DeepLabv2:Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
DeepLabv2 是在 DeepLabv1 基础上的优化,主要改进是引入空洞卷积金字塔池化 (ASPP)
什么是 DeepLabv2?
![DeepLabv2-20230408142622]()
- DeepLabv2 是在 DeepLabv1 基础上的优化,主要改进是引入空洞卷积金字塔池化
- 特征分辨率的降低:DeepLabv2 在最后几最大池化 (Max pooling) 层中去除下采样,取而代之的是使空洞卷积,以更高的采样密度计算特征映射
- 物体存在多尺度: 受到空间金字塔池化 (SpatialPyramidPooling,SPP) 的启发,提出空洞卷积金字塔池化,以多尺度的信息得到更强健的分割结果
- DCNN 的空间不变性: DCNN 中最大池化和下采样组合存在空间不变性 (Spatialinvariance),通过最终的 DCNN 层相应全连接条件随机场 (fully CRFs) 结合来克服这个问题
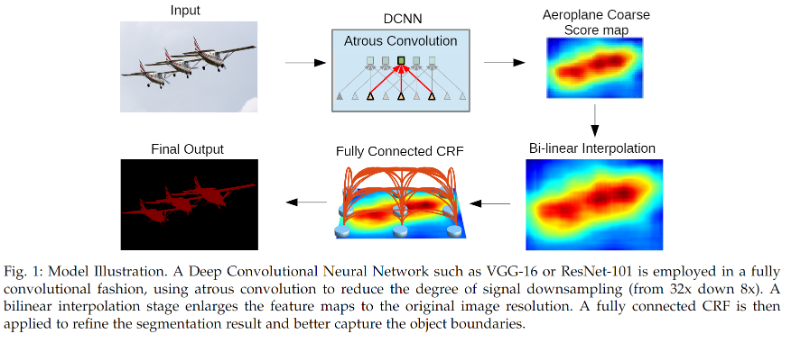
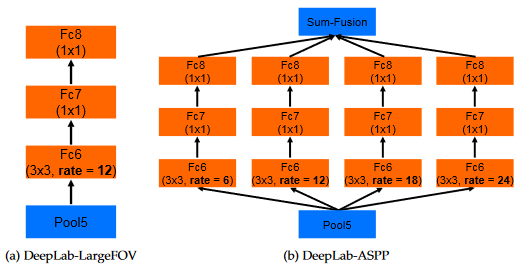
DeepLabv2 的网络结构?
![Drawing 2023-02-24 11.51.36.excalidraw]()
- 与 DeepLabv1 的网络结构相差不大,主要有 2 点改进:(1)主干网络使用 RestNet 替代 VGG16;(2)使用 空洞卷积金字塔池化 (ASPP) 解决多尺度的问题
DeepLabv2 的损失函数?
- CNN 的每个输出 map (原图 1/8 大小) 空间位置信息与原始 groud truth 标签(下采样为 1/8)交叉熵损失 (CrossEntropyLoss)
什么是空洞卷积金字塔池化 (Atrous Spatial Pyramid Pooling, ASPP)?
![DeepLabv2-20230408142623]()
- 在空间金字塔池化 (SpatialPyramidPooling,SPP) 的基础上,结合空洞卷积 (Atrousconvolution) 可在不丢失分辨率(即不进行下采样)的情况下扩大卷积核的感受野,有助于考虑不同的物体比例
- 根据卷积的输出计算 torch.nn.Conv2d,对于卷积核为 3x3 的空洞卷积,只要其 dilation=padding,stride=1,卷积层输出的大小保持不变
1
2
3
4
5
6
7>>> input = torch.randn(5, 8, 56, 128)
>>> m = torch.nn.Conv2d(8, 33, (3, 3), padding=(4, 4), dilation=(4, 4));
>>> m(input).shape
torch.Size(\[5, 33, 56, 128])
>>> m = torch.nn.Conv2d(8, 33, (3, 3), padding=(24, 24), dilation=(24, 24));
>>> m(input).shape
torch.Size(\[5, 33, 56, 128])
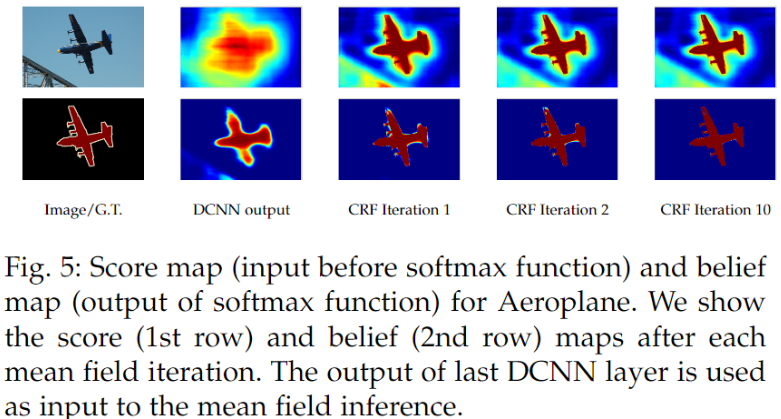
DeepLabv2 的如何训练全连接条件随机场 (fully-connected CRF)?
