TOOD:Task-aligned One-stage Object Detection
通过设计新的预测头 T-Head 和样本对齐损失 (TAL),实现分类、定位分支的对齐,使得两个分支的最佳锚框更加接近。这样可以减少 “低分类概率 + 准确位置预测”、“高概率预测 + 不太准确预测” 这两种情况目标的漏检
什么是 TOOD ?
![]()
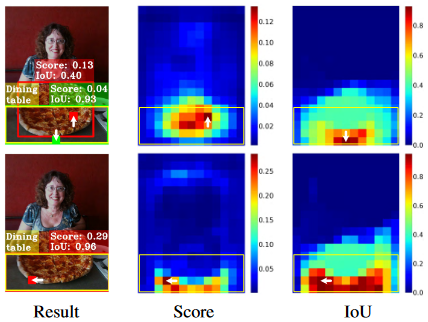
- TSS (Training Sample Selection):由于分类和定位的学习机制不同,两个任务学习到的特征的空间分布可能不同,当使用两个单独的分支进行预测时,会导致一定程度的错位,如图 “result” 栏第一行所示,其中红色、绿色块表示分类、回归的最佳锚点,TSS 检测器识别 “餐桌” 对象时,分类锚点位置向上偏离真实最佳中心(甚至达到披萨的中心),目标检测锚点位置向下偏离真实最佳中心
- TOOD:通过设计新的预测头 T-Head 和样本对齐损失 (TAL),实现分类、定位分支的对齐,使得两个分支的最佳锚框更加接近 (Score/IOU 从上往下看,确实调整了激活中心)。这样可以减少 “低分类概率 + 准确位置预测”、“高概率预测 + 不太准确预测” 这两种情况目标的漏检 (因为这两类目标可能被 NMS 过滤,TOOD 对齐后,这类目标变成 “高分类概率 + 准确位置预测”)
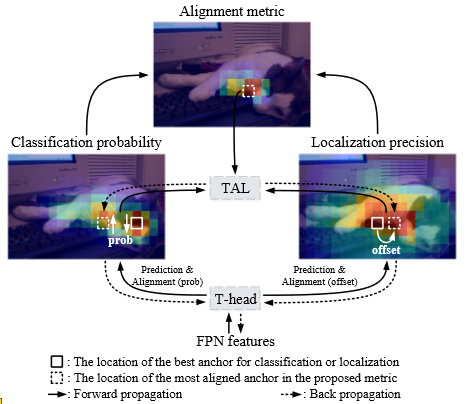
TOOD 的网络结构?
![]()
- T-head 首先对 FPN 特征进行预测,然后 TAL 对这两个任务给出一个一致性的度量,最后 T-head 会自动的调整分类输出和定位输出
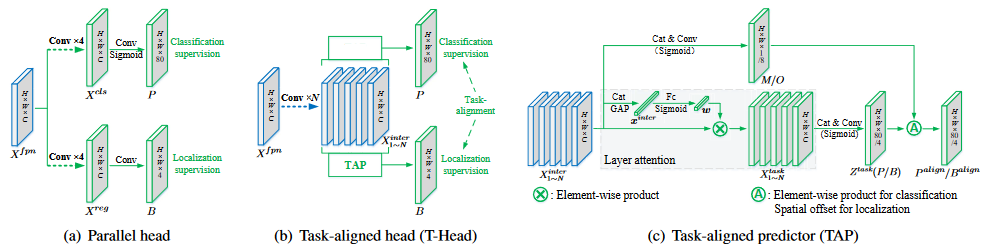
TOOD 的 Task-aligned Head (T-Head)?
![]()
- a)Paraller head:直接基于 FPN 特征输出每个 grid 的分类概率和 box 预测
- b) Task-algined head (T-Head):首先使用 TAP 对 FPN 特征进行对齐,然后输出每个 grid 的分类概率和 box 预测
- c)Task-algined predictor (TAP):基于 FPN 特征,如果输出对齐后的分类 heatmap,则输出 (H, W, 80),如果输出对齐后的定位特征,则输出 (H, W, 4),图示将两个过程融合在一张图上,实际包含两个结构
TOOD 的 T-Head 和 TAP?
![]()
- T-head 和 TAP 的目标是对齐分类、定位两个分支的锚框位置
- 计算 M/O:按照以下公式从 FPN 特征计算得到,其中 M (H, W, 1) 用于对齐分类 headmap,O (H, W, 8) 用于对齐定位 headmap,
- 对齐分类 headmap:基于 M 调整即可
- 对齐定位 headmap: 原始定位输出是 (H, W, 4),结合 O (H, W, 8) 输出对齐后的位置,8 是因为用于定位的 4 个输出都有 x, y 两个方向的调整。公式可知,8 的偶数位置通道用于计算 i,奇数位置通道用于计算 j
TOOD 的样本分配策略?
- Anchor 对齐度量:根据分类的预测概率 s 和定位预测 IOU 计算以下值,该值表示预测与 gt 的相近程度,其中 是自定义参数,控制两者占比
- 样本分配:对于每个 gt,我们选择 m 个具有最大 t 值的 anchor 作为正样本点,其余的为负样本
TOOD 的损失函数 (TAL)?
- 分类损失:为了显式的增加对齐的 anchor 的得分,减少不对齐的 anchor 的得分,用 t 来代替正样本 anchor 的标签。我们发现,当 α 和 β 变换导致正样本的标签变小之后,模型无法收敛,因此,因此使用了归一化的 t,这个归一化有两个性质:1)确保可以有效学习困难样本,2)保持原来的排序。最终借鉴 focal loss 的思想得到分类损失
- 定位损失:使用归一化的 t 来对 GIoU loss 进行了加权
TOOD 的 T-Head 和 TAL 的作用?
![]()
- 由于分类和定位的学习机制不同,两个任务学习到的特征的空间分布可能不同,当使用两个单独的分支进行预测时,会导致一定程度的错位,第一行可以看出分类、定位的最佳定位位置都是分开的,所以其 Score 和 IOU 都是偏低的
- 使用 T-Head 和 TAL 后,分类、定位的最佳定位位置非常接近,其 Score 和 IOU 都更高

参考: