ConvNeXt:A ConvNet for the 2020s
针对目前火热的 transformer,ConvNeXt 认为不是卷积固有的劣势导致的 CNN 性能比 transformer 差,而是 CNN 的设计不充分导致的
什么是 ConvNeXt ?
![]()
- 针对目前火热的 transformer,ConvNeXt 认为不是卷积固有的劣势导致的 CNN 性能比 transformer 差,而是 CNN 的设计不充分导致的
- ConvNeXt 基于 ResNet50,并根据过去十年中的新最佳实践和发现对其进行迭代改进,使得 CNN 的性能超过 transformer
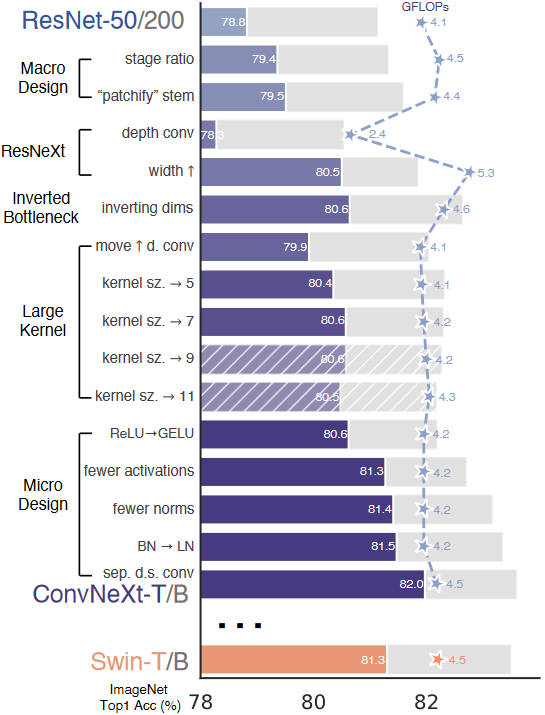
ConvNeXt 优化 “宏观设计”?
![]()
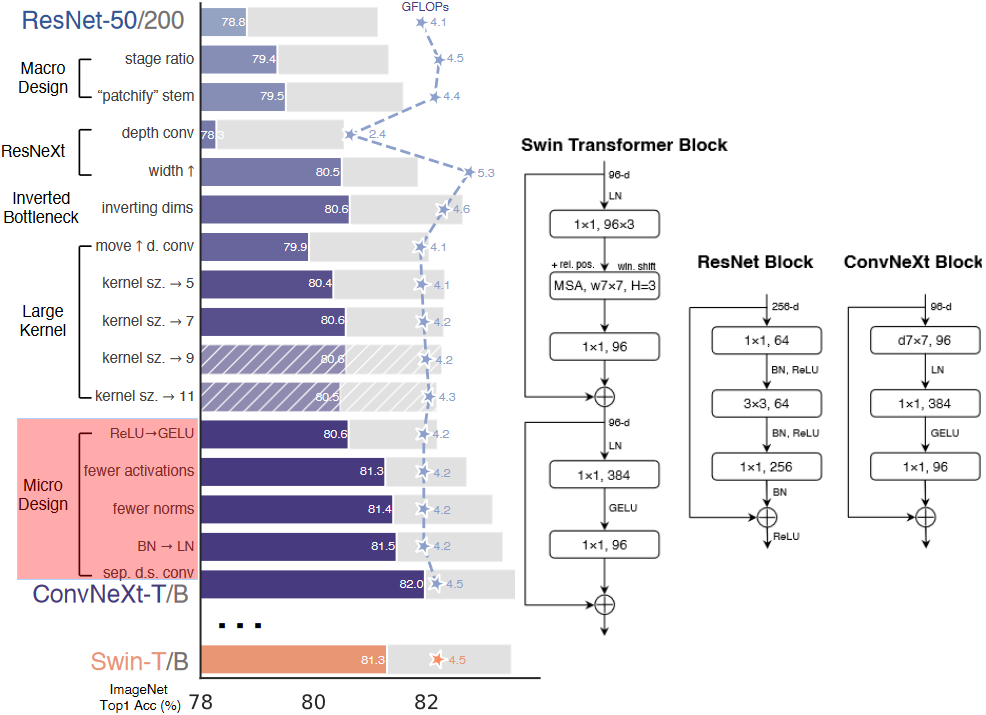
- stage ratio:众所周知 resnet50 有 4 个由若干个 block 堆叠出的 stage,每个 stage 的 block 数量不太相同,作者将堆叠次数按照 Swin-T (1,1,3,1) 来设计,ResNet 50 由 (3,4,6,3) 调整为 (3,3,9,3)
- patchify stem:将 stem 更改为 Patchify,即 ResNet50 开头的 7 x 7 卷积(stride=4)、3 x 3 最大池化(stride=4)->4 x 4(stride=4)
- stage ratio 相当于加深原始 resnet50,带来效果最明显
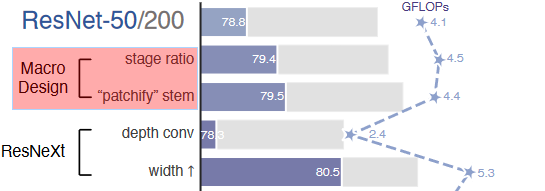
ConvNeXt 优化 “参考 ResNetXt”?
![]()
- ResNetXt 对 BottleNeck 中的 3x3 卷积层采用分组卷积来减少 FLOPS。 在 ConvNext 中使用 depth-wise convolution
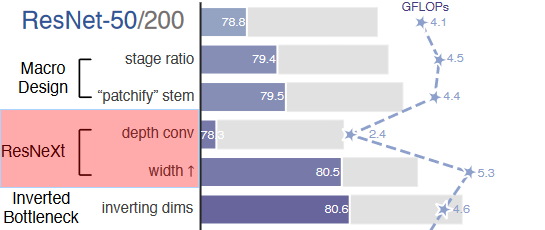
ConvNeXt 优化 “参考倒残差 Inverted Bottleneck”?
![]()
- resnet 里 block 的设计是先 1x1 卷积降维,之后再用 1x1 卷积升维,形成一个瓶颈层。而 Transformer 块的一个重要设计是,它会产生一个反向瓶颈 (b),ConvNeXt 将 b 的 3 x 3 提前,
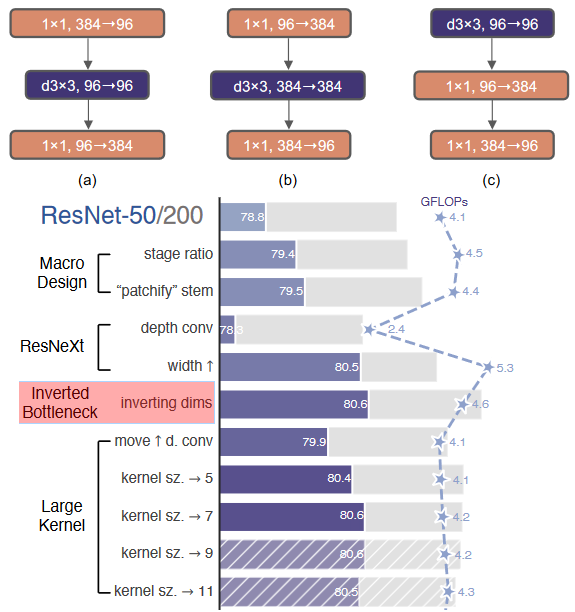
ConvNeXt 优化 “使用大卷积核”?
![]()
- 参考 Swin-T 中使用了 7x7 的窗口,ConvNeXt 将 Inverted Bottleneck 的 3 x 3 卷积替换成 7 x 7,为了降低计算量把 dw conv 放到了 Inverted Bottleneck 的开头,最终结果相近
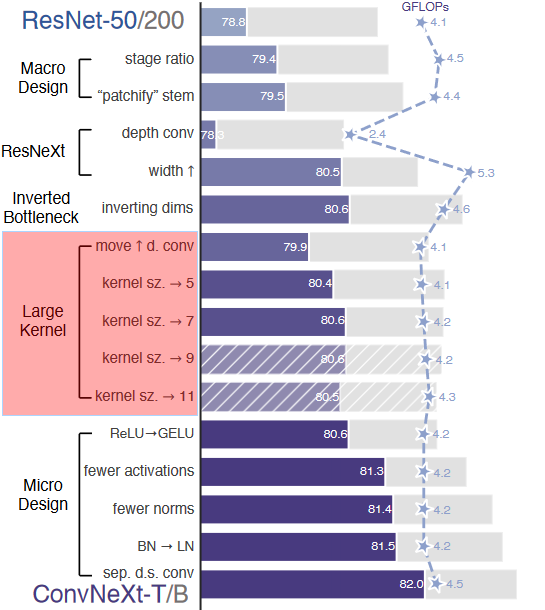
ConvNeXt 优化 “微观设计”?
![]()
- ReLU->GELU:GELU 可以被认为是 ReLU 的一个更平滑的变体,最近的 transformer 中被使用,ConvNet 使用后性能保持不变
- 更少激活函数:Transformer 和 ResNet 块之间的一个小区别是 Transformer 的激活功能较少,根据这一思路消除将 ResNet Block 的 3 个 RELU 激活改为 1 个 GELU 激活
- 更少 BN 层:Transformer 块通常也有较少的规范化层。在这里,我们移除了两个 BatchNorm 层,在 conv 1×1 层之前只留下一个 BN 层
- BN->LN:BatchNorm 是 ConvNets 中的一个重要组成部分,因为它提高了收敛性,减少了过度拟合,在原始 ResNet 中直接用 LN 代替 BN 将导致次优性能。在对网络架构和训练技术进行修改后,在这里重新使用 LN 代替 BN,性能稍好一些
- 分离下采样层:在 ResNet 中,下采样是通过 stride=2 conv 完成的。 Transformers(以及其他卷积网络)也有一个单独的下采样模块。 作者删除了 stride=2 并在三个 conv 之前添加了一个下采样块,为了保持训练期间的稳定性在,在下采样操作之前需要进行归一化
参考: