SSD:Single Shot MultiBox Detector
和 YOLOv1 的思想类似,但是针对 6 个尺度特征输出目标预测结果
什么是 SSD?
![]()
- 是一个端到端的模型,同时借鉴 FasterRCNN] 的锚框 (Anchor) 机制的想法,使得检测效果较定制化边界框 YOLOv1 有比较好的提升
- 目标检测的思想 YOLOv1 划分网格的思想一致,差异在于 SSD 对于每个单元的每个先验框作类别及位置的预测,YOLOv1 对每个单元作类别预测,对单元下的先验框作位置预测
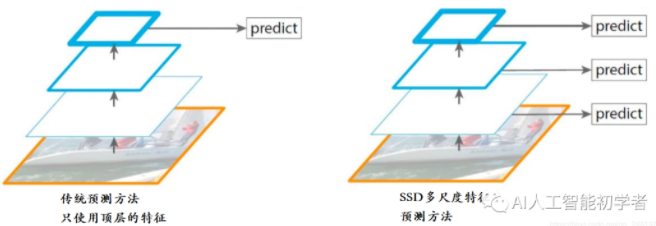
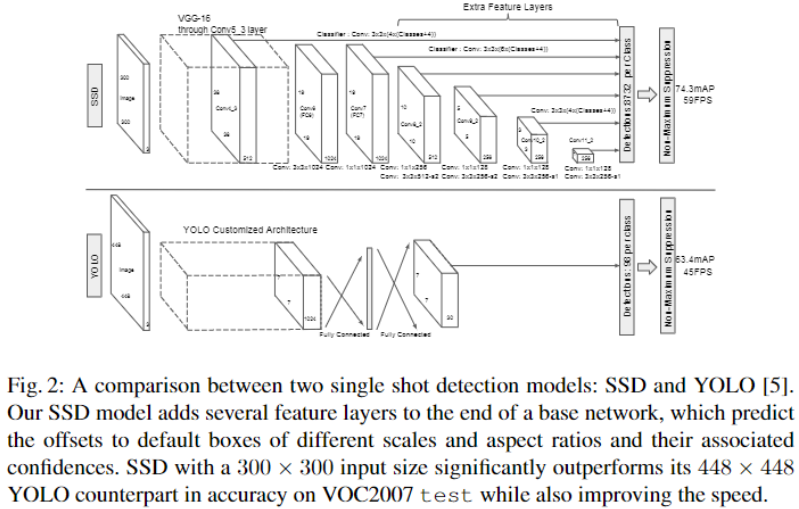
SSD 的网络结构?
![SSD-20230408141624-1]()
- 在 VGG16 的基础上,额外添加了 6 层辅助卷积层,目的是为了识别不同大小的目标
- 输入:300x300
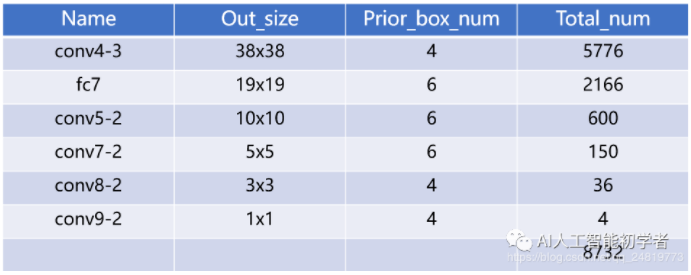
- 输出:包含 6 个尺度共计 8732 个先验框的预测,其中大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体
SSD 的损失函数?
- 整个过程的误差分为两部分:softmax 分类误差和边框回归误差
- 分类误差:使交叉熵损失 (CrossEntropy Loss) 计算正负样本的交叉熵和
- 边框回归误差:采平滑绝对值损失 (SmoothL1 Loss) ,
SSD 与 YOLOv1 比较?
![]()
- (1) 检测头不同:SSD 采用 CNN 来直接进行检测,而不是像 YOLOv1 那样在全连接层之后做检测
- (2) 多尺度不同:SSD 提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体,YOLOv1 只在 C6 特征上检测
- (3) 锚框:SSD 采用了不同尺度和长宽比的先验框(在 FasterRCNN 中叫做锚),YOLOv1 没使用
- (4) cell 处理:SSD 对于每个单元的每个先验框,都包含类别 + 位置预测,即对每个 cell 预测 Bx (5+C)。而 YOLO 每个 cell 只预测一次类别,即对每个 cell 预测 Bx5+C,这也是 YOLOv2 与 YOLOv1 的主要差别
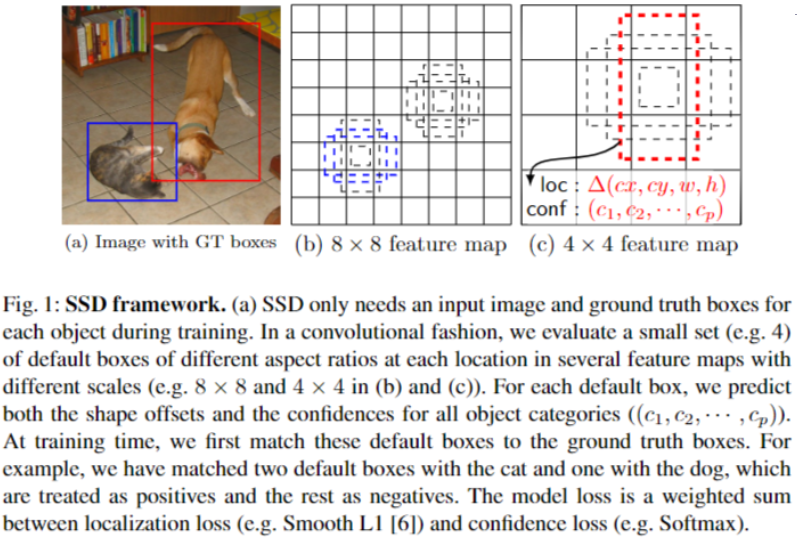
SSD 为什么需要设置先验框?
![SSD-20230408141626]()
- YOLOv1 没有针对数据的先验框,训练初始预测框由随机权重决定,所以需要在训练过程中自适应目标的形状,收敛较慢
- SSD 的训练初始预测框是先验框,先验框是比随机权重得到框更加接近 gt 框,因此其收敛更快
SSD 如何设计不同大小的先验框?
- 先验框大小由尺度和长宽比决定,假设提供 2 个集合,尺度集合和长宽比集合
- SSD 分析 6 个尺度,每个尺度单元分别预测个框,所以总共预测 4、6、6、6、4、4 个先验框,共计 8732 个
![]()
- 大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体
SSD 如何进行标签匹配?
![]()
- (1) 确保每个 gt 框都有先验框:找到与 gt 框 IOU 最大的先验框作为该 gt 框的正样本
- (2) IOU 阈值匹配多个先验框:剩下的先验框若与某个 ground truth 的 IOU 大于一个阀值也和该 gt 框匹配。如果多个 gt 框与某个先验框 IOU 大于阈值,那么先验框只与 IOU 最大的那个先验框进行匹配
- (3) 负样本:与 ground truth 匹配的先验框为正样本,先验框没有与任何 ground truth 进行匹配则是负样本

SSD 如何做多 featrue map 预测框的合并?
- SSD 在多尺度预测到目标后,根据目标的置信度进行排序,并使非极大值抑制(NMS) 进行预测框的筛选
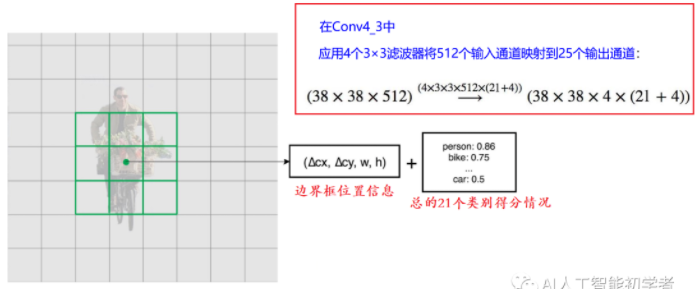
SSD 如何使用 3x3 的小卷积核进行预测分类结果和边界框?
- 对每个单元应用 3×3 卷积滤波器以进行预测 (这些滤波器像常规 CNN 滤波器一样计算结果)。每个滤波器输出 25 个通道:21 个类别分数 +1 个边界框的信息
![]()
SSD 训练时的正负样本比例?
- 根 SSD 设计不同大小的先验框规则 ,SSD 共有 8732 个先验框
- 为了保证正负样本尽量平衡,SSD 采用难负例挖掘 (hard negative mining),就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的 top-k 作为训练的负样本,以保证正负样本比例接近 1:3
SSD 的预测过程?
![]()
- (1) 对于每个预测框,首先根据类别分数确定类别与置信度值,并过滤掉属于背景的预测框
- (2) 阈值过滤:然后根据置信度阈值(如 0.5)过滤掉阈值较低的预测框
- (3) 解码到原图:对于留下的预测框进行解码,根据先验框得到其真实的位置参数
- (4) 取 TopK:一般需要根据置信度进行降序排列,然后仅保留 top-k(如 400)个预测框
- (5) 非极大值抑制(NMS):过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了
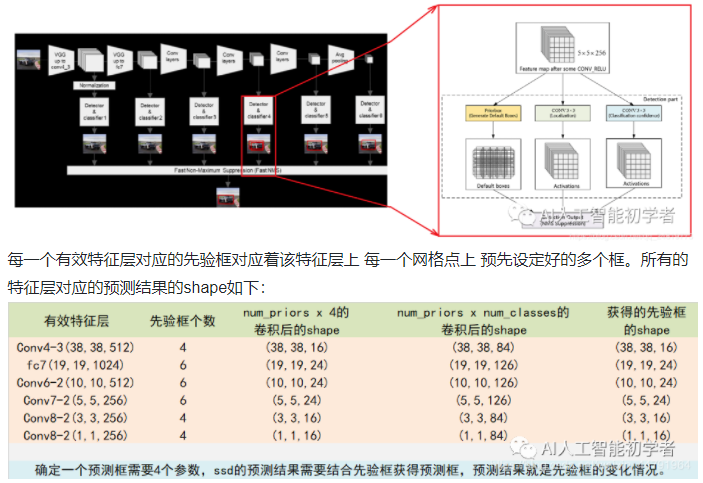
什么是 MultiBox?
- 一种快速与类别无关边界框回的方法,MultiBox 上完成的工作中使用 Inception block 风格的卷积网络
![]()
- MultiBox 采用锚框 (Anchor) 作为预测的初始化 bounding boxes,并回归与 groundtruth boxes 最接近的预测 boxes
- 每个特征图单元包含 11 个先验(8x8、6x6、4x4、3x3、2x2),在 1x1 特征图上只有一个,因此每张图像总共有 1420 个先验,从而能够在多个尺度上对输入图像进行稳健的覆盖,以检测各种尺寸的对象
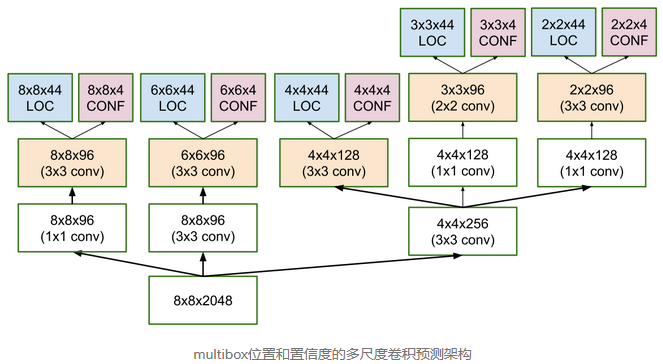
SSD 与 MultiBOX 在边界框回归上的区别?
- SSD 使用固定的先验,每个特征图单元都与一组不同尺寸和纵横比的默认边界框相关联。这些先验是手动(但仔细)选择的,而在 MultiBox 中,选择它们是因为它们相对于基本事实的 IoU 超过 0.5
- MultiBox 不执行对象分类,而 SSD 执行。 因此,对于每个预测的边界框, c 为数据集中的每个可能的类计算