DeepLabv3+:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
在 DeepLabv3 的基础上,引入解码器 (Dncoder) 提升语义分割的精度
什么是 DeepLabv3+?
![Deeplabv3Plus-20230408142741]()
- 语义分割关注的 2 个问题:(1) 实例对象多尺度问题;(2) feature 分辨率下降导致预测精度降低,而造成的边界信息丢失问题。 DeepLabv3] 改进 ASPP 结构解决了问题 1,deeplab v3 + 通过编码器解决问题 2
- 在 DeepLabv3 的基础上,引入解码器 (Dncoder) 提升语义分割的精度;引深度可分离卷积提高语义分割的速度
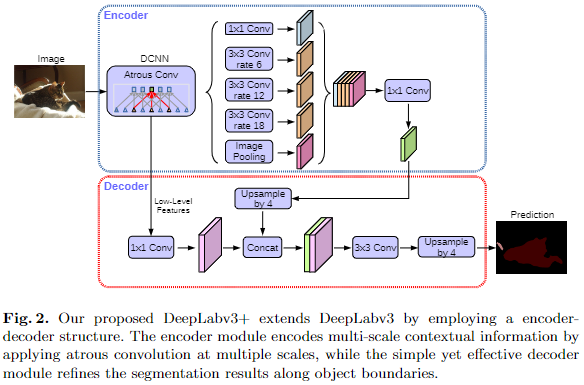
DeepLabv3 + 的网络结构?
![Drawing 2023-02-24 11.51.36.excalidraw]()
- Encoder:(1) 带空洞卷积的 DCNN,可以采用常用的分类网络如 ResNet、Xception;(2) 基于 DeepLabv3 改进 ASPP,用于引入多尺度信息
- Decoder:其将底层特征与高层特征进一步融合,提升分割边界准确度
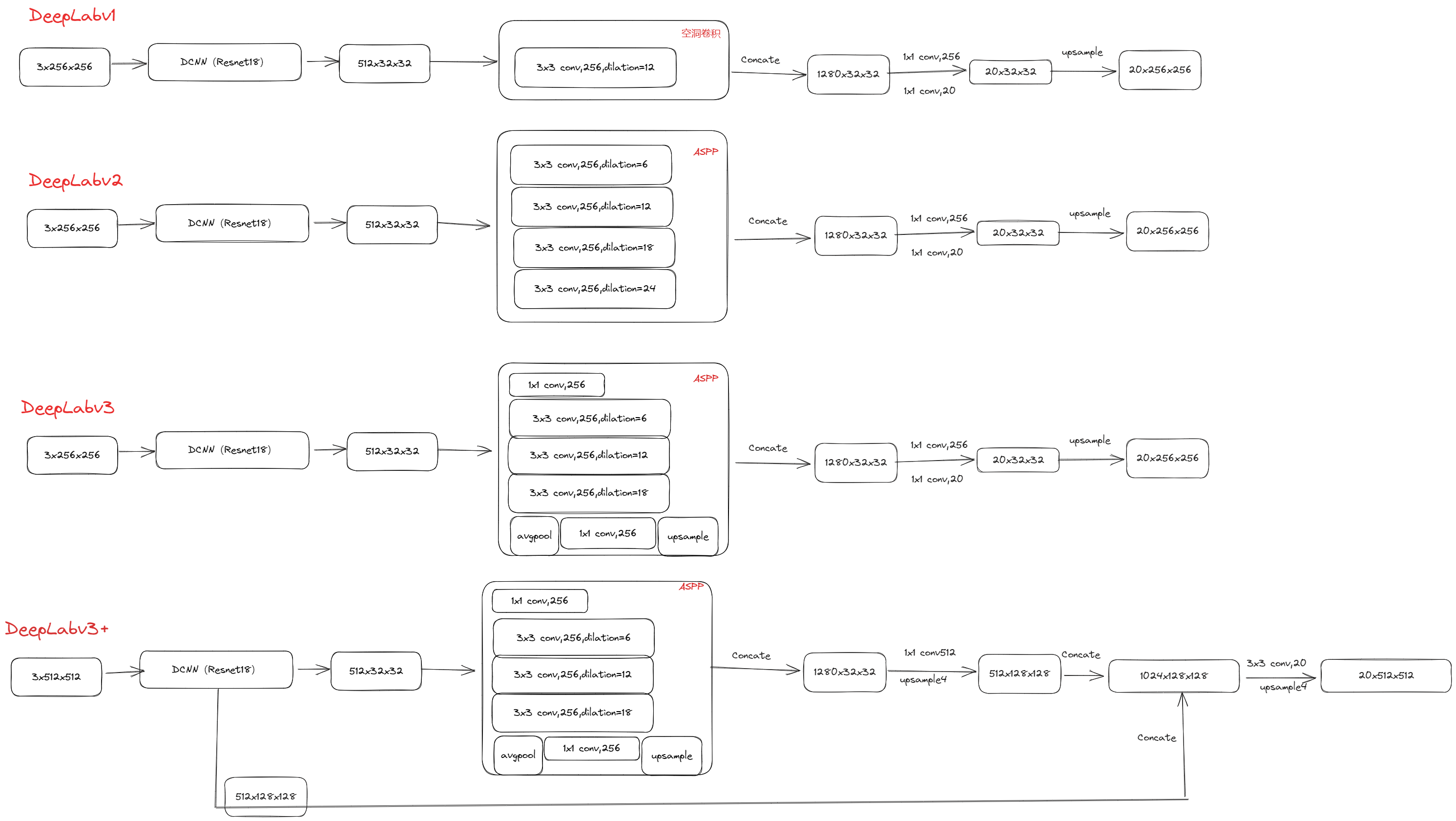
Deeplabv3 + 的解码器 (Dncoder) 的使用?
![Deeplabv3Plus-20230408142741]()
- DeepLabv3 网络输出解码: 经改进的 ASPP 得到 C3 或 C4 的特征图,然后 1 x 1 卷积调整通道至类别数量,最后直接上采样 8 倍或 16 倍还原分辨率,这是一种非常暴力的 decoder 方法,不利于得到较精细的分割结果
- Deeplabv3 + 网络输出解码: 借鉴了 EncoderDecoder 结构,引入了新的 Decoder 模块,首先将 encoder 得到的上采样 4x 的特征,然后与 encoder 中对应大小的低级特征 concat,为了防止 encoder 得到的高级特征被弱化,先采用 1x1 卷积对低级特征进行降维,两个特征 concat 后,再采用 3x3 卷积进一步融合特征,最后再 4 x 上采样得到与原始图片相同大小的分割预测
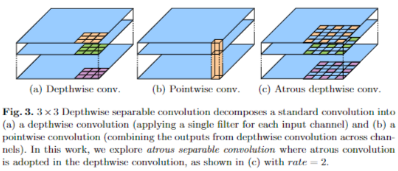
Deeplabv3 + 论文中的空洞深度分离卷积?
![Deeplabv3Plus-20230408142742]()
- 深度可分离卷积中的通道卷积改空洞卷积即可,减少计算量的同时,扩大感受野
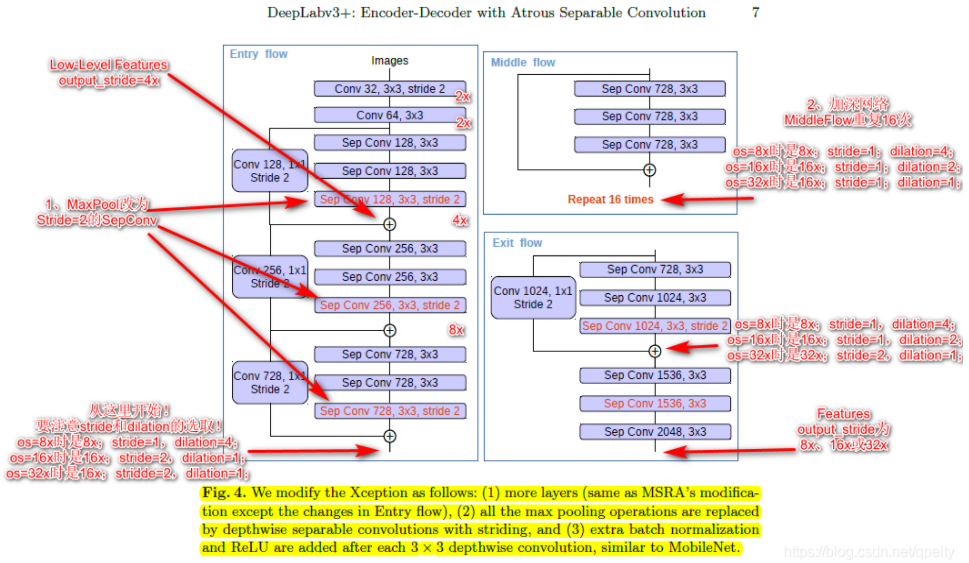
Deeplabv3 + 如何改进 Xception?
![]()
- (1)参考 MSRA (微软亚洲研究院) 的修改 ,增加了更多的层
- (2)所有的最大池化层使用 stride=2 深度可分离卷积 (depthwise separable convolution) 替换,并将其中的通道卷积 (depthwise convolution) 改空洞卷积 (Atrous convolution)
- (3)与 MobileNet 类似,在 3x3 depthwise convolution 后增批规范化 (Batch Normalization,BN) Relu