SETR:Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
一直以来,分割都是在 FCN 的基础上搭建 Encoder-Decoder 进行的,基于 CNN 的缺点,虽然有设计方法取增大感受野、引入注意力机制,但还是没有背离这个规则。SETR 以 transformer 替代 CNN 的 Encoder 部分,将 2D 图片问题转为序列注意力构建问题,能在保持分辨率不变的情况下进行特征学习,最后使用 CNN 类似的金字塔结构还原分辨率
什么是 SETR?
![]()
- 一直以来,分割都是在 FCN 的基础上搭建 Encoder-Decoder 进行的,基于 CNN 的缺点,虽然有设计方法取增大感受野、引入注意力机制,但还是没有背离这个规则
- SETR 以 transformer 替代 CNN 的 Encoder 部分,将 2D 图片问题转为序列注意力构建问题,能在保持分辨率不变的情况下进行特征学习,最后使用 CNN 类似的金字塔结构还原分辨率
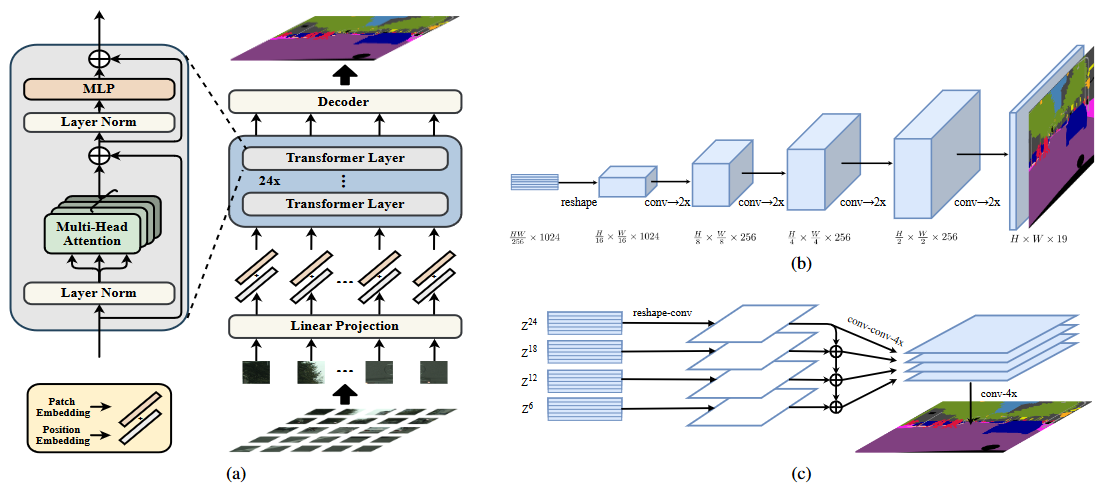
SETR 的模型结构?
![]()
- 输入:图像 (B, C,H, W),需要对图像进行 Patch 化,然后加入 Position embedding,得到 (B, S, L)
- Encoder:以 tansformer block 搭建,输入 (B, S, L),输出也是 (B, S, L)
- Decoder:将 Encoder 输出 (B, S, L) 转为 4D 数据 (B, H/16, W/16, C),然后使用 3 种分辨率上采样方法验证 Decoder 效果
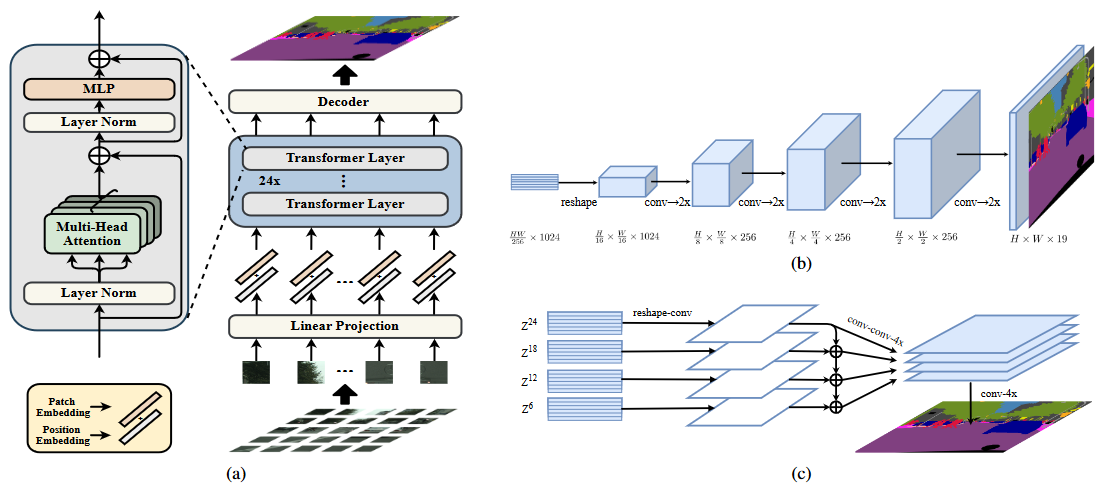
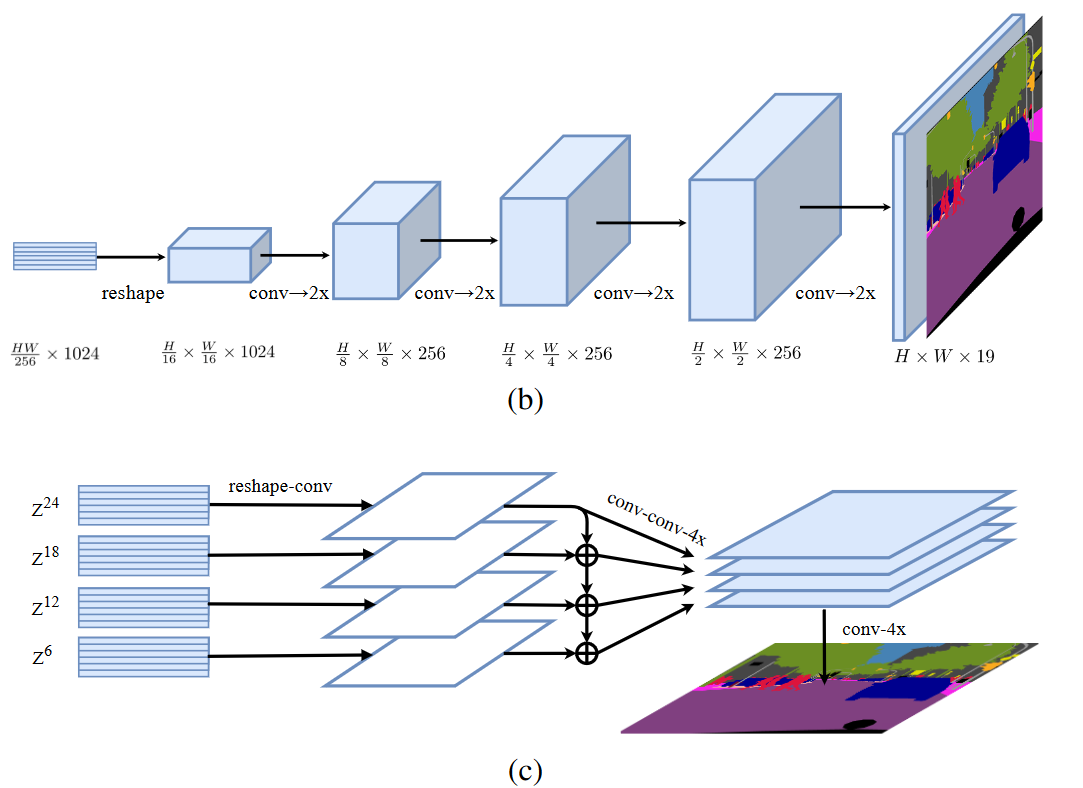
SETR 的 Decoder 设计?
![]()
- Encoder 输出 (B, H/16, W/16, C) 数据, SETR 设计了三种解码器上采样方法还原分辨率,实验证明 PUP 效果更好,最终采样该方法
- 最原始上采样 (Naive upsampling):通过简单的 1x1 卷积加上双线性插值来实现图像像素恢复
- 渐进式上采样 (Progressive UPsampling, PUP):一步到位式的上采样可能会产生大量的噪声,渐进式上采样则可以缓解这种问题。每一次上采样只恢复上一步图像的 2 倍,这样经过 4 次操作就可以回复原始图像
- 多层次特征加总 (Multi-Level feature Aggregation, MLA):这种设计跟特征金字塔网络类似
SETR 的注意力可视化?
![]()
- 第一张图:可视化 Encoder 的某些 tansformer block 的输出,可以看出在低层的 tansformer block 已经构建全局注意力关系
- 第二张图:可视化一个固定点 (patch) 与其他点 (patch) 的注意力关系,可以看出,tansformer block 确实构建了目标的注意力关系

参考: