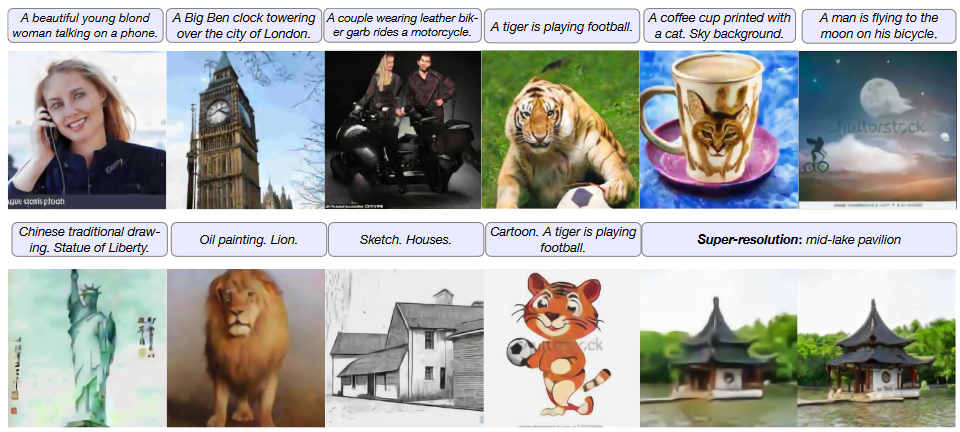
Cogview
文本编码 +(图像编码)-> 自回归 -> 新图像编码 ->dVAE decoder-> 条件图片,文生图
什么是 Cogview ?
![]()
- 结合 VQVAE 和 Transformers 的文本到图像的生成框架
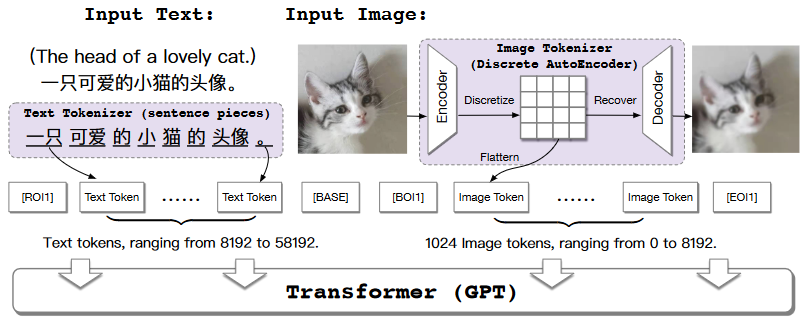
Cogview 的训练过程?
![]()
- 1)文本 token:首先将文本部分转换成 token,利用的是已经比较成熟的 SentencePiece 模型
- 2)图像 token: 然后将图像部分通过一个离散化的 AE (Auto-Encoder) 转换为 token,
- 3)训练 transformer:文本 token 和图像 token 拼接到一起,之后输入到 GPT 模型中学习生成图像,如图在每个序列中添加四个分隔符标识 [RO|1]、[BASE]、[BO|1]、[EO|1],指示文本和图像的边界
Cogview 的推理过程?
- 1)文本 token :利用 SentencePiece 模型得到文本 token
- 2)图片 token:仅使用文本 token + 标识符 [BO|1] 生成图片的第一个 token,然后利用文本 token + 第一个图片 token 生成第二个图片 token,依次类推,直到生成固定次数,得到需要的图片 token
- 3)VAE Decoder:输入图片 token,生成图片
训练过程,Precision Bottleneck Relaxation (PB-Relax) 如何保持稳定?
- 在分析了训练的动态性之后,作者发现溢出(NAN loss)总是发生在两个瓶颈操作上,即最后一层 LayerNorm 或注意层
- 1)在深层网络中,LayerNorm 中输出的值可能会爆炸到 10000+,导致溢出。解决的方法是令 LayerNorm (x)=LayerNorm (x/max (x)),即通过除以 x 的最大值来减小爆
- 2)注意力分数明显大于输入元素,因此将注意力改
训练过程,Sandwich LayerNorm (Sandwich-LN) 如何保持稳定?
![]()
- Transformer 中的 LayerNorm 对于稳定训练至关重要。LayerNorm 的输出为,基本上与 x 的隐藏维度大小的平方根成比例,但有些维的输入值明显大于其他维,会导致对应维的输出值加大,在残差分支中,这些较大的值被放大并放回到主支中,加剧 transformer 层的现象,最后导致深层的 value explosio
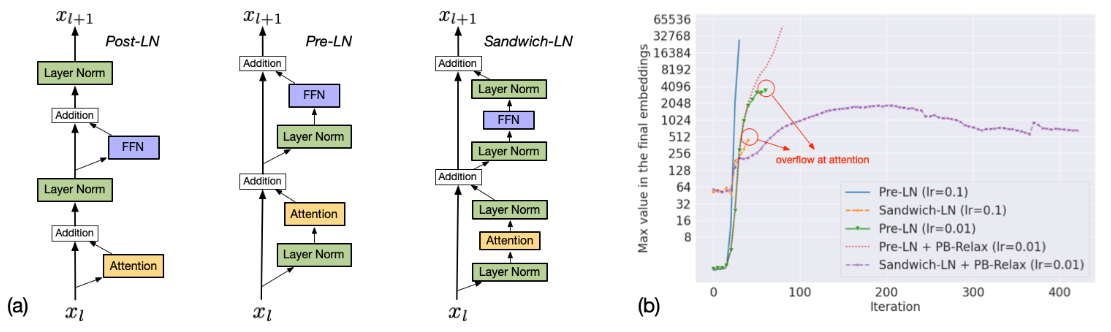
- 因此,提出了 Sandwich LayerNorm,** 其在每个残差分支结束时添加一个新的 LayerNorm。** 该残差分支确保了每层的输入值的比例在一个合理范围内,帮助模型更好的收敛
参考: