DeconvNet:Learning Deconvolution Network for Semantic Segmentation
第一个基于解码器 - 编码器设计的网络,编码阶段使用池化提取特征,解码阶段使用反池化、反卷积还原分辨率
什么是 DeconvNet?
![DeconvNet-20230408142443]()
- 第一个基于解码器 - 编码器设计的网络,编码阶段使用池化提取特征,解码阶段使用反池化、反卷积还原分辨率
- 为了解决 FCN 无法分割过大、过小目标的问题,DeconvNet 通过 EdgeBox 先获取图片目标的获选框,将图片多目标语义分割问题分解为单目标的语义分割问题
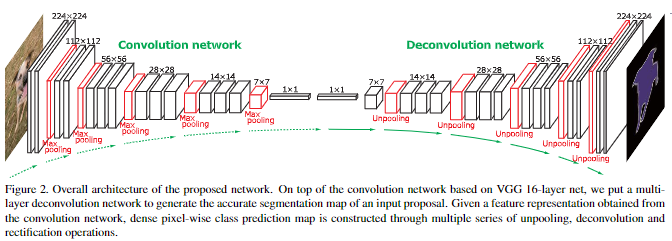
DeconvNet 的网络结构?
![DeconvNet-20230408142443]()
- 编码器: 使用 VGG-16(去除分类层),把最后分类的全连接层去掉,在适当的层间应用 Relu 和 Maxpooling。增加两个全连接层(1x1 卷积)来强化特定类别的投影
- 解码器:编码器的镜像,主要包反卷积 (deconvolution) 和反池化 (UnPooling)
DeconvNet 的损失函数?
- 输入标签的 hxw,分割后得到的输出是 hxwxC,其中 C 为每个像素的类别概率
- 将 hxw 拉成一维,如果网络输出包括 softmax,使交叉熵损失 (CrossEntropyLoss) 计算损失
DeconvNet 的训练过程?
- 第一阶段: 用简单的样本(每个样本包含一个目标,且该目标位于中央)进行训练
- 第二阶段: 用复杂的、具有挑战性、重叠的样本在第一阶段训练好的模型上 fine-turning
DeconvNet 如何得到最后输出?
- 合并概率图:DeconvNet 预测多个候选框的像素类别概率后,将获选框概率合并到原始大图上,规则有两个,相应位置多个获选框的同类概率最大值或平均值
- 进一步加工:获得大图尺度的概率图后,使用 Softmax 得到得到类别的条件概率映射。最后使用全连接条件随机场 (fully CRFs) 得到最终的输出映射
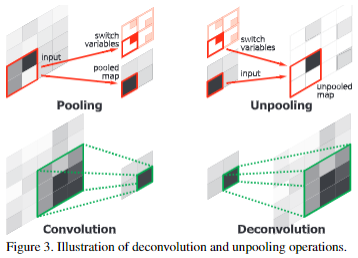
在 DeconvNet 论文中,反卷积和反池化有什么差异?
![DeconvNet-20230408142509]()
- 反卷积 (deconvolution):低层反卷积层可获得目标的位置,形状等粗略信息,高层反卷积层可获得更精细的信息
- 反池化 (UnPooling):和反卷积目的不同,反池化是通过回溯原始位置来获得更好的结构细节信息,反卷积趋向于获取特定物体类别的形状
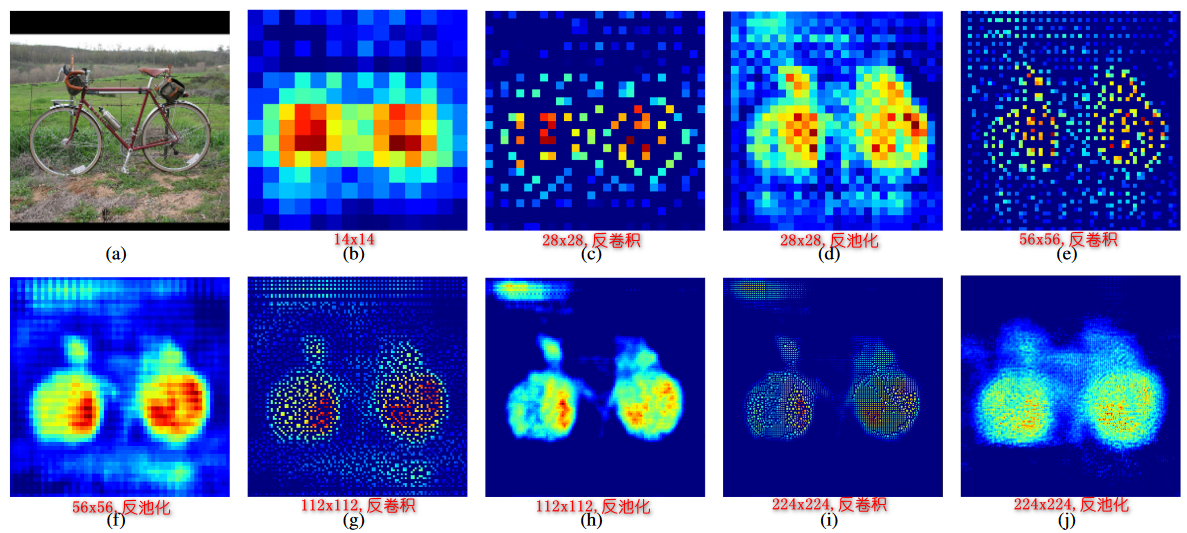
DeconvNet 如何进行上采样?
![DeconvNet-20230408142509-1]()
- pooling:的时候用 switch variables 记录 Maxpooling 操作得到的 activation 的位置
- Unpooling:利用 switch variables 把它放回原位置,从而恢复成 pooling 前同样的大小
DeconvNet 论文中,总结 FCN 的缺点有哪些?
- 对于大于或者小于感受野的目标,就可能被分裂或者错误标记
![DeconvNet-20230408142509-2]()
- 对于小目标来说,经常会被忽略掉,被当作了背景
![DeconvNet-20230408142510]()


DeconvNet 与 FCN 的差异?
- FCN 里面对各层的输出只做了一次反卷积 (deconvolution),然后再整体做双线性插值
- DeconvNet 上采样交替使反卷积 (deconvolution) 和反池化 (UnPooling) ,通过堆叠上采样,形成对称的网络