![DeepLabv2-20230408142623-1]()
- 通过 10 倍的 CRF,飞机周围不同颜色的小区域变得平滑起来
- CRF 是一个后阶段的处理过程,它使 DeepLabv1 和 DeepLabv2 变为不是端到端的学习框架
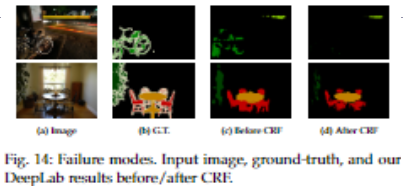
DeepLabv2 的缺点?
![DeepLabv2-20230408142624]()
- 不能捕捉物体的微妙边界,如自行车和椅子。由于一元术语不够可靠,CRF 后处理甚至无法恢复细节
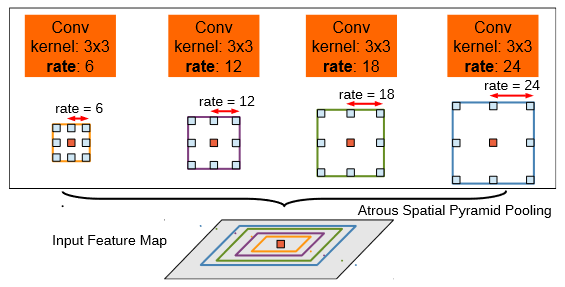
DeepLabv2 与 DeepLabv1 使用空洞卷积的差异?
![DeepLabv2-20230408142624-1]()
- DeepLabv1 模型使用了单分支的空洞卷积
- DeepLabv2 模型使用了多分支的并行空洞卷积,最终组合空洞卷积金字塔池化 (ASPP)
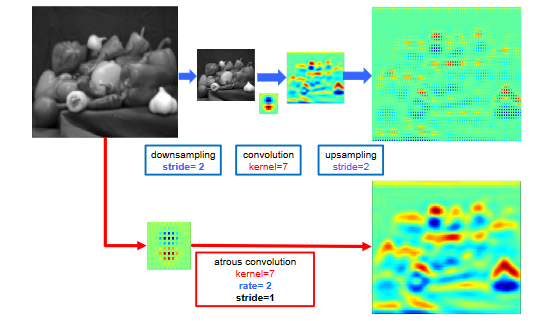
空洞卷积与标准卷积的效果差异?
![DeepLabv2-20230408142625]()
- 空洞卷积在原图上直接进行卷积操作,这样省去了下采样和上采样的操作,而且计算量不变的情况下(卷积核中那些为 0 的系数在反向梯度计算中没有传递性),能得到更大的感受野,也就是说能获取到更多的密集特征,尤其是像素的边界信息,对比两个分支的输出 feature map 可以得到印证
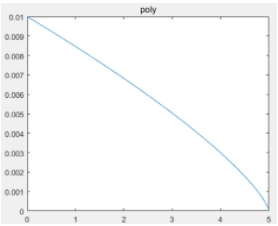
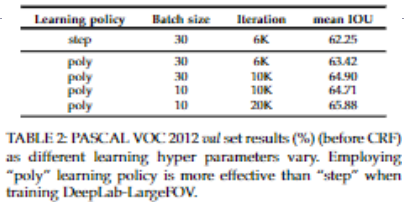
deeplabv2 使用学习率衰减对结果有什么影响?
- 衰减策略: 其中 power=0.9
![]()
- 使用 poly 策略比固定的 step 策略效果要好
![DeepLabv2-20230408142625-2]()