DeepLabv3:Rethinking Atrous Convolution for Semantic Image Segmentation
优化 DeepLabv2 的 ASPP 模块,并且抛弃 CRF,实现端到端的语义分割
什么是 DeepLabv3?
![DeepLabv3-20230408142639]()
- DeepLabv1 DeepLabv2 都是使空洞卷积提取密集特征来进行语义分割,DeepLabv3 依然是在空洞卷积做文章,但是采用多比例的空洞带孔卷积级联或并行来捕获多尺度背景
- 抛弃全连接条件随机场,实现 end-to-end 语义分割
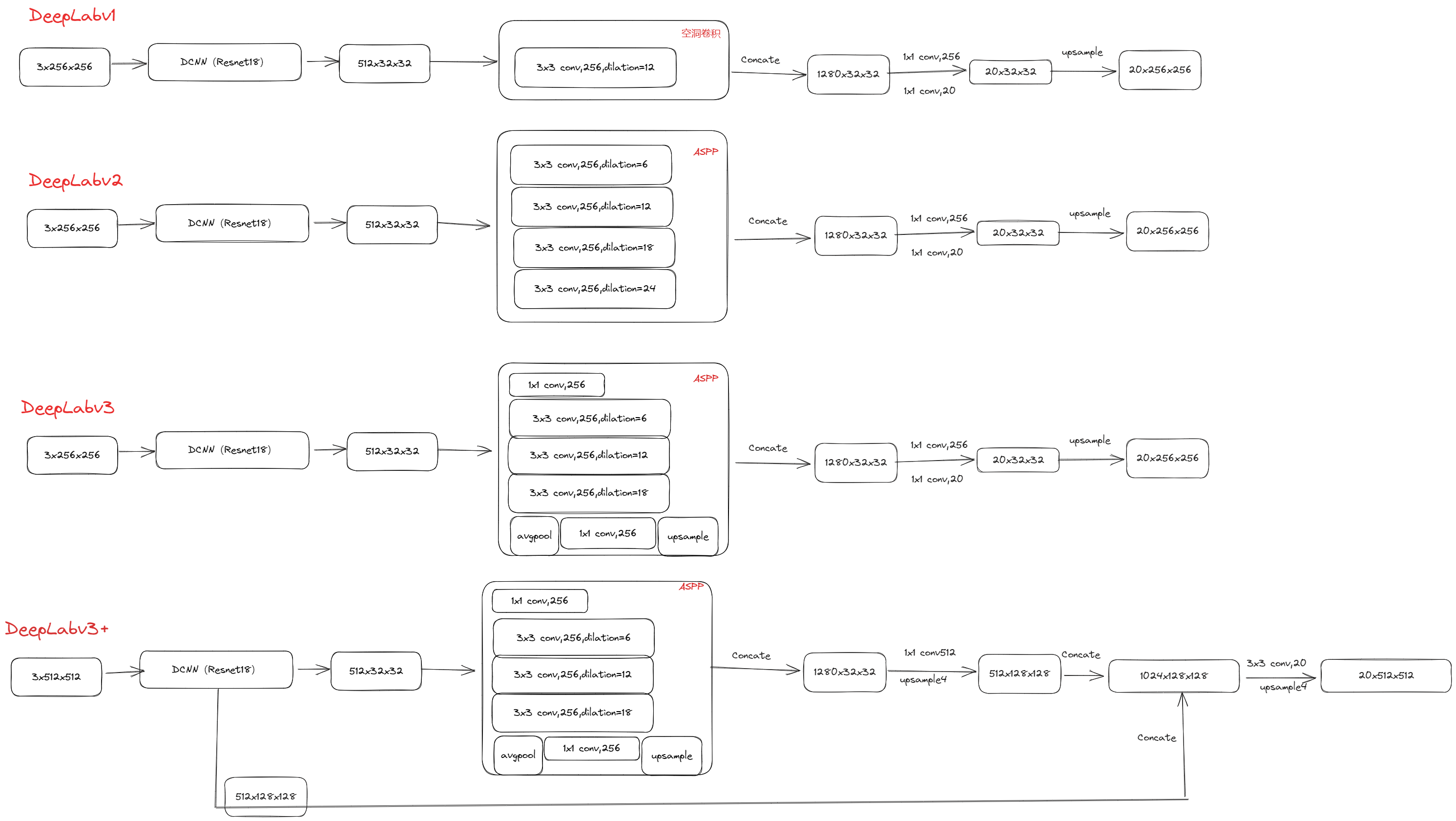
DeepLabv3 的网络结构?
![Drawing 2023-02-24 11.51.36.excalidraw]()
- (1) 首先使用 resnet18 网络进行的特征提取,得到的是 512x32x32 的特征图
- (2) aspp5 个分支都是 256x32x32 的特征图,将它们拼接在一起,得到 1280x32x32 的特征图,再经过两次卷积得到 20x32x32 的特征图
- (3) 最后对 20x32x32 的特征图进行一次上采样操作,得到 20x256x256 的特征图,即最后我们需要的输出
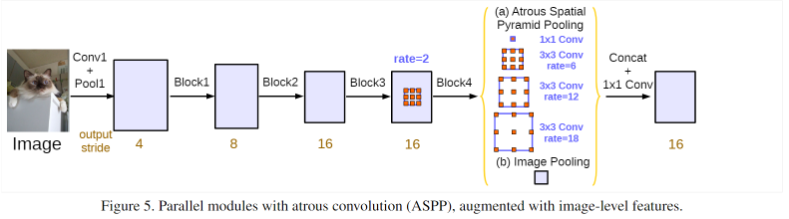
DeepLabv3 的 ASPP 模块?
![DeepLabv3-20230408142639]()
- BackBone:Image 经过多个 block 的操作得到 output_stride=16 的特征图,经过一个 rate 为 2 的空洞卷积经过 block4,然后再经过改进的 ASPP ,包括 2 部分:
- (a) 空洞卷积部分: 使用 1x1conv、rate 为 {6,12,18} 的 3 x 3 空洞卷积
- (b) image-level features:经过一个全局平均池化,接 256 个 1x1 的卷积,然后使用双线性插值上采样恢复至 output_stride=16
- 拼接 (a)、(b) 得到输出得到 ASPP 输出,和 DeepLabv2 的空洞卷积金字塔池化 (ASPP) 相比,有 3 个不同:(1) 增加 1 x 1 卷积;(2) 去掉 rate=24 的空洞卷积;(3) 增加 Image Pooling