ConvNeXt V2:Co-designing and Scaling ConvNets with Masked Autoencoders
ConvNeXtv2 借鉴掩码自编码器(MAE),在 ConvNeXt 的基础上引入全卷积掩码自编码器 (FCMAE),但是发现 MLP 层存在潜在的特征崩溃问题,为了解决这个问题,该研究提出添加一个全局响应归一化层(Global Response Normalization layer,GRN)来增强通道间的特征竞争
什么是 ConvNeXtv2 ?
![]()
- ConvNeXtv2 借鉴掩码自编码器(MAE),在 ConvNeXt 的基础上引入全卷积掩码自编码器 (FCMAE),但是发现 MLP 层存在潜在的特征崩溃问题,为了解决这个问题,该研究提出添加一个全局响应归一化层(Global Response Normalization layer,GRN)来增强通道间的特征竞争
- ConvNeXtv2 表明监督学习中重复使用监督学习中的固定架构设计可能不是最佳方法,可以使用部分自监督 + 监督
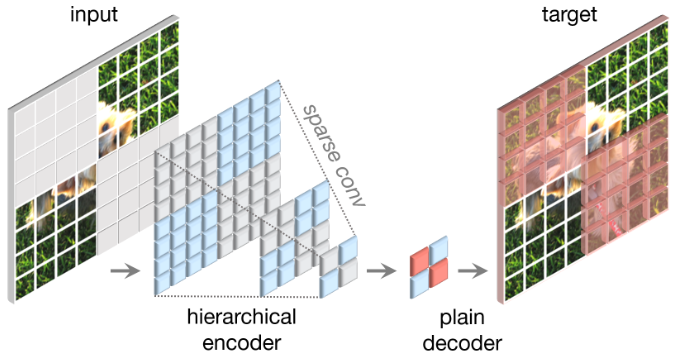
ConvNeXtv2 的全卷积掩码自编码器 (FCMAE)?
![]()
- 参考 MAE 的原理,将 encoder 和 decoder 的 vit 部分换成卷积,然后使用稀疏卷积替换 mask token。即原始的输入信号被随机 mask,输入 Encoder,希望 Encoder + Decoder 的输出预测 mask 掉的部分
- Encoder:使用 ConvNeXt,在预训练期间,将卷积替换为稀疏卷积,这使得模型只能在可见数据点上操作;在微调阶段,稀疏卷积层可以转换回标准卷积,而不需要额外的处理
- Decoder:使用 1 个 ConvNeXt Block,总体上形成了非对称的 Encoder-Decoder 体系结构,因为 Encoder 更重,且具有分层架构
ConvNeXtv2 的自监督性能?
![]()
- 将 FCMAE 与监督学习进行比较。有监督训练 100 Epochs 精度是 82.7%,有监督训练 300 Epochs 精度是 83.8%,FCMAE 进行 800 和 100 个 Epoch 的预训练和微调结果是 83.7%。说明 FCMAE 预训练提供了比随机基线更好的初始化 (82.7→83.7)

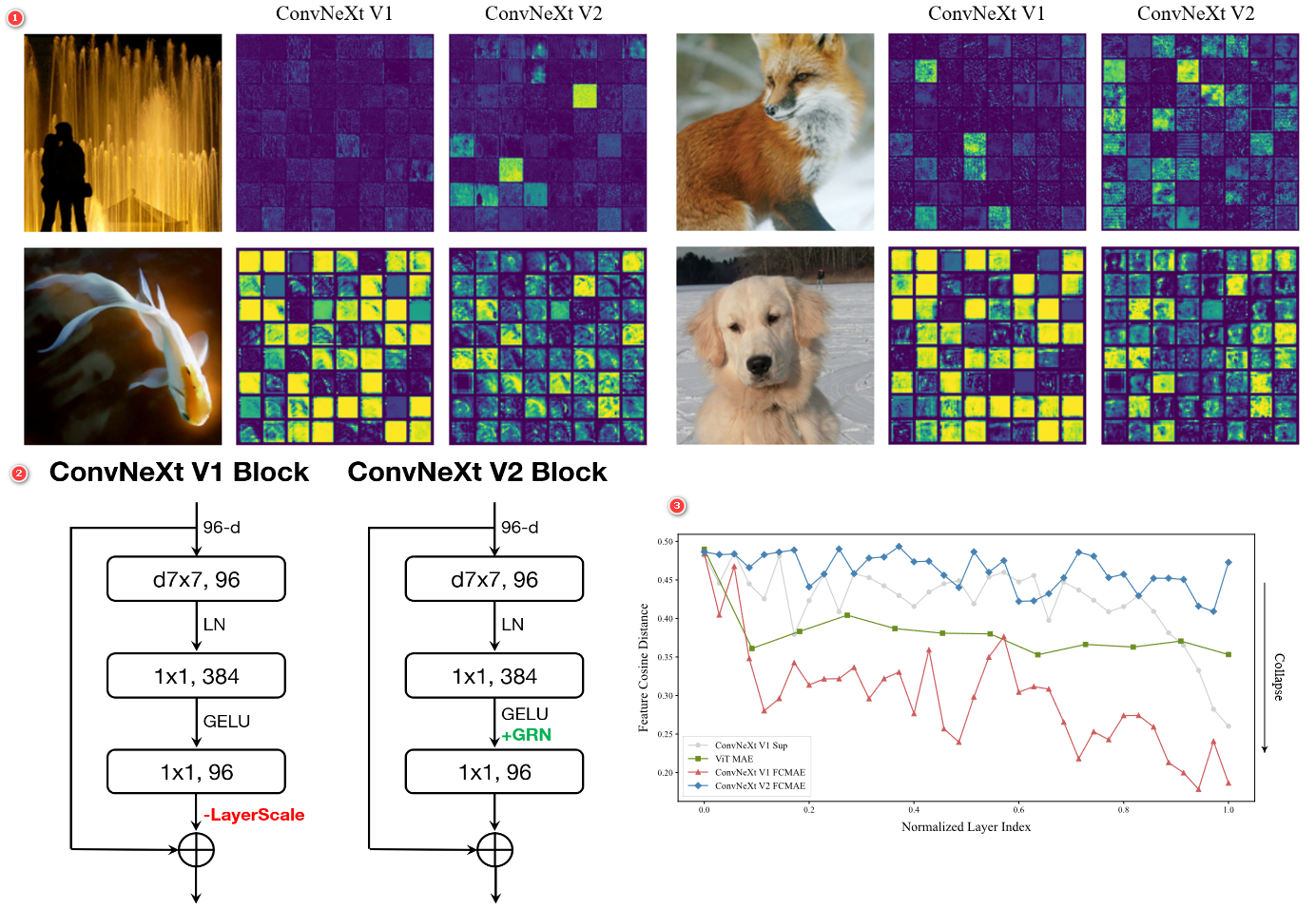
ConvNeXtv2 的全局响应标准化 (Global Response Normalization, GRN)?
![]()
- GRN 通过求实例在每个通道的权重,增强通道间的特征竞争,避免出现特征崩溃。图 1 是 ConvNeXtv2 应用 GRN 后,可以看出每个通道都有响应,不像 ConvNeXtv1 某些通道已经不响应
- 根据实验发现,当应用 GRN 时,LayerScale 不是必要的并且可以被删除,如图 2 所示
- 图 3 是不同层的规范化层的特征余弦距离,余弦距离越大,特征越保持,可以看出 ConvNeXtv 2 的特征一直在保持,更 Vit MAE 类似
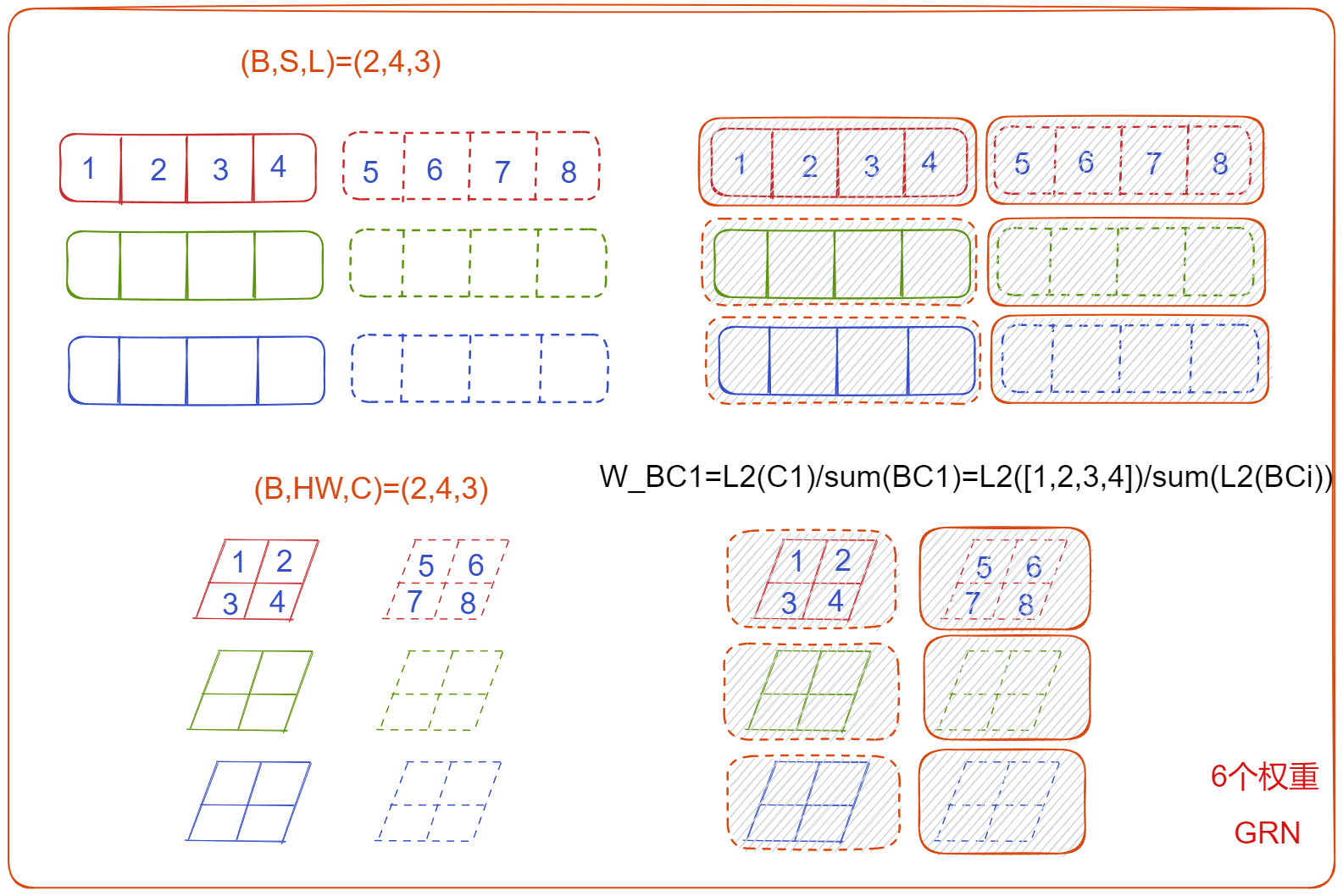
全局响应标准化(GRN)的计算过程?
![Drawing 2023-05-05 16.29.31.excalidraw]()
- 规范化:传统的规范化层是求出均值 与方差 ,然后使用 进行规范化,而 GRN 只需要求出权重 ,然后使用 规范化
- 规范化值:这里的 w 是实例在所有实例上的权重,如图对于 (B, HW, C) 输入的特征,先求 (B1, C1) 实例上的 L2 范数,该实例的 L2 范数在所有实例 L2 范数的比例即等于 w
- 校准数据:不同于 BN 使用公式 校准数据,GRN 使用 校准数据,相当于引入一个残差连接
ConvNeXtv2 的损失函数?
- 遵循 MAE 的做法,使用重建目标和真值之间的 Mean Squared Error, MSE Loss,作为 Reconstruction target。损失函数仅应用于 masked patches