OCRNet:Segmentation Transformer:Object-Contextual Representations for Semantic Segmentation
语义分割是对像素进行分类,而像素的类别标签是由它所在的目标的类别标签决定的,通常的上下文信息是基于像素之间的,OCRNet 根据类别数量,基于 "自注意力机制" 显式地增强来自同一物体的像素贡献
什么是 OCRNet ?
![OCRNet-20230408143335]()
- 语义分割是对像素进行分类,而像素的类别标签是由它所在的目标的类别标签决定的,通常的上下文信息是基于像素之间的,能不能利用像素所在目标的类别去构建上下文标签呢?
- OCRNet 根据类别数量,基于 "自注意力机制" 显式地增强来自同一物体的像素贡献

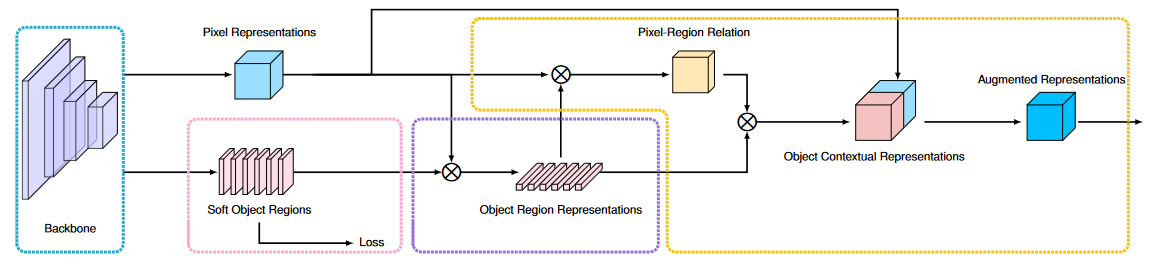
OCRNet 的网络结构?
![OCRNet-20230408143336]()
- Pixel Representations:经过 CNN 提取得到的结果,假设输出是 (BxCxHxW)
- 软对象区域(Soft Object Regions):根据目标的类别数量,使用 1 x 1 卷积调整通道数,假设最后有 17 个类别,则输出 (Bx 17 xHxW) 的特征,表示任意像素位置的 17 长度的隐向量。注意:这里有使用 loss 去监督每个像素的类别表示
- 对象区域表示(Object Region Representations):Pixel Representations 与 Soft Object Regions 的计算结果,即 (Bx 17 xHxW) x (BxCxHxW) =(B, 17, C),表示 17 个类的 C 长度的特征
- 对象上下文表示和增强表示:首先基于 Soft Object Regions 和 Object Region Representations 求得像素与区域相似度,即给每个像素增加区域上下文,然后和 Pixel Representations 输出 concat 在一起输出
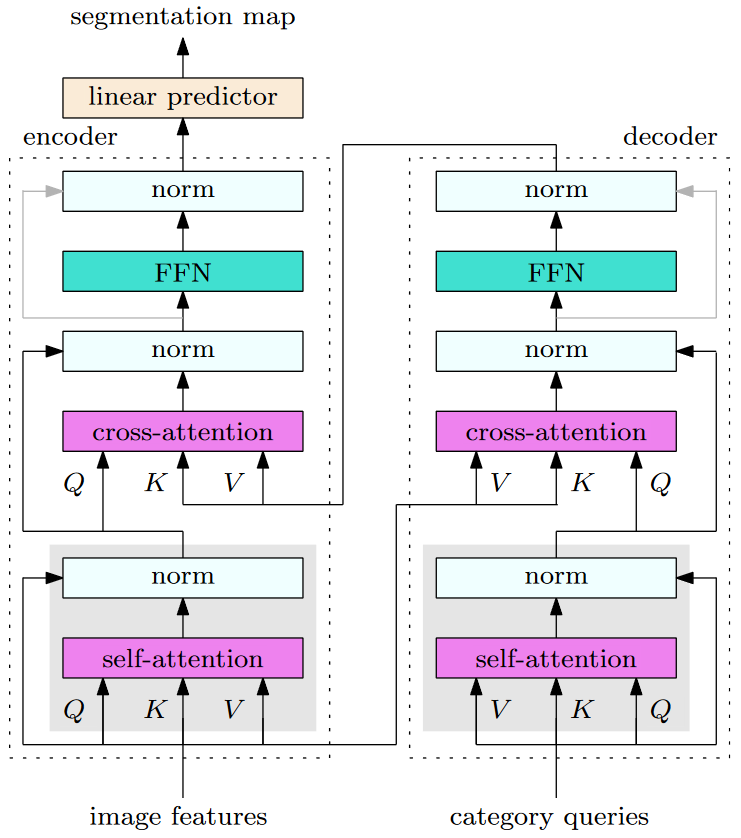
OCRNet 比较 transformer?
![OCRNet-20230408143336-1]()
- Transformer 输入:包括 2 部分,一部分是 image representations 输入 Transformer Encoder 用于增强特征表示,另外一部分是 category queries 输入到 Transformer Decoder 中可以用于编码不同语义类别的上下文信息。在原始 OCRNet 中,我们省略了灰色部分的操作,即 pixel representations 和 region representations 上的 Self-Attention 操作
- 类比 OCRNet:K,V 就是 CNN 输出 Pixel Representations,Q 就是 Soft Object Regions,首先通过 QK^T 得到 Object Region Representations,也就是注意力矩阵,然后 Object Region Representations 与 Pixel Representations 计算输出,也就是 (QK^T) xV 的过程
- 综上可以看出 OCRNet 方法背后的思想同 Transformer 的做法有不少共通之处,另外最近也有 2 篇非常不错的图像语义分割方面工作 MaskFormer 和 K-Net 都提出了很有意思的基于 Transformer Encoder + Decoder 的视角与思路
参考: