SPPNet:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPPNet 的目标检测思想和 RCNN 一致,都是提取候选区域的一维特征进行获选区域分类及位置回归,通过引入空间金字塔池化 (SpatialPyramidPooling, SPP) 实现任意大小图片输入得到得到固定长度输出,避免 R-CNN 重复卷积的过程,提高了运行速度
什么是 SPPNet?
![SPPNet-20230408141616]()
- SPPNet 的目标检测思想和 RCNN 一致,都是提取候选区域的一维特征进行获选区域分类及位置回归,通过引入空间金字塔池化 (SpatialPyramidPooling, SPP) 实现任意大小图片输入得到得到固定长度输出,避免 R-CNN 重复卷积的过程,提高了运行速度
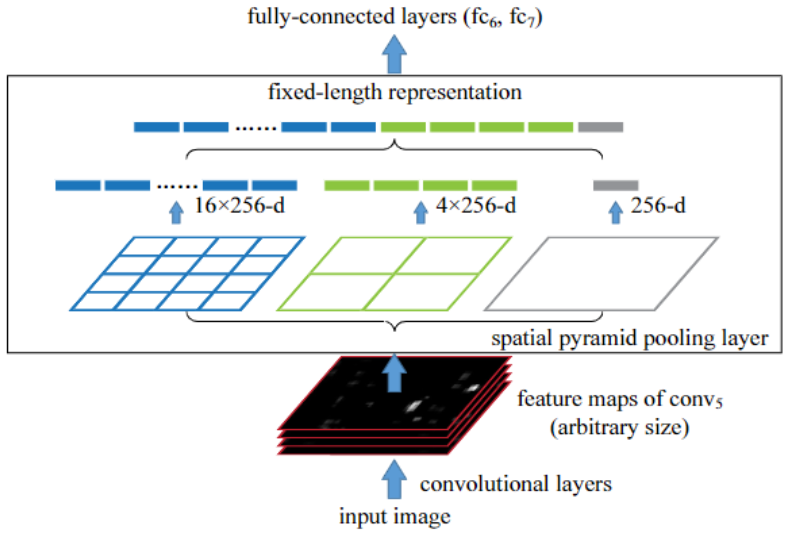
SPPNet 进行目标检测的步骤?
- 1)获得候选框:使用选择性搜索 (SelectiveSearch,SS) 生成候选区域
- 2)获得获选框固定长度特征:预训练分类网络后,全图输入 CNN,拿到 conv5 的 featrue map,然后利用金字塔池化拿到不同目标的 “固定长度特征”,然后接 fc5->fc6->fc8,为了微调 fc 层,进行 N+1 分类监督学习,其中输入是这张图片所有目标 “固定长度特征”->fc5->fc6->fc8(N+1 分类)
- 3)获选框分类:将候选区域特征输入到 支持向量机 (SVM) 分类器,判别输入类别
- 4)获选框位置回归:以回归的方式精修候选框位置
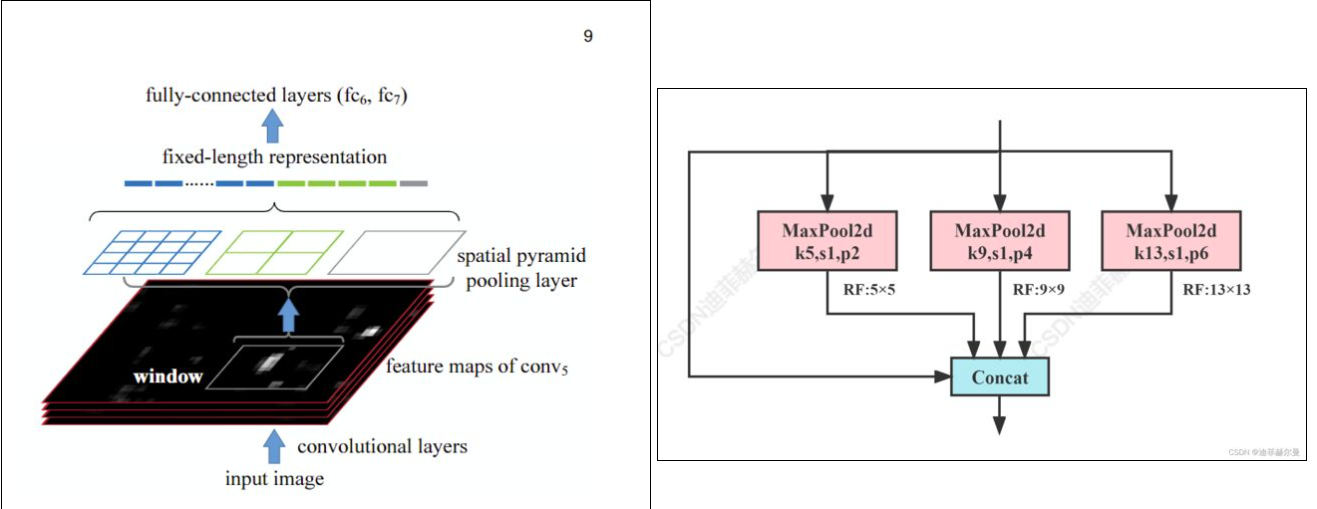
什么是空间金字塔池化 (Spatial Pyramid Pooling, SPP)?
![]()
- 典型的卷积神经网络基础结构: 卷积层 -> 池化层 -> 全连接层,由于全连接层的输入维数必须提前固定,因此第一层卷积的输入尺寸是固定的,一般通过裁剪、warp 拉伸等操作把图片变换成固定尺寸,再输入网络,但是些操作在一定程度上会导致图片信息的丢失或者变形
- 空间金字塔池化: 把卷积操作之后的特征图,以不同大小的块(池化框)来提取特征,分别是 4 x 4,2 x 2,1 x 1,将这三张网格放到下面这张特征图上,就可以得到 16+4+1=21 种不同的块,从这 21 个块中,每个块提取出一个特征(提取方式有平均池化、最大池化等),这样就得到了固定的 21 维特征向量
1
2
3
4
5
6
7
8
9
10
11
12
13
14class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
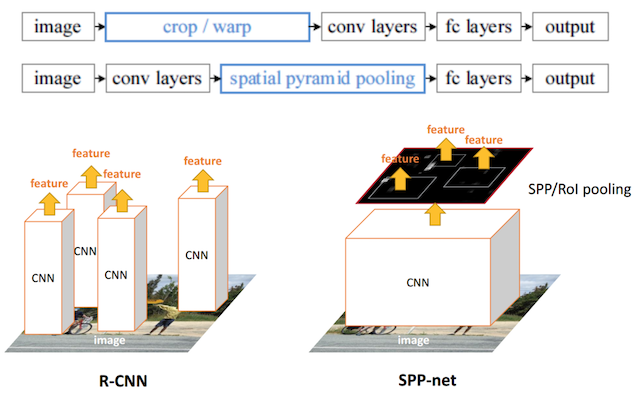
SPPNet 比较 RCNN 的改进 ?
![SPPNet-20230408141617-1]()
- RCNN 需要对候选区域做多次的特征提取,列如:上图一张图 4 个目标需要跑 4 次网络提取特征,而 SPPNet 只跑一次,然后通过映射关系直接提取 4 个目标位置的特征
- 1)生成候选窗口: SPPnet 和 RCNN 都是首先通过选择性搜索 (SelectiveSearch,SS) 生成待检测的 2000 个候选窗口
- 2)提取候选框的固定长度特征: SPPNet 提出了一种从候选区域到全图的特征映射 (feature map) 之间的对应关系,通过此种映射关系可以直接获取到候选区域的特征向量,不需要重复使用 CNN 提取特征,从而大幅度缩短训练时间
SPPNet 如何在最后一层的 feature maps 中找到对应候选区域的特征?
![SPPNet-20230408141618]()
- 假设 (x’, y’) 表示特征图上的坐标点,坐标点 (x, y) 表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关: (x, y)=(Sx’, Sy’) ,反过来求候选框在特征图的位置
- S 就是 CNN 中所有的 strides 的乘积,包含了池化、卷积的 stride
SPPNet 微调时,输入、输出是什么?损失如何计算?
![SPPNet-20230408141618-1]()
- 首先,在 ImageNet 上先进行预训练,计算所有 SS 区域的 SPP 特征,将 SPP 的特征对应区域按 IOU0.5 划分正负样本,然后按 1:3 的比例微调空间金字塔池化(Spatial Pyramid Pooling,SPP) 后的全连接层
- 输入:SS 区域的 SPP 特征
- 输出:N+1 分类结果
- 损失:交叉熵损失 (CrossEntropyLoss)
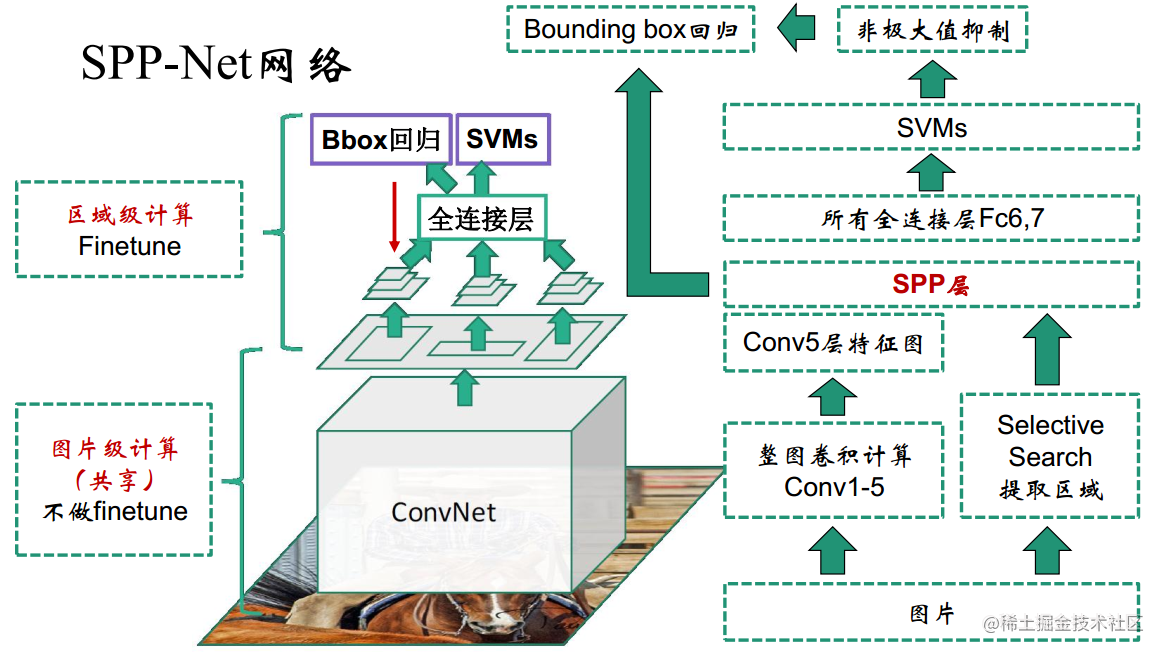
SPPNet 网络微调为什么无法更新卷积层?
- 用类别样本继续训练,目的是使 SPP-Layer 后边的 FC 层输出的特征更准确。但是无法使用反向传播微调 SPP-Layer 前面的卷积层,无法更新前面的权重
- SPPNet 中 fine-tuning 的样本是来自 batch 的 128 张图像的所有 RoI 打散后均匀采样的,这就导致 SGD 的每个 batch 的样本来自不同的图像,根据链式求导法则,计算梯度需要 Feature Map,而同时计算和存储这些图像的 Feature Map 变得 expensive
- FastRCNN 采用分层采样思想,先采样出 N 张图像(image-centric sampling),在这 N 张图像中再采样出 R 个 RoI,具体到实际中,N=2, R=128,同一图像的 RoI 共享计算和内存,也就是只用计算和存储 2 张图像,消耗就大大减少了
SPPNet 与 RCNN 的区别?
![SPPNet-20230408141617-1]()
- RCNN 是让每个候选区域经过 crop/wrap 等操作变换成固定大小的图像;固定大小的图像塞给 CNN 传给后面的层做训练回归分类操作
- SPPNet 把全图塞给 CNN 得到全图的 feature map;让 SS 算法得到候选区域与 feature map 直接映射,得到候选区域的映射特征向量 (这是映射来的,不需要过 CNN) ;映射过来的特征向量大小不固定,所以这些特征向量塞给 SPP 层 (空间金字塔变换层),SPP 层接收任何大小的输入,输出固定大小的特征向量,再塞给 FC 层,经过映射 + SPP 转换,简化了计算,速度 / 精确度也上去了
参考资料: