YOLOF:You Only Look One-level Feature
YOLOv3-YOLOv5 均是采用 FPN 的多尺度特征 (C3-C7) 做目标预测,YOLOF 则反其道而一种仅用一个尺度 (C5) 就能达到多级检测的方法
什么是 YOLOF?
![YOLOF-20230408141709]()
- YOLOv3-YOLOv5 均是采用 FPN 的多尺度特征 (C3-C7) 做目标预测,YOLOF 则反其道而一种仅用一个尺度 (C5) 就能达到多级检测的方法
- YOLOF 通 DilatedEncoder 模块结构扩大感受野,实现多尺度融合的效果;通 Uniform matching 正负样本分配确保正负样本被均匀分配
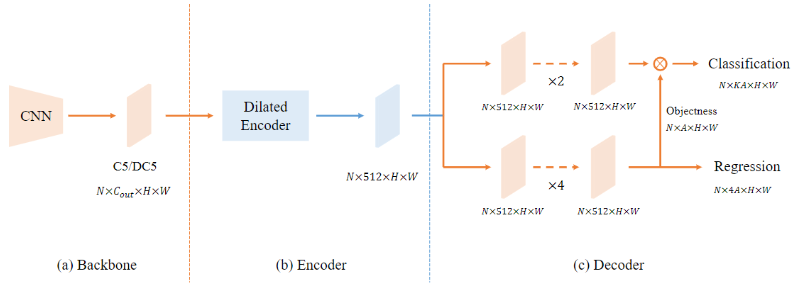
YOLOF 的网络结构?
![YOLOF-20230408141710]()
- Backbone: 采用经典的 ResNet 和 ResNeXt,选取的特征图是 C5,通道数为 2048 且下采样率为 32
- Encoder:使 DilatedEncoder 模块,包含 4 个具有不同系数 (2、4、6、8) 的空洞卷积残差块
- Decoder: RetinaNet 类似,它包含两个并行的 head 分支,用于目标分类和边框回归任务, 为回归分支的每个 anchor 增加一个隐式的 objectness(没有直接监督),最终的分类置信度由分类分支的输出和 objectness 得分相乘得到
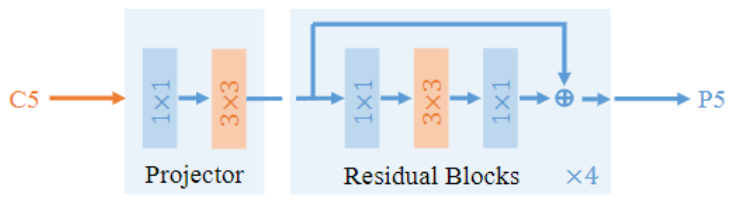
YOLOF 的 DilatedEncoder 模块?
![YOLOF-20230408141711]()
- 目标检测的多尺度融合:主要使空间金字塔池化 (SpatialPyramidPooling,SPP)、特征金字塔网络 (FeaturePyramidNetwork,FPN)、PAN 等模块进行,但是 YOLOF 的出发点就是不采用任何的融合方法,所以不使用这些结构
- 融合多尺度特征后做单 head 预测:位于多尺度特征融合与 DilatedEncoder 模块之间,这种方法相比较 DilatedEncoder 更为复杂,分支越多,推理速度越慢
![]()
- YOLOF 利用空洞卷积搭建一个具有多个感受野的模块,他串联 4 个具有不同系数 (2、4、6、8) 的空洞卷积,并结合残差连接将两种不同感受野结合起来。C5 的特征经过 DilatedEncoder 模块后,得到的 P5 包含多个感受野下的特征
YOLOF 的 UniformMatcher 正样本分配?
- 一般基于 IOU 的标签分配方法,使得大物体匹配很多的 anchor,小物体相对较少,这在多级检测的可以缓解这个问题,但是对于 YOLOF 单级检测就不行了
- 为了解决正负样本分配问题的方法,对于给定的 target,计算他与所有 anchor 的 L1 距离,保留 topk 的结果,再结合 IOU>0.15 筛选得到每个 target 的 anchor。理想情况下,每个 target 都公平匹配上 K 个样本
- 在训练阶段,为了保证训练的稳定,YOLOF 在 Max-IoU 匹配之后,设置 IoU 阈值以忽略大 IoU (>0.7) 负锚和小 IoU (<0.15) 正锚。比如当前标签是猫,网络预测了一个狗的标签(负样本,因为预测得不对),而这个狗的框和猫的真实框的 IoU 超过了 0.7,那我们就忽略它的类别损失,不去回归。这种在训练过程中的动态调整有助于稳定 YOLOF 的训练,可以提升性能
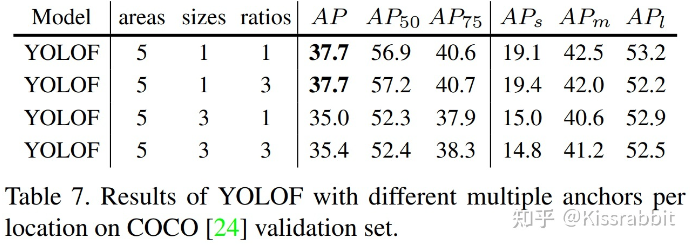
YOLOF 的 anchor 的设置?
![]()
- YOLOF 最终只采用了面积为 32、64、128、256、512 这 5 种大小的配置,且每一种配置下的长宽比仅是 1:1,没有 RetinaNet 中的 1:3 和 3:1 这些长方形配置
YOLOF 的损失函数?
- 类别损失:Focal loss
- 位置损失:GIoU loss