CogView2:Faster and Better Text-to-Image Generation via Hierarchical Transformers
通过 mask 掉注意力,避免自回归生成速度慢的问题
文本编码 +(图片编码)-> 自回归 -> 新图像编码 ->dVAE decoder-> 条件图片,文生图
什么是 CogView 2 ?
![]()
- 基于 Transformer 的文本到图像模型,通过分层 Transformer 和局部并行自回归生成解决传统自回归模型的以下问题
- 1)生成缓慢:自回归模型因其逐标记生成的性质,导致无法使用机器的并行能力,CogView2 分层设计使我们能够只关心高分辨率级别的局部一致性。这样,就可以利用局部注意力来减少训练代价
- 2)单向性:以前的自回归模型都是固定一个生成方向,无法感知双向特征,CogView2 在预训练期间,掩蔽补丁预测任务训练 CogLM 处理双向上下文,使其易于适应双向任务
- 3)昂贵高分辨率:Transformers 的自注意训练成本是 token 的平方,所以常常只能使用较少的 token,CogView2 通过局部并行自回归生成可以将模型运行时间从 3,600 次减少到 6 次(仅 1/600),显着加速高分辨率图像的生成。CogView2 比 CogView(具有滑动窗口超分辨率)快约 10 倍

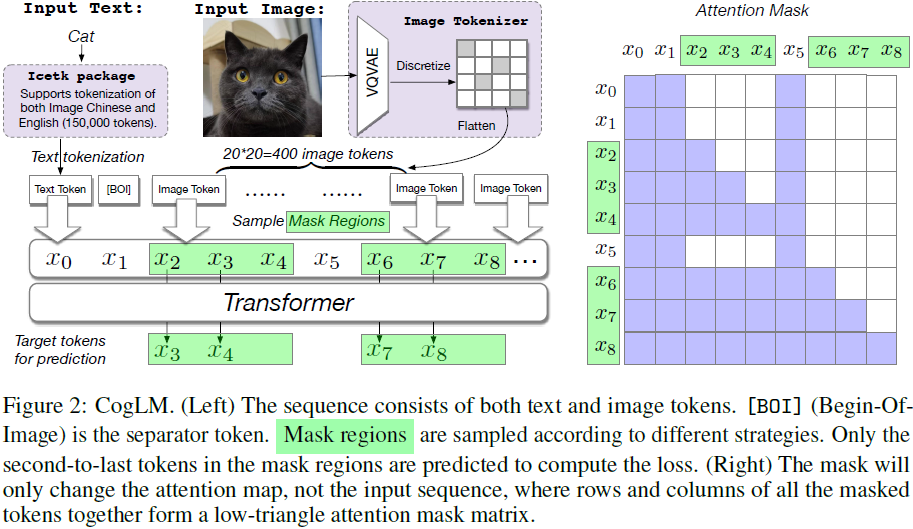
CogLM 的掩蔽策略?
![]()
- 跨模态通用语言模型(Cross-Modal general Language Model,CogLM)掩蔽了文本和图像标记序列中的各种类型的标记,并学习自回归地预测它们
- (1) 如果掩蔽所有图像标记,则任务在执行文本到图像生成时变得与原始 CogView
- (2) 如果随机掩蔽图像标记的补丁,它的工作原理类似于 MAE 的填充任务
- (3) 如果掩蔽文本标记,任务就变成图像标题
- 注意:在 mask 区域内部,模型是按照自回归的方式从左到右进行预测
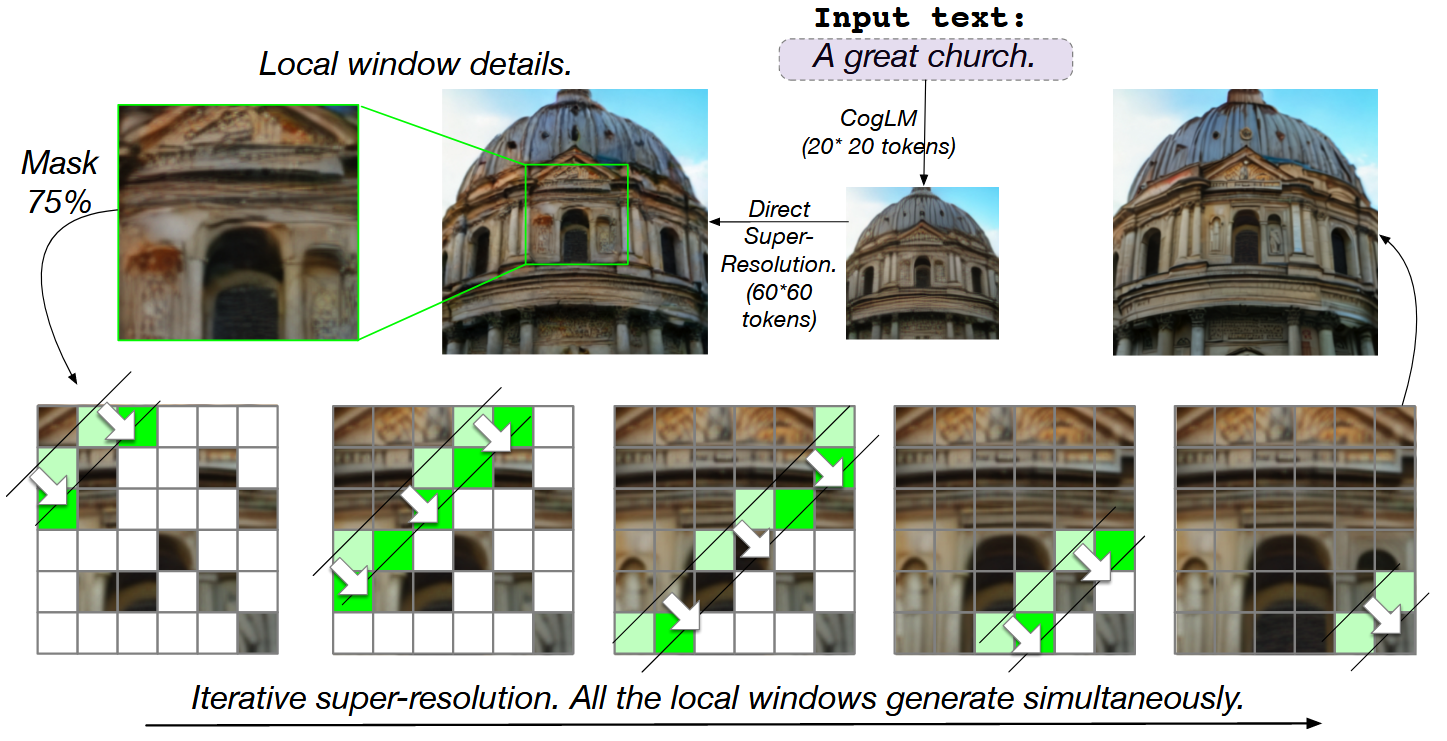
CogView 2 的分层原理?
- 1)首先,使用预训练的 CogLM 生成一批低分辨率图像(CogView 2 中的 20 * 20 标记),然后(可选)根据 CogLM 图像标题的困惑度过滤掉坏样本,这就是 CogView 中引入的后选择方法
- 2)直接超分辨率:生成的图像通过从预训练的 CogLM 微调的直接超分辨率模块映射为 60 * 60-token 图像。我们使用定制的 CUDA 内核实现的局部注意力来减少训练代价。此步骤生成的高分辨率图像通常纹理不一致且缺乏细节
- 3)超分辨率模块:这些高分辨率图像通过另一个迭代超分辨率模块进行精练,该模块是根据预训练的 CogLM 进行微调的。大多数标记以 ** 局部并行自回归(local parallel autoregressive,LoPAR)** 方式重新掩蔽和重新生成,这比原始自回归生成要快得多
CogView 2 的直接超分辨率、局部并行自回归(local parallel autoregressive,LoPAR)?
![]()
- 预训练的 CogLM 可以从文本生成图像,但分辨率仅为 20 x 20 标记(160 x 160 像素)。短序列是有意为之,以实现快速生成
- 直接超分辨率:将预训练的 CogLM 微调为编码器 - 解码器架构。编码器的输入是生成的图像标记的 20 x20 序列,解码器的输入只是 60 x 60 的 Mask 序列
- 超分辨率模块:在迭代超分辨率期间的每个快照中,同时生成相同颜色的所有标记。所有本地窗口并行工作
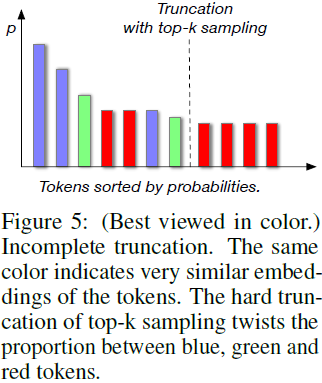
CogView 2 的分簇采样技术?
![]()
- 在自回归生成中,对标记的预测分布的采样策略至关重要。Top-k 或 top-p(核心,nucleus)采样是最常见的策略,但会遇到不完整截断问题
- 为了解决不完整抽样问题,我们提出分簇采样。我们根据 VQVAE 中的向量,通过 K 均值将 20,000 个标记分为 500 个簇。在采样过程中,我们首先根据簇中标记的概率之和使用 top-k 采样对簇进行采样,然后在簇中进行采样。簇中的所有标记被视为一个整体,并将被过滤或保留在一起,从而缓解不完整截断问题
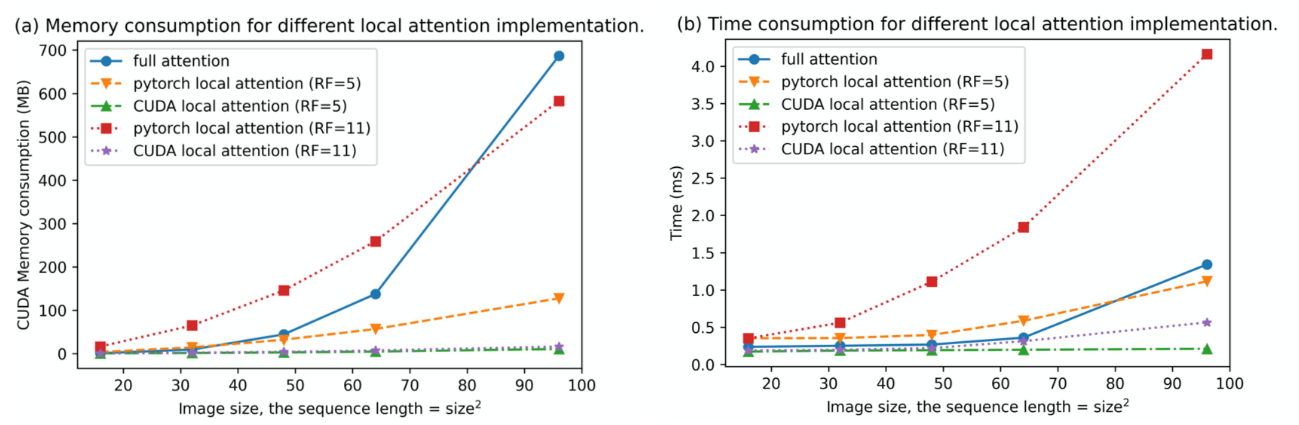
CogView 2 的局部注意力?
![]()
- 基于 CUDA 内核的局部注意力、完全注意力和基于展开,操作的 Pytorch 实现之间的比较。基准测试中的隐藏大小为 64
参考: