GoogLeNetv1:Going deeper with convolutions
从 GoogleNetv1 开始,神经网络设计由类似 VGGNet 关注深度转向 "宽度"
什么是 GoogleNetv1?
![]()
- GoogleNetv1 中参考 NIN 网络,设计出多分支并行的模块 Inception block
- 从 GoogleNetv1 开始,神经网络设计由类似 VGGNet 关注深度转向” 宽度 “
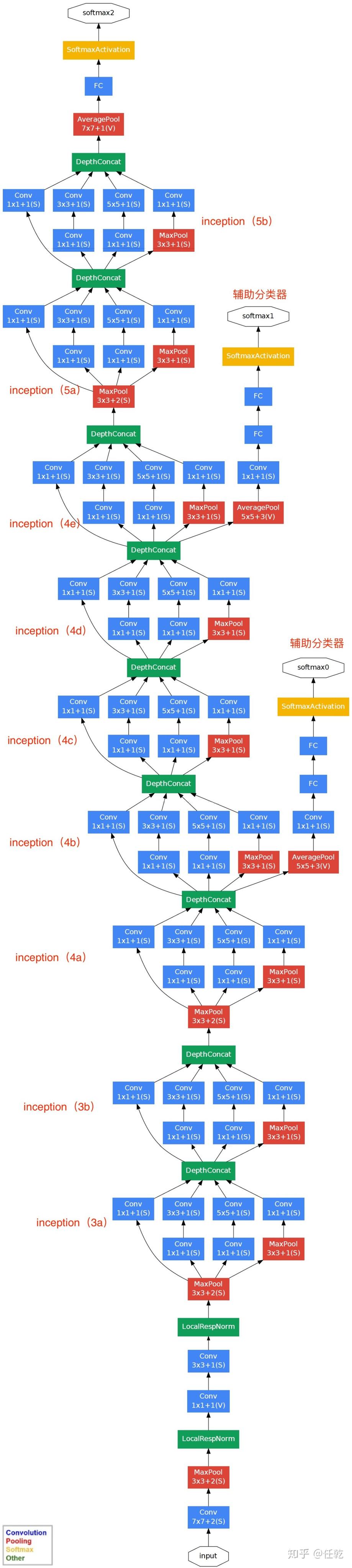
GoogleNetv1 的网络结构?
![]()
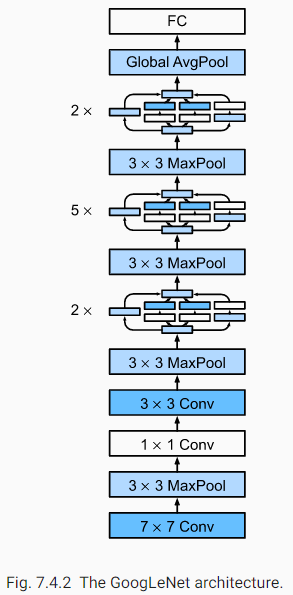
- GoogleNetv1 对网络的宽度进行了扩展,整个网络由 3+3+3 总共九个 inception 模块组成的,每个 Inception 有两层,加上开头的 3 个卷积层和输出前的 FC 层,总共 22 层
- 像 NIN 一样,网络使用全局池化 (Global Pooling) 替代全连接层,作为分类层
GoogleNetv1 的 Inception block 模块?
![]()
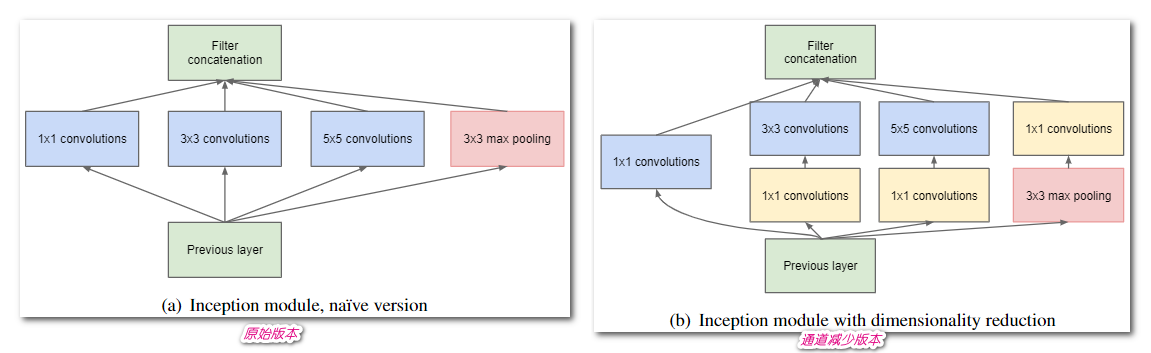
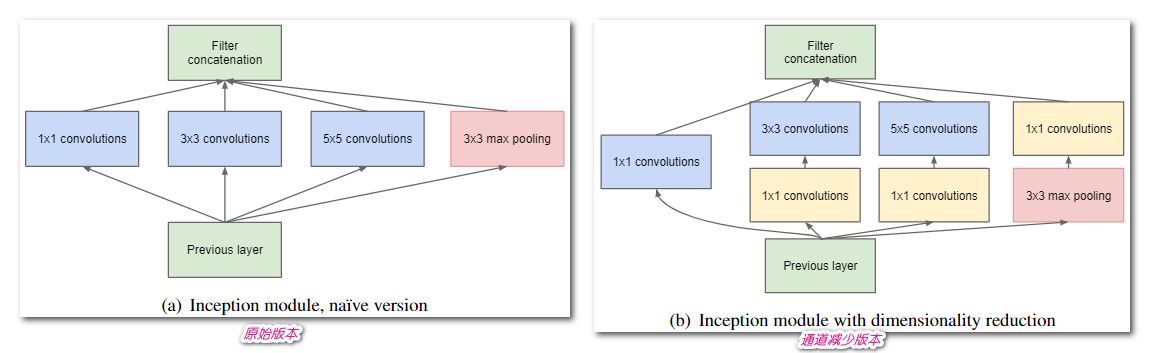
- 在 Inception 模块中,1×1、3×3、5×5 卷积和 3×3 最大池化在输入端以并行方式执行,它们的输出堆叠在一起以生成最终输出
- 原始版本: 使用 3 种滤波器进行卷积,外加最大池化
- 降维版本: 考虑到神经网络训练耗时,在 3x3、5x5 前面使用 1x1 卷积核调整通道数
GoogleNetv1 的损失函数?
- GoogleNetv1 有 2 个辅助损失及 1 个最终损失,其中辅助损失 30% 进行梯度更新,每个损失都是计算交叉熵损失 (CrossEntropyLoss)
GoogleNetv1 的 Inception block 模块拼接特征的作用?
- 解释 1: 在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确
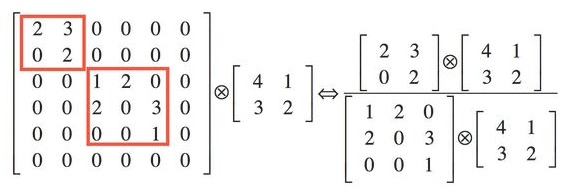
- 解释 2: 利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。举个例子图 4 左侧稀疏矩阵和一个 2x2 的矩阵进行卷积,需要对稀疏矩阵中的每一个元素进行计算;如果像图 4 右图那样把稀疏矩阵分解成 2 个子密集矩阵,再和 2x2 矩阵进行卷积,稀疏矩阵中 0 较多的区域就可以不用计算,计算量就大大降低
![]()
- 解释 3:赫比 (Hebbian) 原理 指出预先把相关性强的特征汇聚,就能起到加速收敛的作用
GoogleNetv1 的训练辅助分类器?
![]()
- 由于网络的深度相对比较大,能够在所有层保证梯度能传播是一个问题。对此增加了 2 个辅助分类器,在训练期间辅助分类器的权重为 0.3,在预测时,这些层会被丢弃,这些层有助于解决梯度消失问题并提供正则化
GoogleNetv1 如何应用在目标检测任务?
- 通过 MultiBox 和选择性搜索 (SelectiveSearch,SS) 方法得到一系列的候选框,将这些候选框输入到 GoogLeNet 神经网络中进行分类,得到最终的结果
Inception 系列网络结构?
- 在 Inception 出现之前,大部分 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。而 Inception 则是从网络的堆叠结构出发,提出了多条并行分支结构的思想,后续一系列的多分支网络结构均从此而来
- 目前 Inception 系列具体网络结构包括:Inceptionv1、 Inceptionv2、 Inceptionv3、 Inceptionv4、 Xception
什么是赫比 (Hebbian) 原理?
- 赫布认为 “两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种‘组合’,其中一个神经元的兴奋会促进另一个的兴奋”。比如狗看到肉会流口水,反复刺激后,脑中识别肉的神经元会和掌管唾液分泌的神经元会相互促进,“缠绕” 在一起,以后再看到肉就会更快流出口水
- 用在 Inception block 中就是要把相关性强的特征汇聚到一起,把 1x1,3x3,5x5 的特征分开。因为训练收敛的最终目的就是要提取出独立的特征,所以预先把相关性强的特征汇聚,就能起到加速收敛的作用