CoordConv:An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
考虑到传统卷积的平移不变性,对于一些位置敏感的任务是有害的,于是提出基于在卷积前增加座标信息作为输入
什么是 CoordConv ?
![]()
- 考虑到传统卷积的平移不变性,对于一些位置敏感的任务是有害的,于是提出基于在卷积前增加座标信息作为输入

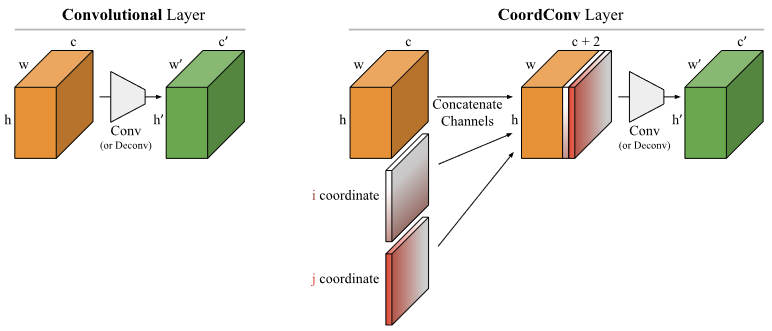
CoordConv 的网络结构?
![]()
- 与传统卷积相比,CoordConv 就是在输入的 feature map 后面增加了两个通道,一个表示 x 坐标,一个表示 y 坐标,后面就是与正常卷积过程一样了
- 传统卷积具备三个特性:参数少、计算高效、平移不变性。而 CoordConv 则仅继承了其前两个特性,但运行网络自己根据学习情况去保持或丢弃平移不变性。看似这会损害模型的归纳能力,但其实拿出一部分网络容限能力去建模非平移不变性,实际上会提升模型的泛化能力
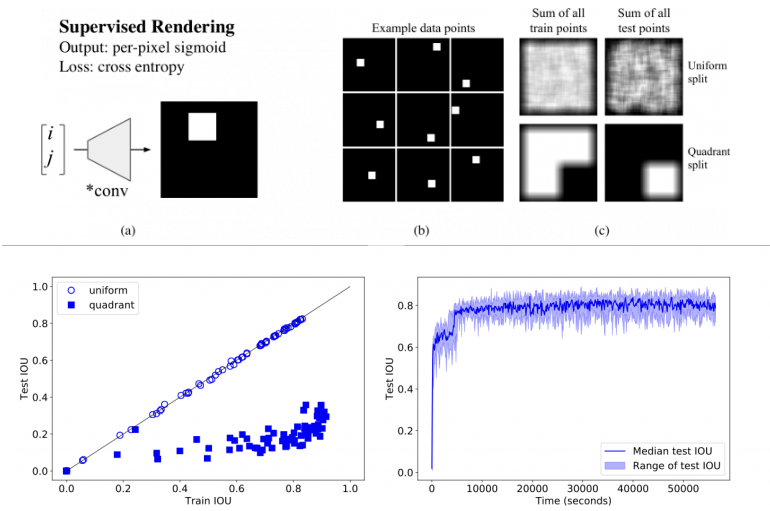
CNN 很难做到监督式渲染?
![]()
- 任务:假设我们向一个网络中输入 (i, j) 坐标,要求它输出一个 64×64 的图像,并在坐标处画一个正方形 (a)
- 创建数据集:在 64×64 的画布上随机放置了一些 9×9 的方块 (b)。将数据集中方块所有可能的位置列出后,总共有 3136 个样本。为了评估模型生成的表现,我们将样本分为两组训练 / 测试数据集:一组是将数据集中 80% 坐标用于训练,20% 用于测试。另一组中将画布从中分为四个象限,坐标位于前三个象限的用于训练,第四象限的坐标用于测试 ©
- 效果:CNN 表现得极差。即使有 1M 的参数、训练了 90 分钟,模型在第一个数据集上也没达到 0.83 的 IOU 分数,在第二个数据集上设置都没超过 0.36
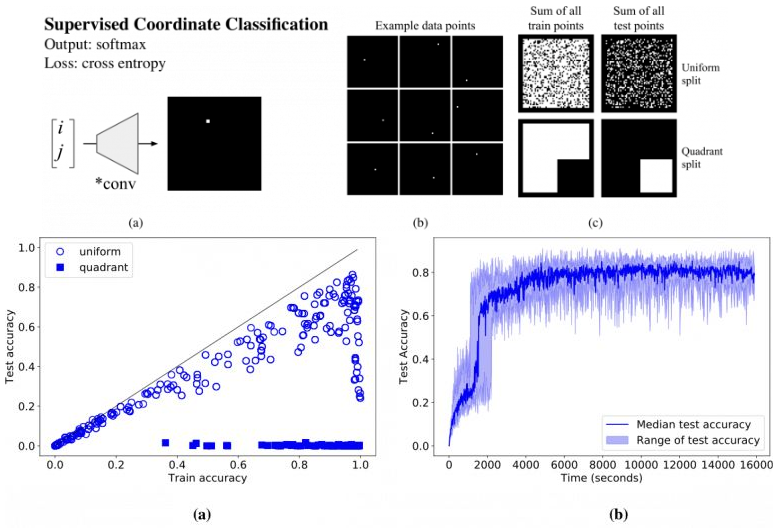
监督式座标分类对 CNN 很难的?
![]()
- 任务:假设我们向一个网络中输入 (i, j) 坐标,要求它输出一个 64×64 的图像,并在该坐标处绘制 (a)
- 创建数据集:在 64×64 的画布上随机放置了一些 1×1 的方块 (b)。将数据集中方块所有可能的位置列出后,总共有 3136 个样本。为了评估模型生成的表现,我们将样本分为两组训练 / 测试数据集:一组是将数据集中 80% 坐标用于训练,20% 用于测试。另一组中将画布从中分为四个象限,坐标位于前三个象限的用于训练,第四象限的坐标用于测试 ©
- 效果:有些网络能记住训练集,但没有一个的测试准确率超过 86%,并且训练时间都超过了一小时
监督式座标回归对 CNN 很难?
![]()
- 为什么网络很难定位一个像素呢?是因为从小空间到大空间的转换很困难吗?如果朝一个方向会不会容易点呢?如果我们训练卷积网络将图像信息转换成标量坐标,是否与普通图像分类更相似呢?
- 结果模型在这种监督式回归的任务上同样表现得不好。在图 10 中,左边图中的点表示正确的像素坐标,中间图中的点表示模型的预测。模型在测试集上表现得不好,并且在训练集上也差强人意

CoordConv 与卷积的区别?
![]()
- CoordConv 无论是在分类任务、还是回归任务,都比普通卷积效果更好,说明对于位置敏感的任务使用 CoordConv 效果更好
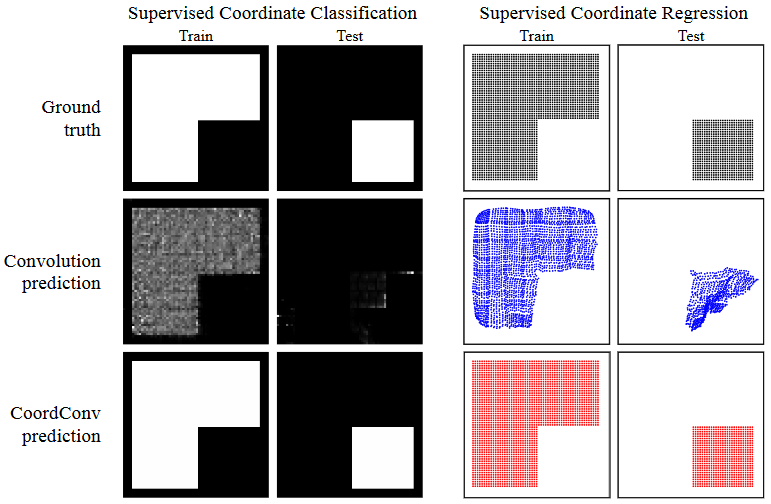
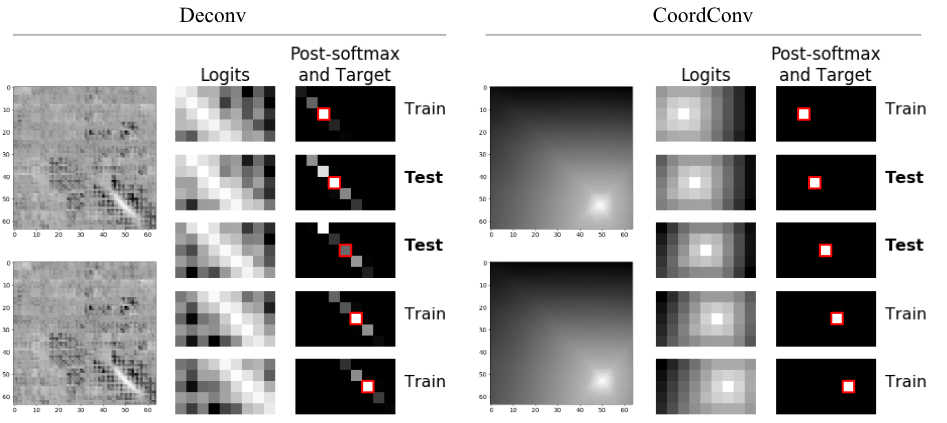
CoordConv 与反卷积的区别?
![]()
- 使用 CoordConv 之后,网络输出概率无论是使用 sigmoid 还是 softmax,都能准确预测出其位置,但是反卷积的测试集上没有表现出该能力
参考: