DeepLabv1:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
通过空洞卷积扩大感受野,使得分割可以处理大尺寸目标,通过 CRF 后处理模型输出,使得结果更加合理
什么是 DeepLabv1?
![DeepLabv1-20230408142527]()
- DeepLabv1 认为 DCNNs 在图像标记任务中存在 3 个问题:特征分辨率下降、CNN 的空间不变性 (Spatial invariance)、 物体存在多尺度
- 特征分辨率下降: 下采样可以增大感受野,但会导致分辨率的下降,丢失了细节信息,使空洞卷积 解决该问题,在不改变特征图的大小同时扩大感受野
- CNN 的空间不变性:根本是源于重复的池化和下采样,使全连接条件随机场 (fully CRFs) 解决了空间不变性的问题
- 物体存在多尺度: 原始方法是将图片缩放成不同尺寸,汇总特征得到结果,但是增加了计算成本,DeepLabv1 通过将不同层的 featrue map 拼接到一起缓解这个问题,DeepLabv2 在提出空洞卷积金字塔池化 (AtrousSpatialPyramidPooling,ASPP) 解决该问题
- 总结:通过空洞卷积扩大感受野,使得分割可以处理大尺寸目标,通过 CRF 后处理模型输出,使得结果更加合理
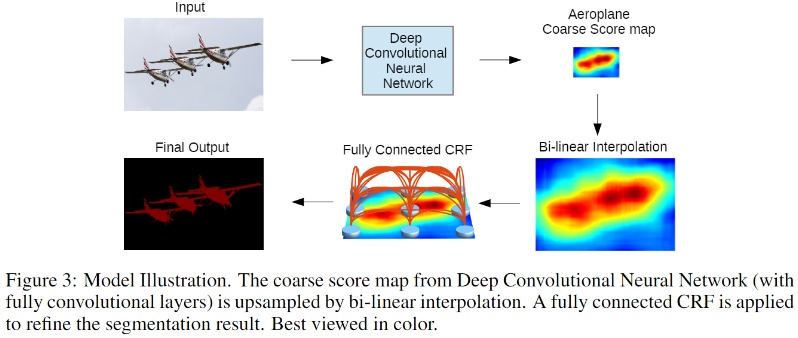
DeepLabv1 的网络结构?
![Drawing 2023-02-24 11.51.36.excalidraw]()
- VGG-16,将全连接层的权重转成了卷积层的权重,构成全卷积网络,进行了 8 倍下采样
- 8 倍下采样后直接进行 CRF 修正结果
DeepLabv1 的损失函数?
- CNN 的每个输出 map (原图 1/8 大小) 空间位置信息与原始 groud truth 标签(下采样为 1/8)交叉熵损失 (CrossEntropyLoss)
DeepLabv1 训练步骤?
- (1)训练 DCNN:此时输出是 CRF 的一元势函数(像素概率),在训练时 CRF 时保持固定
- (2)训练 CRF:在对 DCNN 做 fine-tune 后,使用公式对 CRF 做交叉验证,在 100 个图像上,给定初始搜索范围,采用从粗到细的寻找策略,寻找到最佳的 CRF 系数
DeepLabv1 如何做多尺度预测?
- 在输入图片和前四个 max-pooling 的输出都插入分支,并将这些分支输出与主干网络的输出 concat 到一起然后再进行像素级分类
![]()
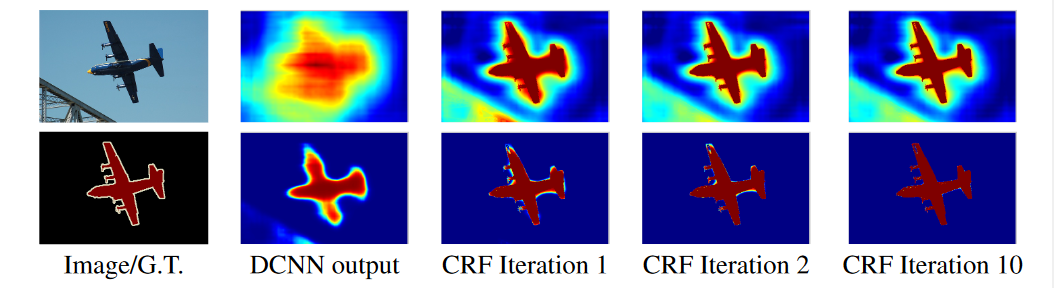
DeepLabv1 如何使用全连接条件随机场 (Fully Connected CRF)?
![DeepLabv1-20230408142550]()
- 通过 10 次迭代全连接条件随机场 (fully CRFs),飞机周围边沿更加清晰
- 注意:CRF 是一个后阶段的处理过程,它使得 DeepLabv1、DeepLabv2 变为非 end-to-end
什么是 CNN 的空间不变性 (Spatial invariance)?
- 空间不变性:对位置信息不敏感,比如对细节信息不敏感、抽象度较高的任务(图像分类) , 对于同一张图片进行空间变换(旋转不变性 (rotationalinvariance)、平移不变性 (translationalinvariance))其图像分类的结果是不变的
- 空间不变性对图像细节敏感、抽象度较低的任务(如 语义分割、姿态估计等)有干扰,因为任务的结果会随着图像空间变化而改变
空洞卷积和下采样有什么区别?
- 池化 (Pooling):好处是缩小特征图尺寸,增大感受野;坏处:分辨率下降,细节信息丢失
- 空洞卷积 (Atrous convolution):增大感受野,同时分辨率不下降
参考: