YOLO9000:Better, Faster, Stronger
YOLOv1 的基础上,引入锚框的思想,并通过新的骨干网 Darknet19、批规范化 (BatchNormalization,BN)、先验框、多尺度训练等技术,实现比 YOLOv1 更快、更好的目标
什么是 YOLOv2?
![]()
- YOLOv1 的基础上,通过新的骨干网 Darknet19、批规范化 (BatchNormalization,BN)、先验框、多尺度训练 (Multi-Scale Training) 等技术,实现比 YOLOv1 更快、更好的目标
- YOLOv2 又称 YOLO9000,即通过对 YOLOv2 的分类层进行修改,并通过联合训练目标检测数据集 COCO 及分类数据集 ImageNet,获得对超过 9000 类目标的识别,实现比 YOLOv1 更强的目标
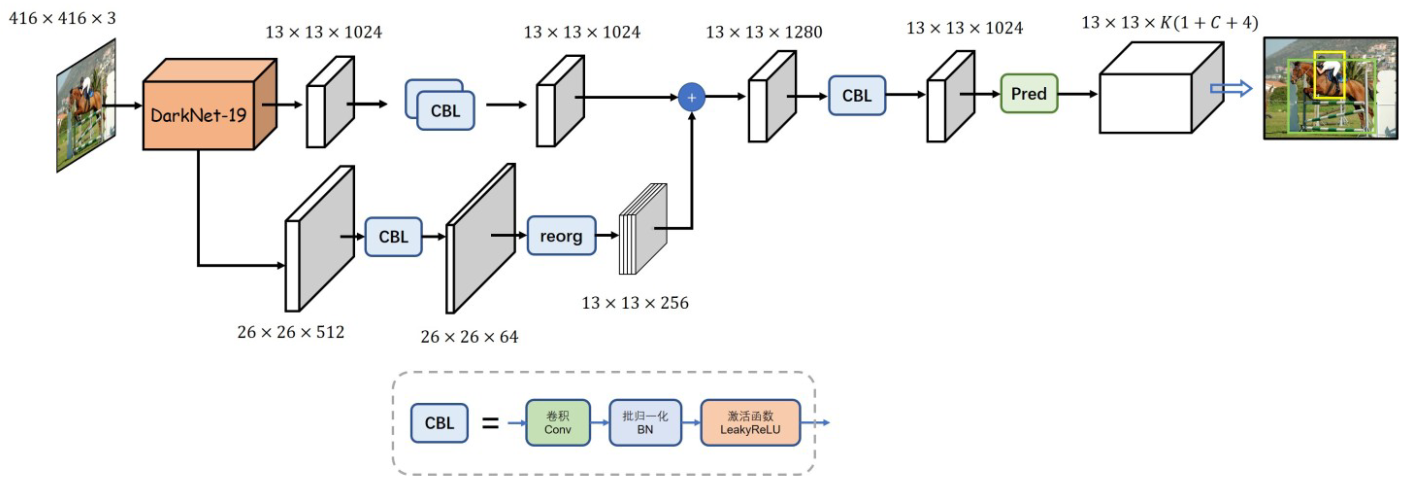
YOLOv2 的网络结构?
![]()
- YOLOv2 的 backbone 使 Darknet19,并使用 C5 的特征做目标检测
- 输入:416x416x3 的图片
- 输出:13x13x125,在 13x13 大小的特征图上做预测,125 指为每个网格预测 5 个框,每个框 20 个类别 + 4 个座标点 + 1 个置信度,一共是长度为 5*(20+4+1)=125 的特征向量

YOLOv2 的正负样本判定?
- YOLOv2 引入锚框(先验框) 的概念,通过计算先验框和 gt 框的 IOU 确定正负样本,为 1 个 gt 框分配 1 个先验框
- 位置判定正负样本: gt 框对应 cell 位置的先验框分为正负样本
- 正样本: 如果 cell 对应的先验框存在 IOU > 阈值,则取 IOU 最大的先验框为正样本,其余先验框忽略
- 负样本: 如果 cell 对应的先验框均 IOU < 阈值,则取 IOU 最大的先验框为负样本,其余先验框忽略
YOLOv2 的正样本制作过程?
- 框的中心: YOLOv1 一样,学习先验框中心和 gt 框的偏差,假设真实座标为
- (1) 计算中心
- (2) 计算映射到的网格
- (3) 计算量化误差,量化误差即是网络学习的目标,可知
- (1) 计算中心
- 框的宽高―
- (1) 计算框的宽、高
- (2) 归一化:图像的宽高通常是远大于 1 的实数,直接用这个做标签,loss 值和其他部分差距很大,因此将其进行归一化处理,最后
- 取对数:因为线性回归数是任意实数,对归一化后的参数取对数即可
- (1) 计算框的宽、高
YOLOv2 的损失如何计算?
![]()
- :表示忽略样本,只计算置信度损失
- :前 128000 次迭代计入误差。注意这里是预测框与先验框的误差,而不是与 gt 框的误差。可能是为了在训练早期使模型更快学会先预测先验框的位置
- 表示预测框是否负责预测物体,该 anchor 与标注框的 IoU 最大对应的预测框负责预测物体

YOLOv2 的训练步骤?
- (1)预训练 Darknet-19: 先在 ImageNet 分类数据集上预训练 Darknet-19,此时模型输入为 224 x 224 ,共训练 160 个 epochs
- (2)高分辨率调整: 将网络的输入调整为 448 x 448 ,继续在 ImageNet 数据集上 finetune 分类模型,训练 10 个 epochs
- (3)训练目标检测网络: 修改 Darknet-19 分类模型为检测模型,移除最后一个卷积层、global avgpooling 层以及 softmax 层,并且新增了三个 3x3x1024 卷积层,同时增加了一传递层(passthrough layer),最后使用 1x1 卷积层输出预测结果,输出的 channels 数为:num_anchors(5+num_classes)*
相比较 YOLOv1,YOLOv2 引入锚框的作用?
![Drawing 2023-02-06 10.05.54.excalidraw]()
- 如图,假设图片上有个待识别的圆形区域,其中 A、B、C 是模型初始化预测值,D 是真实值,根据距离关系,A、B、C 被优化到 D 的难易程度是 A>B>C
- YOLOv1 没有使用任何锚框,所以其初始预测框由模型随机权重决定,所以其收敛更慢
- YOLOv2 引擎锚框,而且其锚框是从大量数据统计出来的,因此其锚框很大概率比随机权重更接近 gt 框,因此其收敛更快

YOLOv2 与 YOLOv1 在类别预测及回归预测的差异?
- YOLOv1: 类别是针对一个 cell 而言的,即每个格子对应 B 个 Bounding Box,每个 cell 预测特征长度是 5 x B +C
- YOLOv2: 类别是对于每个 box 而言,对每个 box 会预测 5 +C 长度的向量,假设数量为 B 个,最终会预测 B x(5 + C)个输出维度
使得 YOLOv2 效果更好 (Better) 的措施有哪些?
![YOLOv2-20230408141842]()
- 批归一化 (Batch Normalization):所有卷积层增加 BN,mAP 提升了 2%。使用 BN,可以去掉 dropout 而不过拟合
- 高分辨率训练 (High Resolution Classifier):原始的 YOLO 预训练分类器网络输入是 224x224,YOLOv2 首先在 ImageNet 上以 448×448 的全分辨率微调分类网络 10 个 epoch。 然后,我们在检测时微调生成的网络。 这种高分辨率分类网络使我们的 mAP 增加了近 4%
- 带 AnchorBox 的卷积 (Convolutional With Anchor Boxes): 使用锚框,我们的准确性会略有下降。 YOLO 仅预测每张图像 98 个框,但使用锚框,我们的模型预测超过 1000 个框。在没有锚框的情况下,我们的中间模型得到 69.5 mAP,召回率为 81%。使用锚框,我们的模型获得 69.2 mAP,召回率为 88%
- 先验框维度聚类 YOLOv2 生成及设置先验框
- 直接位置预测 (Direct location prediction):使用维度聚类和直接预测 bounding box 中心位置,比 FasterRCNN 中的 anchor box 方法提升了近 5% 的 mAP
- 细粒度特征(Fine-Grained Features):添加一传递层(passthrough layer),与 ResNet 的恒等映射相似,传递层通过将相邻的特征图堆叠到不同的通道,而不是空间位置,将较高分辨率和较低分辨率的 feature map 相连。将 26×26×512 特征映射转换为 13×13×2048 特征映射,这样可以直接与原始的特征拼接。这一点改进获得了 1% 的性能提升
- 多尺度训练 (Multi-Scale Training): 不固定输入图像的尺寸,而是在每几次迭代中改变网络的输入图像尺寸。每 10 个 batch,网络随机选择一个新的输入图像尺寸,由于下采样的因子是 32,所以输入尺寸都是 32 的倍数:{320,352,…,608}。这个策略迫使网络学习在不同的输入分辨率下预测好的结果,意味着相同的网络可以实现不同分辨率的检测

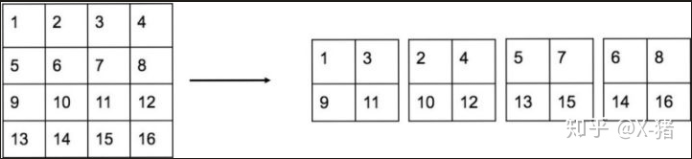
YOLOv2 如何设计传递层(passthrough layer)?
![]()
- 在最后一个 pooling 之前,特征图的大小是 26 x26x512,将其 1 拆 4,直接传递到 pooling 后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图
- 1 拆 4 的规则为
![]()
- 传递层可以扩大感受野,提升对大尺度目标的预测能力

YOLOv2 如何使用高分辨率分类训练网络?
![]()
- 原 YOLO:224×224 大小的图像上训练分类器,检测时分辨率提高至 448。网络须同时切换至学习物体检测,并调整至新的输入分辨率
- YOLOv2:ImageNet 上按 448×448 分辨率,微调分类网络 10 个周期(epochs);检测数据上微调网络。高分辨率的分类网络使 mAP 提高 4%

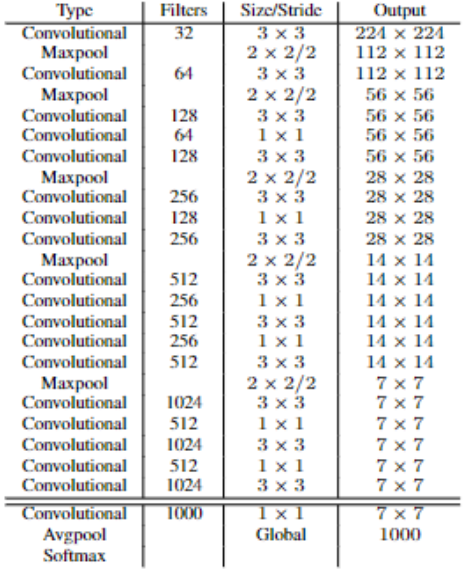
什么是 Darknet19?
![YOLOv2-20230408141845-1]()
- YOLOv2 中被提出,由于其包含 19 个卷积层,因此称为 Darknet19
- 共 19 个卷积层和 5 个最大池化层,DarkNet-19 比 VGG-16 小一些,精度不弱于 VGG-16,但浮点运算量减少到约 1/5,以保证更快的运算速度
使得 YOLOv2 更快 (Faster) 的措施有哪些?
- 设计了全新的分类模 Darknet19 ,并频繁使深度可分离卷积 (depthwiseseparableconvolution),使得计算量大大减少
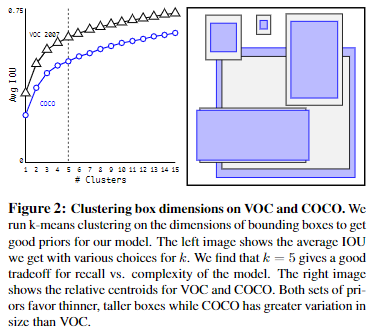
YOLOv2 如何生成、设置先验框?
![YOLOv2-20230408141846]()
- 取代手工选取 anchor box 尺寸,用 K-Means 在训练集的 bounding box 上进行聚类,自动地找到好的先验 box
- 使用 作为 k-means 距离的衡量标准
- 从图可知,当 K=5 时,既能保证模型的复杂度,又能保证一个高的查全率,因此 YOLOv2 每个位置预测 5 个锚框
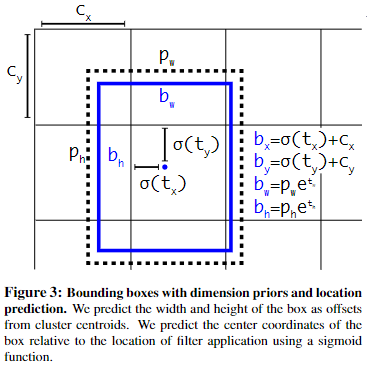
YOLOv2 论文中的直接位置预测 (Direct location prediction)?
![YOLOv2-20230408141846-1]()
- YOLOv1 的预测锚框时,模型不稳定
- 由于 σ 函数将约束在 (0,1) 范围内,所以根据上面的计算公式,预测边框的蓝色中心点被约束在蓝色背景的网格内。约束边框位置使得模型更容易学习,且预测更为稳定
YOLOv2 如何进行联合分类和检测?
- 基本的思路是,如果是检测样本,训练时其 Loss 包括分类误差和定位误差,如果是分类样本,则 Loss 只包括分类误差
- YOLO9000 依然采用 YOLO2 的网络结构,不过 5 个先验框减少到 3 个先验框,以减少计算量。YOLO2 的输出是 13 x 13x5x (4+1+20),现在 YOLO9000 的输出是 13x13x3x (4+1+9418)。假设输入是 416x416x3
YOLOv2 和 SSD 处理多尺度目标的差异?
- SSD 使用不同层次的 CNN 特征做多尺度目标预测,参考 SSD 的网络结构
- YOLOv2 没有在网络结构上针对多尺度优化,而是在训练网络时使用不同分辨率图片进行训练
- 两个处理多目标方法优劣无法直接判定,整体效果上 YOLOv2 更优秀
YOLO9000 的输出如何设计?
![YOLOv2-20230408141847]()
- 标签进行分级分类后,对同一概念下的同义词进行 softmax 分类来完成最终分类 loss 的运算
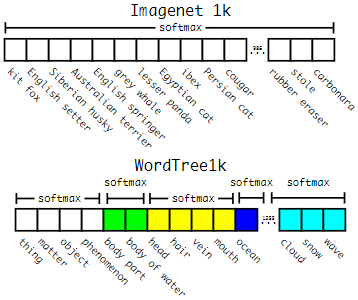
YOLO9000 的 WordTree 如何构建?
![YOLOv2-20230408141847-1]()
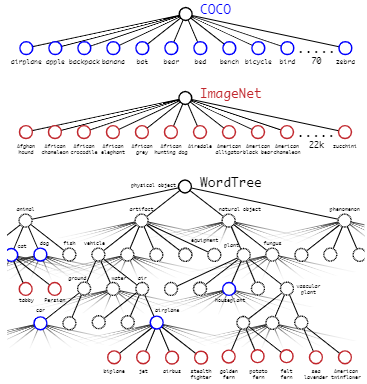
- 要检测更多对象,比如从原来的 VOC 的 20 种对象,扩展到 ImageNet 的 9000 种对象。简单来想的话,好像把原来输出 20 维的 softmax 改成 9000 维的 softmax 就可以了,但是,ImageNet 的对象类别与 COCO 的对象类别不是互斥的。比如 COCO 对象类别有 “狗”,而 ImageNet 细分成 100 多个品种的狗,狗与 100 多个狗的品种是包含关系,而不是互斥关系。一个 Norfolk terrier 同时也是 dog,这样就不适合用单个 softmax 来做对象分类,而是要采用一种多标签分类模型
- YOLO2 于是根据 WordNe5],将 ImageNet 和 COCO 中的名词对象一起构建了一个 WordTree,以 physical object 为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接表达了对象概念之间的蕴含关系(上位 / 下位关系)
![]()
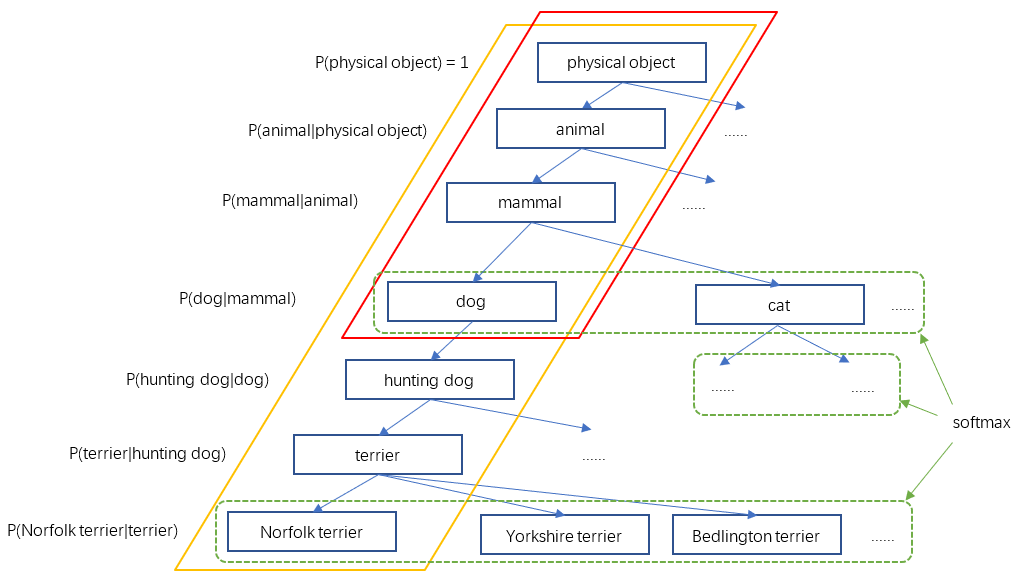
- 整个 WordTree 中的对象之间不是互斥的关系,但对于单个节点,属于它的所有子节点之间是互斥关系。比如 terrier 节点之下的 Norfolk terrier、Yorkshire terrier、Bedlington terrier 等,各品种的 terrier 之间是互斥的,所以计算上可以进行 softmax 操作。上面图 10 只画出了 3 个 softmax 作为示意,实际中每个节点下的所有子节点都会进行 softmax
参考: