Cogvideo
首先生成多个关键帧,然后在帧之间采样,生成视频
什么是 CogVideo?
![]()
- 首个开源的文本生成视频模型,支持生成 480 x 480 的 32 帧图片,播放帧率是 8 帧 / 秒,共计 4 秒的视频
- CogVideo 的训练主要基于本文提出的多帧分层生成框架,具体来说就是先根据 CogView2 通过输入文本生成几帧图像 (关键帧),然后再根据这些图像进行插帧提高帧率完成整体视频序列的生成
- 为了更好的在嵌入空间中对齐文本和视频片段,提高模型对文本预训练知识的迁移,作者提出了一种双通道注意力机制来提高性能
- 为了应对模型超大的参数和长视频序列的存储压力,作者将 Swin Transformer 中的滑动窗口引入到了本文的自回归视频生成任务中

CogVideo 的原理?
![]()
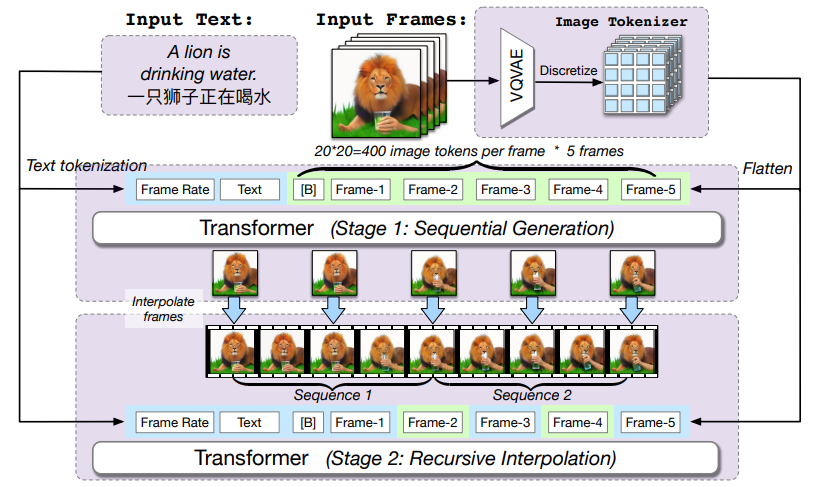
- 框架的输入序列包括目标帧率大小、文本数据和帧的标记符号
- 多帧率分层生成是一个递归过程,具体而言,生成管道包括顺序生成阶段和递归插值阶段
- Stage 1 阶段,在给定帧率条件下按照输入文本的顺序生成 T 帧图像,模型序列的生成第一帧、然后拼上第一帧来自回归生成第二帧,直接预测完所有的帧
- Stage 2 阶段,上一阶段生成的图像帧作为双向注意力区域重新输入到模型中,模型会根据上下文语义来对输入帧序列之间进行插帧生成
CogVideo 的双向注意力?
![]()
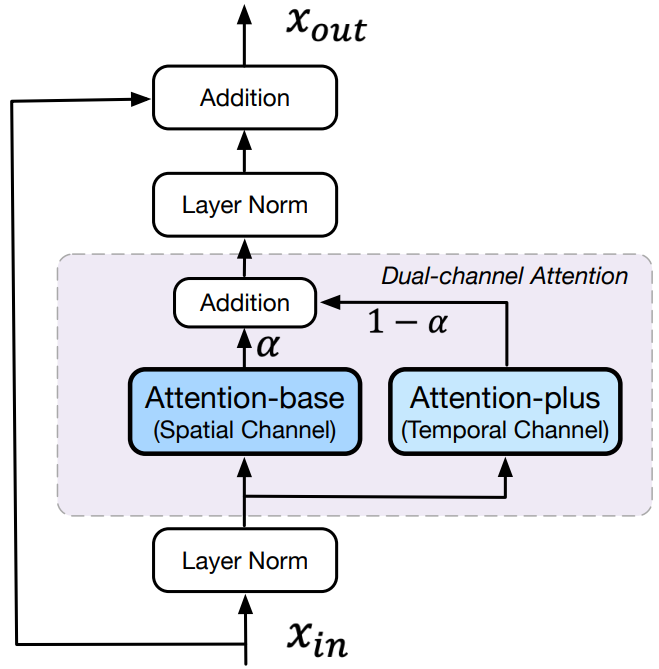
- 为了更好的在嵌入空间中对齐文本和视频片段,提高模型对文本预训练知识的迁移,作者提出了一种双通道注意力机制来提高性能,一个注意空间上,一个注意时序上的,分别称为 attention-base 和 attention-plus,从而让模型掌握空间和时序的推理能力
- 即在每个 Transformer 层的预训练 CogView 2 中添加一个新的时空注意通道。CogView 2 中的所有参数都在训练中冻结,只有新添加的注意力层中的参数(上图中的 attention-plus)是可训练的
CogVideo 的 Swin 注意力?
![]()
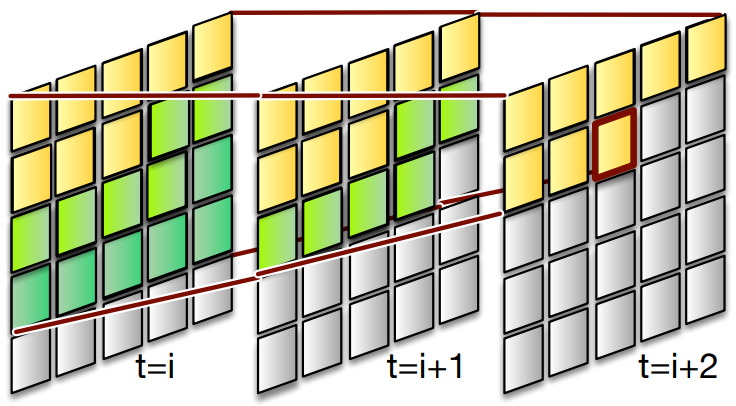
- 原来的 Swin 注意力只适用于非自回归场景,作者通过在移动窗口中应用自回归注意力 mask 将其扩展到自回归和时间场景
- Swin 注意力为在不同帧的远距离区域进行并行生成提供了机会,这进一步加速了自回归生成。特定 token 的生成依赖于 :1)自回归 mask,如果当前帧被标记有自回归 mask,那模型会被强制只能先关注当前帧之前和之后的帧;2)滑动窗口,滑动窗口也给模型规定了一部分优先被处理的区域
参考:
- 这个 “1 句话生成视频” AI 火了:支持中文输入,分辨率达到 480×480,清华 & 智源出品 - 知乎
- 清华 & BAAI 唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型 CogVideo,含 94 亿超大参数量!代码即将开源! - 知乎
- CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers - 论文分享 - 知乎
- 清华 & BAAI 唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型 CogVideo,含 94 亿超大参数量!代码即将开源!…_我爱计算机视觉的博客 - CSDN 博客
- 动动嘴就能出片?清华联合 BAAI 提出第一个开源预训练文本视频生成模型 CogVideo - 知乎