EffectiveNMT
在 seq 2 seq 的基础上引入注意力机制
神经机器翻译 (NMT) 的原理?
- 神经机器翻译即在输入源语言句子的条件下预测目标句子,数学化表达如下,其中 s 表示源语言句子, 表示要翻译的第 个词, 表示已经翻译的目标语言的前 个
- 训练的目标:是使得生成目标语言的所有词的概率相加最大化,可以认为是极大似然估计,已知极大似然等于最小化交叉熵损失
什么是 EffectiveNMT?
![]()
- 在 Seq2Seq 的基础上引入注意力机制,使得 Seq 2 Seq 具备长程注意力
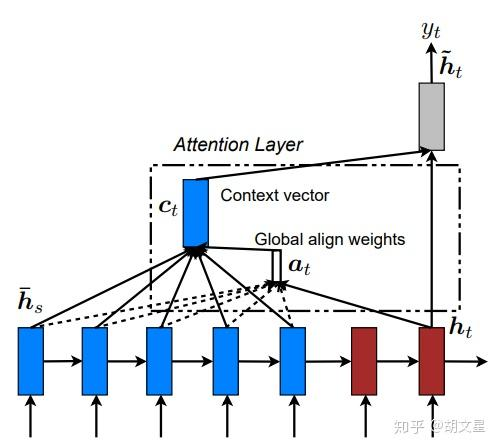
EffectiveNMT 的全局注意力 Luong 模型整体流程?
![]()
- Encoder:用于编码输入数据,即将源语言 [batch_size, sequence_length] 经过查词汇表得到 [batch_size, sequence_length, embedding_size],然后经过 RNN 的学习,得到所有时刻的隐状态 [batch_size, sequence_length, hidden_size]
- Decoder:首先计算当前时刻上下文状态 ,其中 是 encoder 在 i 时刻 encoder 隐状态对 decoder 中 t 时刻隐状态的影响程
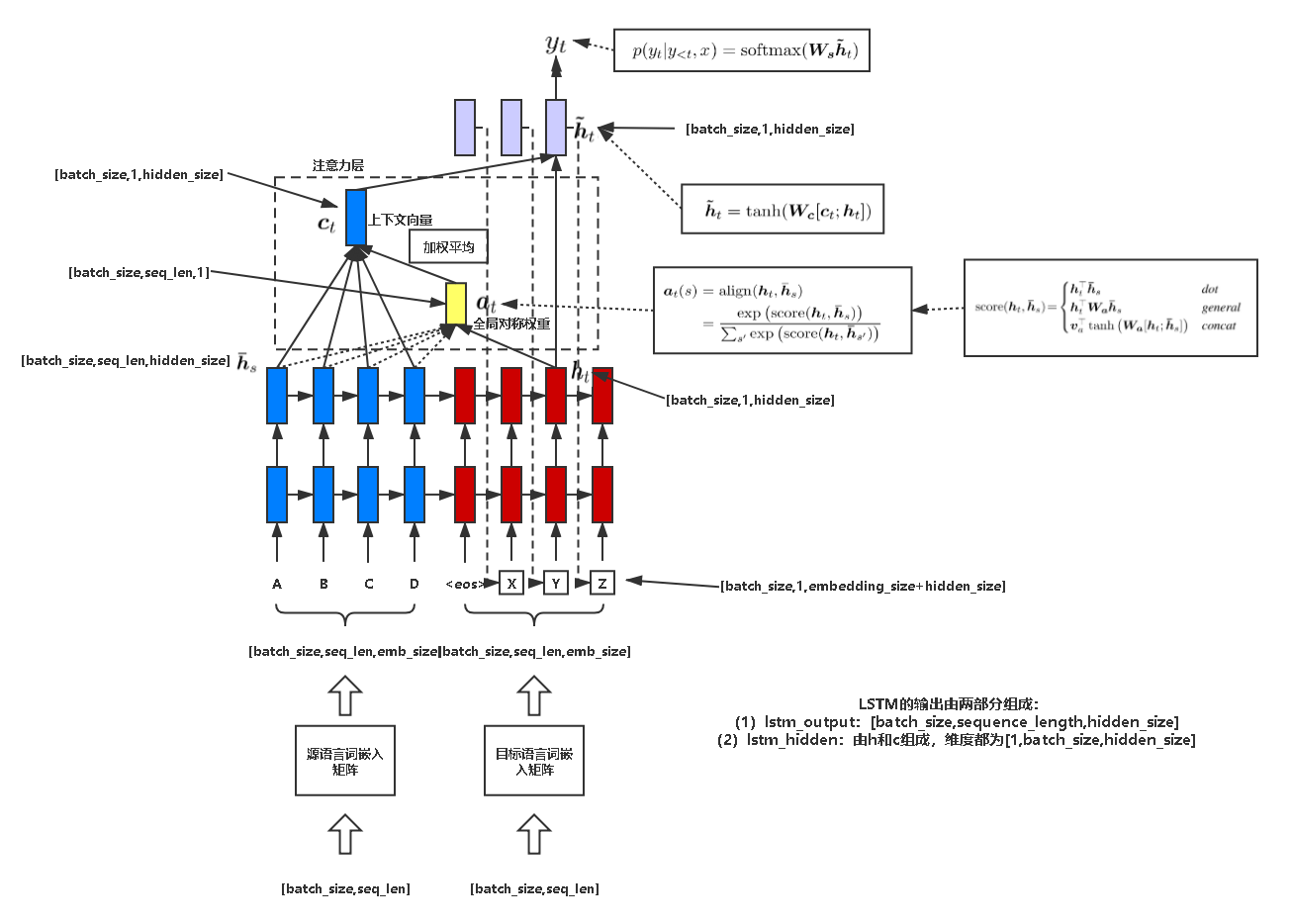
\begin {aligned}&\text {ct}&& =\sum_{i=1}^{T}\alpha_{ti} h_{i} \\&\alpha_{ti}&& =\frac {exp (e_{ti})}{\sum_{k=1}^Texp (e_{tk})} \\&\boldsymbol {s}_{\boldsymbol {t}}&& =tanh (W [s_{t-1},y_{t-1}]) \\&e_{ti}&& =s_{t}^{\top} W_{a} h_{i} \end {aligned}$$,然后利用生成的 $c_t$ 重新计算当前时刻的隐状态 $\overline s_t$,并预测输 $$\begin {array}{l}\tilde {s}_t=tanh (W_c [s_t,{\color {red}{c_t}}])\\o_t=softmax (V\tilde {s}_t)\end {array}
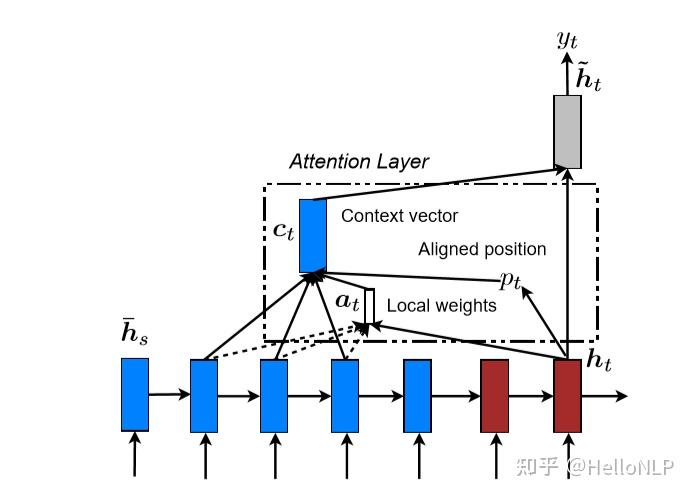
EffectiveNMT 的局部注意力 Luong 模型整体流程?
![]()
- Global attention 的缺点在于,它必须关注每个目标词在输入源的所有词,这很昂贵,并且可能使翻译更长的序列(例如段落或文档)不切实际。为了解决这一缺陷,我们提出了一种局部注意机制,该机制选择只关注每个目标词的源位置的一小部分
- 模型首先在时间 为每个目标单词生成一个对齐的位置 。然后,上下文向量 会由窗口 内的一组源隐藏状态的加权平均值得出;D 是根据经验选择的。与全局注意力方法不同,现在的局部对齐向量 是固定维度的
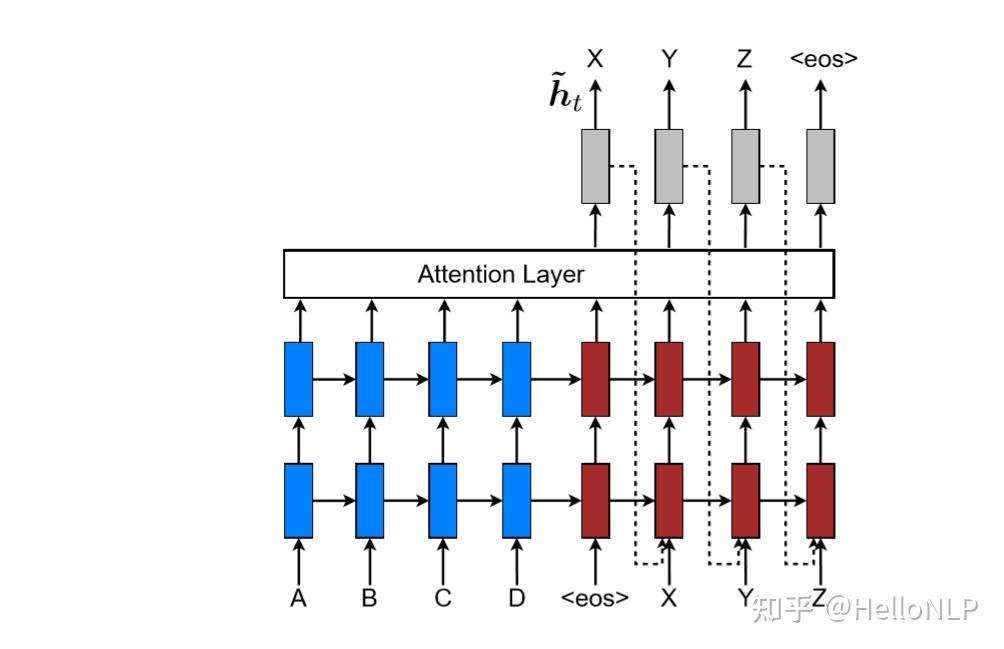
EffectiveNMT 的 Input-feeding approach?
![]()
- 在我们提出的全局和局部方法中,注意力决定是独立做出的。而在标准 MT 中,通常在翻译过程中会有一定的范围集,来跟踪已翻译的词。同样,在关注的 NMT 中,应该结合过去的对齐信息共同做出对齐决策。为了解决这个问题,我们提出了一种输入馈送的方法
- 其中注意向量 在下一个时刻与输入连接在一起,如上图所示。具有这种连接的效果是双重的:希望模型可以意识到之前的对齐选择,并且创建了一个非常深的网络,横跨了水平和垂直方向
Encoder 输入和 Decoder 输入对齐方式分析?
![]()
- 在求取源端和目标单词之间的对齐程度 时,假设源端输入是 ,目标端输入是 ,则 N 个源输入和 M 个目标输入的关系可以使用以下 3 种方式求取,论文最终选择第三
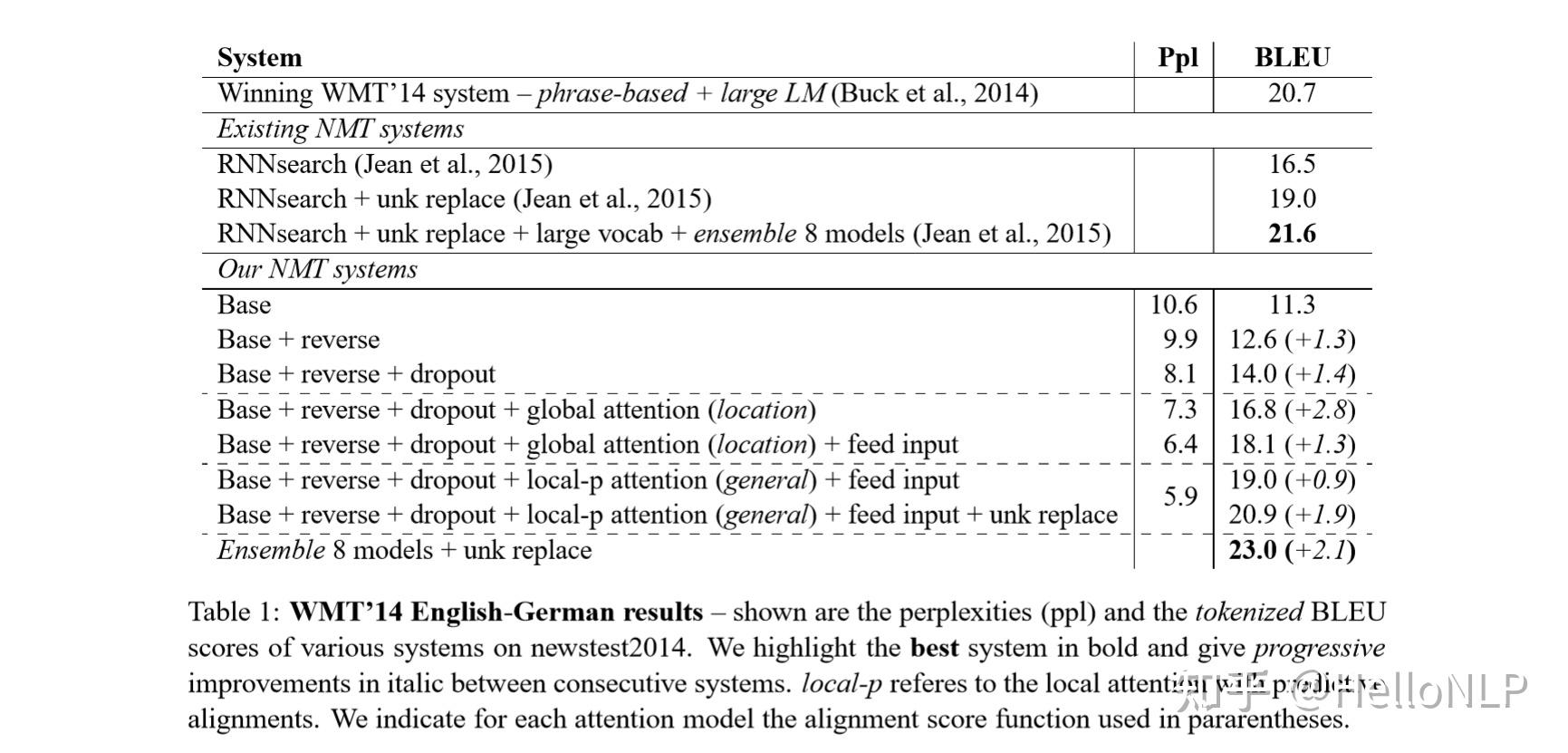
- Luong Attention 的效果 在 global attention 的情况下好于 Bahdanau Attention。在使用 local attention 之后,Luong Attention 的优势更加明显,大幅领先 Bahdanau Attention
Bahdanau and Luong attention 的区别?
- context 的计算方式不同:解码器在第 t 步,Bahdanau 注意力机制使用 decoder 第 t-1 步的隐状态 与 encoder 的各位置的输出 加权得到 ,而 Luong 注意力机制使用 decoder 当前时刻的隐状态 与 encoder 的每一个隐状态 encoder 的各位置的输出 加权得到
- decoder 的输入输出不同:解码器在第 t 步,Bahdanau 注意力机制将前一时刻隐状态 与 拼接作为 decoder 输入,经 RNN 运算得到 ,并直接输出 ;Luong 注意力机制将当前时刻隐状态 与 拼接,并通过全连接网络输出 ,Luong 注意力机制只处理最顶层
参考: