Swin Transformer:Hierarchical Vision Transformer using Shifted Windows
为解决原始 transformer 在全局上构建注意力的成本巨大问题,Swin Transformer 引入 WIndows 的概念,在每个 Windows 内构建全局注意力,使得成本由平方变为线性。同时借鉴 CNN 的层次特征,设计多层次的 transformer block,提取图像的多尺度特征
什么是 swin-trasformer?
![swin-transformer-20230408152156]()
- 原始的 vit 构建全局注意力,在 patch 数量多的情况下,其构建成本很高,因此 swin-trasformer 引入 locality 思想,对无重合的 window 区域内进行 self-attention 计算,并且为了不同 windows 的交流,设计了滑窗操作
- 同时,借鉴 CNN 的层次化的思想构建层次的 trasformer
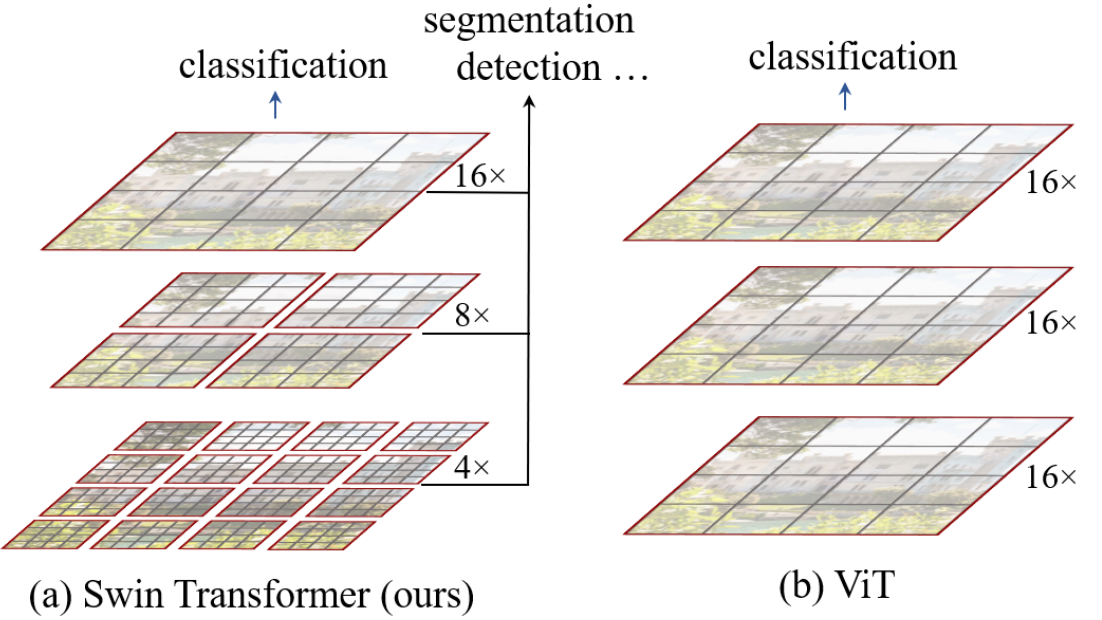
- 这种层级式的结构不仅非常灵活,可以提供各个尺度的特征信息,它的计算复杂度是随着图像大小而线性增长,而不是平方级增长
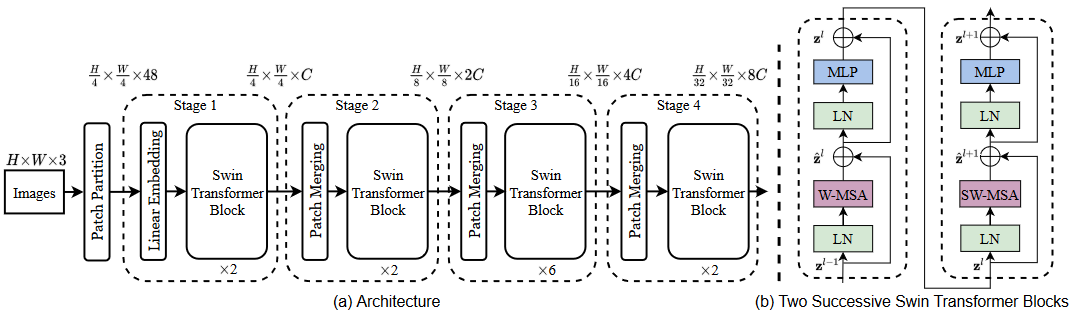
swin-trasformer 的结构?
![swin-transformer-20230408152157]()
- 整个模型采取层次化的设计,一共包含 4 个 Stage,每个 stage 都会缩小输入特征图的分辨率,像 CNN 一样逐层扩大感受野
- Patch Embedding:将图片切成一个个 Patch,并嵌入到 Embedding
- Linear Embedding:将输入 (B, S, 48) 转为 (B, S, C)
- Patch Merging:在每个 Stage 一开始降低图片分辨率,输出隐变量长度还是 2C,采用的方法是类似 YOLOv5 的输入,间隔采样 H, W,使得各缩小 2 倍,此时通道维度会变成原先的 4 倍,再通过一个全连接层再调整通道维度为 2C
- Swin Transformer Block:使用 Transformer 的 encoder 部分构建 "windows" 内所有 patch 的注意力
swin-trasformer 的 Patch Merging 模块?
![]()
- 采用的方法是类似 YOLOv5 的输入,间隔采样 H, W,使得各缩小 2 倍,此时通道维度会变成原先的 4 倍,再通过一个全连接层再调整通道维度为 2C
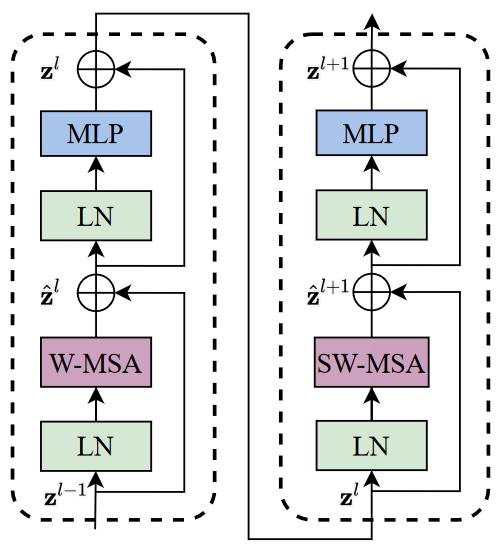
swin-trasformer 的 Swin Transformer Block?
![swin-transformer-20230408152158-1]()
- Swin Transformer Block 包含 2 部分,即窗口多头自注意层(window multi-head self-attention, W-MSA)和移位窗口多头自注意层(shifted-window multi-head self-attention, SW-MSA)
- 窗口多头自注意层(W-MSA):传统的 Transformer 都是基于全局来计算注意力的,因此计算复杂度十分高。而 Swin Transformer 则将注意力的计算限制在每个窗口内,进而减少了计算量
- 移位窗口多头自注意层(SW-MSA):为了保证不重叠窗口之间有联系,采用了 shifted window self-attention 的方式重新计算一遍窗口偏移之后的自注意力
swin-trasformer 的 W-MSA 模块?
![]()
- 左侧普通的 Multi-head Self-Attention(MSA)模块,计算 feature map 中的每个像素(或称作 token,patch)所有注意力。右侧 Windows Multi-head Self-Attention(W-MSA)模块,首先将 feature map 按照 MxM(M=2)大小划分成一个个 Windows,然后单独对每个 Windows 内部进行 Self-Attention
swin-trasformer 的 W-MSA 模块的 “相对位置编码”?
![]()
WindowAttention 与传统的 Attention 主要区别是在原始计算 Attention 的公式中的 Q, K 时添加一个可学习的相对位置参数 B
假设 window_size = 2*2 即每个窗口有 4 个 token ,在计算 self-attention 时,每个 token 都要与所有的 token 计算 QK 值,如图 2 所示,当位置 1 的 token 计算 self-attention 时,要计算位置 1 与位置 (1,2,3,4) 的 QK 值,即以位置 1 的 token 为中心点,中心点位置坐标 (0,0),其他位置计算与当前位置坐标的偏移量
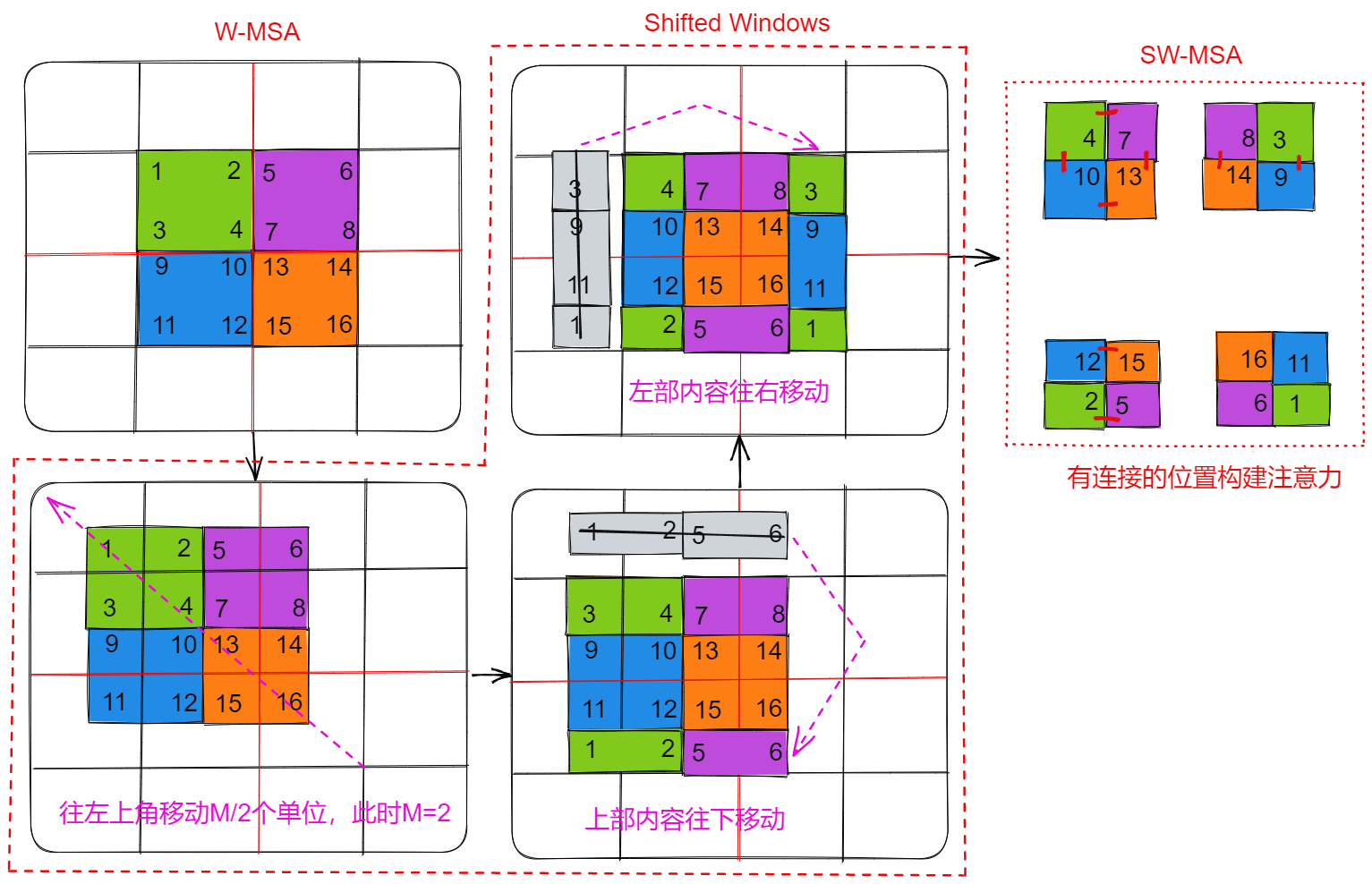
swin-trasformer 的 SW-MSA 模块?
![Drawing 2023-04-06 20.23.58.excalidraw]()
- 上图首先绘制了 W-MSA 在 2 x 2 的 patch 上构建注意力示意图,然后通过 Shifted Windows 操作,在新的 2 x 2 patch 构建注意力
- Shifted Windows:W-MSA 在每个色块内构建全局注意力,如 [1,2,3,4],[5,6,7,8],首先 patch 往左上角移动 M/2 个单位,然后通过下移、右移,得到新的 patch 矩阵
- SW-MSA:Shifted Windows 完成后,根据原始 patch 是否相邻构建注意力,比如对于第一个窗的 [4,7,10,13] 在原始 patch 矩阵上相邻,所以构建无 Mask 的 4 x 4 的注意力矩阵,而 [8,3,14,9] 只能在 [8,3]、[14,9] 之间构建注意力,得到有 Mask 的 4 x 4 的注意力矩阵
- 通过移位重新构建注意力,可以让原始不同 Windows 之间得到交流,比如 W-MSA 上 [4,7] 没有构建注意力,而 SW-MSA 构建了它们之间的注意力,这类似 CNN,网络变深,感受野不断增强
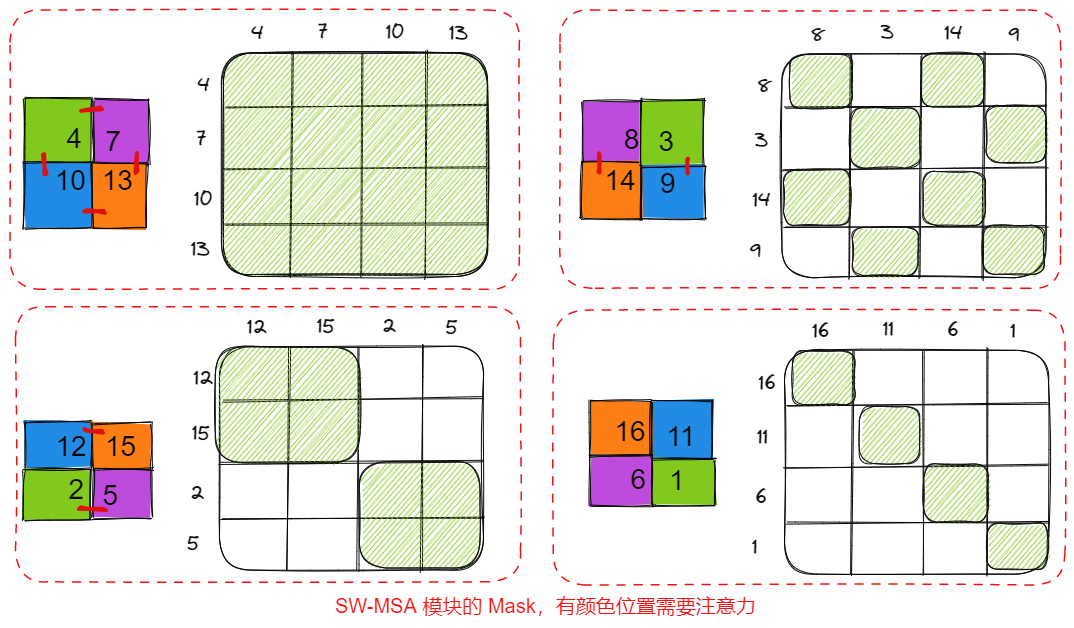
swin-trasformer 的 SW-MSA 模块的 Mask 生成?
![Drawing 2023-04-06 21.43.11.excalidraw]()
- 经过 SW-MSA 模块时,每个 Windows 内不完全是构建全局注意力,这就需要使用 Mask 去掉那些不需要的位置,总体上 Shifted Windows 得到的 Windows 分为 4 种,每种 Mask 矩阵对应如上
- ** 如何使用 Mask 呢?** 即在得到 QK^T 的指之后,将其乘上 Mask,对哪些无需计算注意力的位置赋予无穷小,使得 softmax 后趋向 0
swin-trasformer 与 vit 的区别?
- patch:swin-trasformer 的大小是 4 x 4,vit 是 16 x 16,不过 swin-trasformer 是指一个窗口内的
- emdedding:swin-trasformer 可选加,因为在计算 Attention 的时候做了一个相对位置编码
- cls_token:swin-trasformer 直接拿所有 token 的平均,作为 cls_token,而不是像 vit 使用单独的位置
参考资料: