 2).view(b, c, h, w) # torch.Size([1, 256, 64, 64])
upscaled_embedding = self.output_upscaling(src) # torch.Size([1, 256, 64, 64]) -》torch.Size([1, 32, 256, 256])
hyper_in_list: List[torch.Tensor] = []
for i in range(self.num_mask_tokens):
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])) # torch.Size([1, 32])x4
hyper_in = torch.stack(hyper_in_list, dim=1) # torch.Size([1, 4, 32])
b, c, h, w = upscaled_embedding.shape # torch.Size([1, 32, 256, 256])
# 运算符@表示矩阵的点乘
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w) # torch.Size([1, 4, 32]) @ torch.Size([1, 32, 256, 256]) -> torch.Size([1, 4, 256, 256]) - (3) 生成 IOU 预测:取 hs 的第 1 个 token 作为预测结果 iou_token_out,然后使用 MLP 将隐变量长度变为 P,表示 P 个 mask 的 iou 预测
1
2
3iou_prediction_head = MLP(transformer_dim, iou_head_hidden_dim, num_mask_tokens, iou_head_depth)
# Generate mask quality predictions
iou_pred = iou_prediction_head(iou_token_out) # torch.Size([1,256]) -> torch.Size([1, 4])
SAM 如何直接分割所有目标?
- 以原图所有 cell 作为 point prompt 输入,输出 Mask 和 iou 后,通过 iou 阈值过滤 mask, 得到所有目标的 mask
参考: