ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models
通过 ControlNet 可以向训练好的生成模型注入控制条件,这些条件可以是 Seg、Sketch、pose 等
(图片)+ 条件 ->DDPM-> 条件图片,条件图片
什么是 ControlNet ?
![]()
- 一种用于控制已经训练好的扩散大模型的技术,所谓控制,是指向文生图模型指定更多的条件,比如边缘图、分割图、关键点等
- ControlNet 以端到端的方式学习特定于任务的条件,即使训练数据集很小 (< 50k),学习也是稳健的
- 训练 ControlNet 与微调扩散模型是一样的快,并且该模型可以在个人设备上进行训练。或者,如果强大的计算群集可用,则模型可以扩展到大规模(数百万到数十亿)数据

ControlNet 的原理?
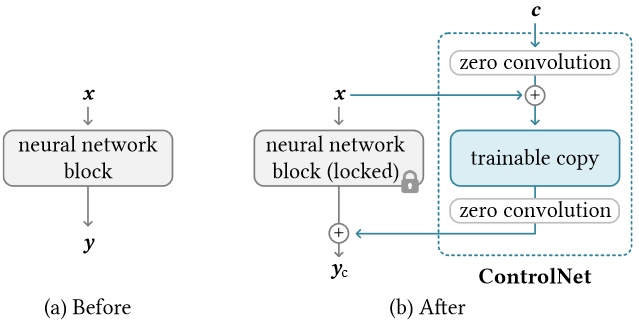
- 1)ControlNet 模块:下图左边是任意神经网络,右边是通过 ControlNet 使用条件控制任意神经网络,ControlNet 输入是条件 c,控制 y 的生成,其中使用了
zero convolution的概念,该卷积在初始时设置权重和偏置为 0,即不影响左边网络,后续学习时变为非 0 卷积![]()
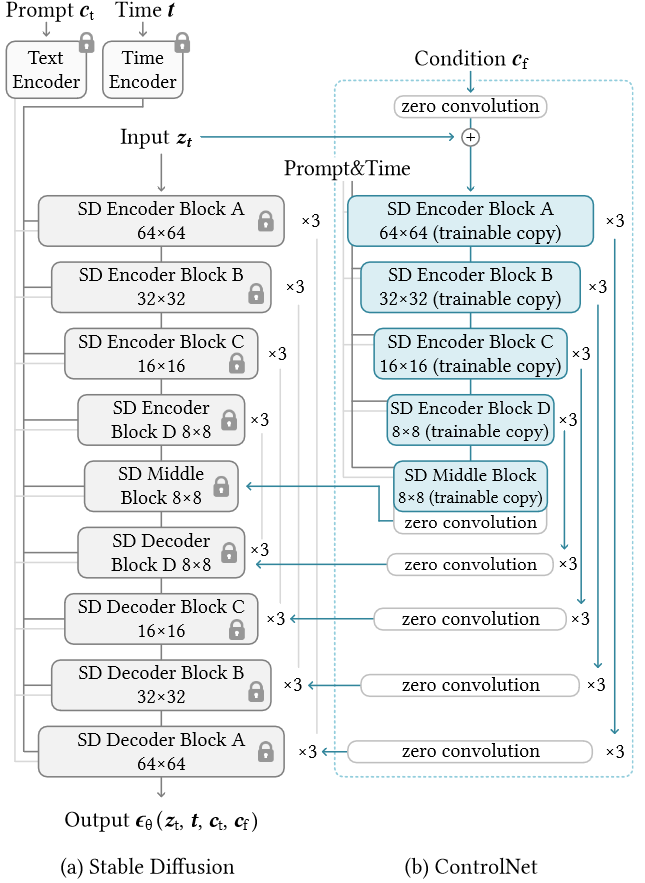
- 2)ControlNet 应用到 SD:下图是控制 SD 模型的 ControlNet,可见 ControlNet 其实是 SD 网络的拷贝,然后在各模块内添加零卷积,由此,整个网络权重分为 “锁定副本” 和 “可训练副本”。制作此类副本而不是直接训练原始权重的动机是避免在数据集较小时过拟合,并保持从数十亿张图像中学习的大模型的落地应用质量,由于原始权重是锁定的,不需要在原始编码器上进行梯度计算来进行训练。这可以加快训练速度并节省 GPU 内存,因为可以避免原始模型上一半的梯度计算。用 ControlNet 训练稳定的扩散模型只需要在每次训练迭代中增加约 23% 的 GPU 内存和 34% 的时间
![]()
ControlNet 的零卷积(zero convolution)?
- 一种称为 “零卷积” 的独特卷积层连接,即 1 × 1 个卷积层,权重和偏差都用零初始化。在第一个训练步骤中,神经网络块的可训练副本和锁定副本的所有输入和输出都一致,就好像 ControlNet 不存在一样
- 在训练之初新加的 UNet encoder 不会影响到原始 Stable Diffusion 的生成,而随着训练,zero convolution 会逐渐被赋予权重,对冻结的 Stable Diffusion 的控制力逐渐加强
ControlNet 的训练?
![]()
- 由 ControlNet 模块可知,模型需要 3 个输入,所以需要收集大量的 "图像 - 文本描述 - 条件"3 元组数据,其中条件可以是边缘图、分割图、关键点
- 类似 DDPM 的训练过程,给定潜在空间特征 ,文本 prompts ,经过 t 次加躁后变为 ,其估计噪声的函数为:,在使用 ControlNet 后,在给定附加条件 的条件下,其噪声估计过程变为:
- 在训练过程中,随机使用空字符串替换 50% 的文本提示,可以增加 ControlNet 网络的训练权重
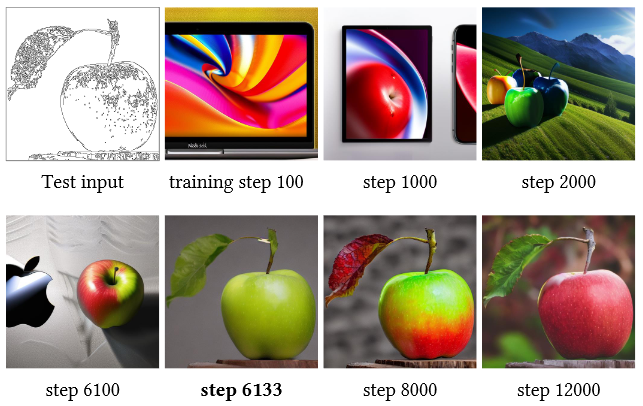
- 如上图所示,在训练过程中,ControlNet 不是逐渐向 "包含条件信息" 的图片变化,而是在某个步骤突然变化的
ControlNet 的推理?
- Classifier-free guidance resolution weighting:原始的 CFG 技术是无条件预测和条件预测的线性组合,下图 b、c 分布是不使用 CFG 和使用 CFG 的过程,而 d 是使用不同权重加权不同模块的结果,如对于第 i 个模块,权重 ,其中 ,通过不断降低权重实现更好的分辨率
![]()
- Composing multiple ControlNets:通过使用多个 ControlNet,并将借个组合在一起,可以实现生成图片的多条件控制
![]()


ControlNet 实验不同的模块?
![]()
- 上图是 ControlNet 实验的 3 个 ControlNet 模块,其中 (a) 在复制层前后使用零值初始化的标准卷积,(b) 在复制层前后使用高斯权重初始化的标注卷积层,© 直接使用一个卷积层学习。每一列是使用不同的 prompt 生成的效果
- 从生成的效果分析,c 生成的图片无法生成符合文本的图片,b 生成的图片效果性能下降,只有 a 生成的图片符合条件控制及文本,所以最终 ControlNet 使用模块 a 构建

ControlNet 比较以前的方法?
![]()
- ControlNet 分别在 Seg、sketch、canny 条件控制下比较生成效果,可以发现 ControlNet 更清洗尖锐

ControlNet 的训练数据集规模的影响?
![]()
- 训练的数据越多,最终生成的效果越好

ControlNet 解释内容的能力?
![]()
- 对于输入模棱两可,并且用户在提示中没有提及对象内容,则 ControlNet 结果看起来像模型试图解释输入形状

参考: