ConvS2S
seq 2 seq 由于使用 rnn,不能并行计算,本文通过 CNN 替代 RNN 学习序列数据,使得模型可以并行学习
什么是 ConvS2S ?
![]()
- 典型 Seq2Seq 是使用 RNN 实现的,虽然其可以较好编码序列信息,但是不可以并行计算,因为后一时刻的输出依赖于前一时刻的隐状态,并且 RNN 的学习的依赖都是短程依赖。FaceBook 设想使用 CNN 替换 RNN 学习序列信息,因为 CNN 可以并行计算,并且可以通过叠加多层 CNN,实现远距离依赖
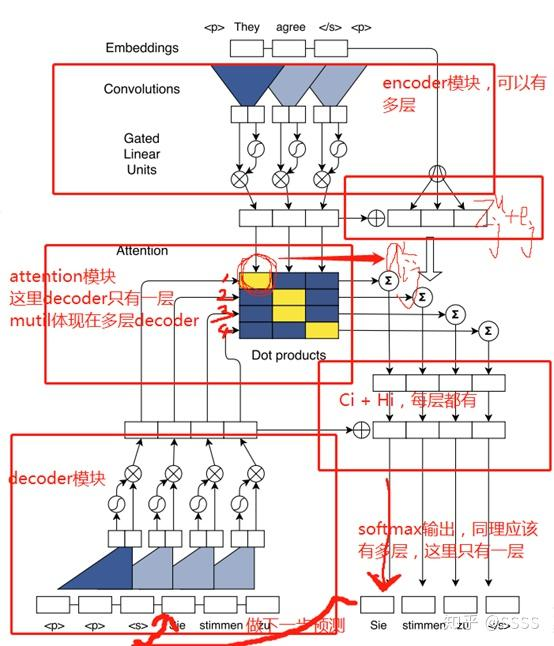
ConvS2S 的网络结构?
![]()
- Encoder:编码器使用 1D 卷积 + GLM 模块提取源序列的特性
- Decoder:解码器使用 1 D 卷积 + GLM 模块提取目标序列的特性
- Attention:通过 dot 乘得到源序列和目标序列的注意力矩阵 ,然后使用注意力矩阵加权源序列,得到 Decoder 的所有时刻的隐状态,并使用该隐状态解析输出
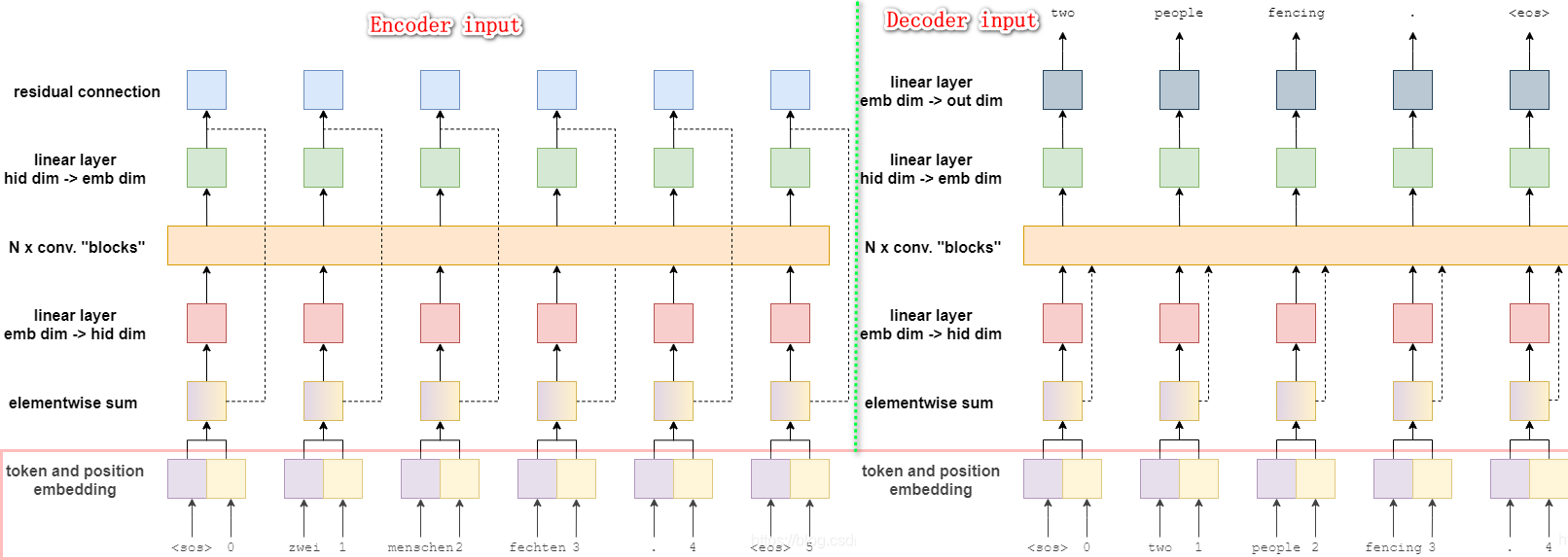
ConvS2S 的 Position Embeddings?
![]()
- 在原始序列输入到编码器前或者目标序列输入解码器前,需要给序列的特征表示加上位置感知能,因为同一个词放在不同位置,其含义不同
- 假设词向量是 ,位置向量是 ,则输入向量是 ,其中位置向量是在训练过程中学到
ConvS2S 的 Convolutional Block Structure?
![]()
- 是一系列的 1D 卷积 + GLM + 残差连接 过程,卷积时,目标序列前面添加 K-1 个 padding,这是为了每次卷积只能看到自己以前的序列,这类似 transformer 的 mask attenstion
- GLM 是非线性映射层,采用的是门控结构 gated linear units (GLU)。GLU 不仅有效地降低了梯度弥散,而且还保留了非线性的能力
- 残差连接把输入与输出相加,输入到下一层网络中
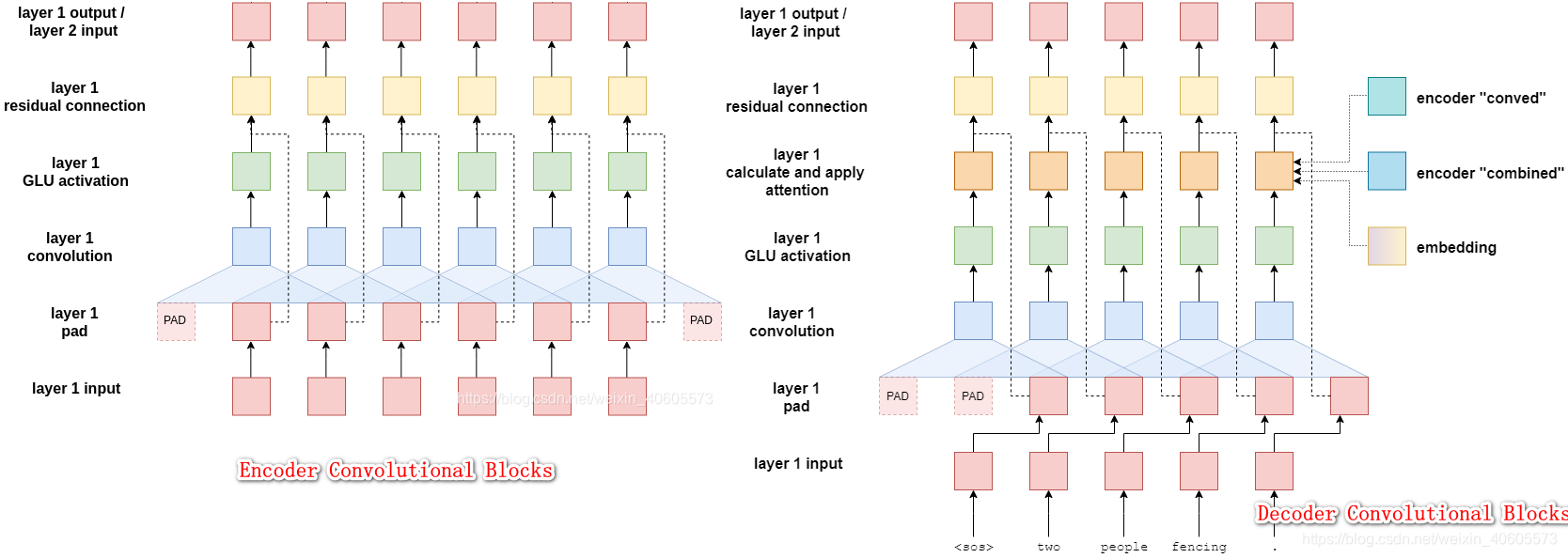
ConvS 2 S 的 Multi-step Attention?
![]()
- 原理与传统的 attention 相似,attention 权重由 decoder 的当前输出 和 encoder 的所有输出共同决定,利用该权重对 encoder 的输出进行加权,得到了表示输入句子信息的向量 , 和 相加组成新的 ,这里的 是权重信息,用了向量点积的方式再进行 softmax 操作, 是残差连接后的输出
- 在每一个卷积层都会进行 attention 的操作,得到的结果输入到下一层卷积层,这就是多跳注意机制 multi-hop attention。这样做的好处是使得模型在得到下一个注意时,能够考虑到之前的已经注意过的

参考: