GoogleNetv2:Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift
在 GoogleNetv1 的基础上修改 Inception block 得到,并且引入历史性的 BN 层,使得网络训练的调参更简单
什么是 GoogleNetv2?
![]()
- 又名 Inceptionv2,主要是在 GoogleNetv1 网络基础上,加入批规范化 (Batch Normalization,BN)
- BN 的加入,使得神经网络的训练不再小心翼翼设计学习率、初始化、dropout 等
GoogleNetv2 的网络结构?
![]()
- 在 GoogleNetv1 网络中加入批规范化 (Batch Normalization,BN) ,并将 Inception block 的 5x5 卷积改为 2 个 3x3 卷积

GoogleNetv2 的 Inception block?
- 相比较 GoogleNetv1 的 Inception block,将其中的 5x5 卷积改为 2 个 3x3 卷积
GoogleNetv2 的损失函数?
- 论文没有说使用辅助分类器,一般分类损失使用交叉熵损失 (CrossEntropyLoss)
什么是内部协变量偏移 (Internal Covariate Shift,ICS)?
![]()
- 多层神经网络中,每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新,这就是内部协变量偏移
- 为了训好模型,以前神经网络训练前一般对输入数据进行白化操作 (Whitening),但是这操作只在输入层进行,后来需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略
- 批规范化 (Batch Normalization,BN) 每层输入可以缓解该问题

为什么内部协变量偏移导致模型训练困难?
- 数据分布不稳定: 多层神经网络中,每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新
- 神经元存在死亡: 如何不解决 “内部协变量偏移”,神经网络的激活值整体分布逐渐往非线性函数的易饱和区域靠近,从而导致反向传播时低层神经网络的梯度消失(为 0),这是训练深层神经网络时收敛较慢的本质原因
- BN 通过对输入数据进行规范化,每次都对激活值进行修正,确保层之间激活值的分布保持稳定来缓解该问题
什么是白化操作 (Whitening)?
![]()
- 白化的目的是去除输入数据的冗余信息。假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的;白化的目的就是降低输入的冗余性
- 白化处理分 PCA 白化和 ZCA 白化,PCA 白化保证数据各维度的方差为 1,而 ZCA 白化保证数据各维度的方差相同。PCA 白化可以用于降维也可以去相关性,而 ZCA 白化主要用于去相关性,且尽量使白化后的数据接近原始输入数据

白化操作与 BN 的区别?
- 白化操作 (Whitening) 是在数据的预处理阶段,就是输入模型之前处理,而 BN 是在模型中处理
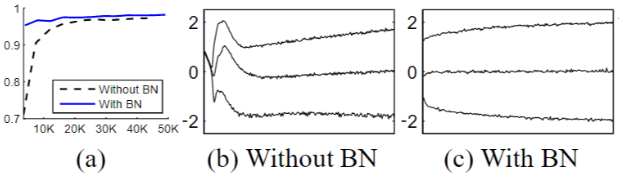
使用 BN 对学习率有什么影响?
![]()
- 学习率问题: 在传统的深度网络中,过高的学习率可能会导致梯度爆炸或消失,并陷入较差的局部极小值,BN 引入后可以设计更大的学习率
- 收敛速度: 通过比较各个曲线的收敛点,可知加了 BN 的实验,可以使用更大学习率,其收敛速度更快
- Sigmoid 的饱和问题: 通过观察 BN-×5-Sigmoid ,加入 BN 后,Sigmoid 的饱和问题可以被消除

使用 BN 对网络权重有什么影响?
- 初始化权重: 可以不用精心设计权值初始化
- 权重 L2 衰减: 可以不用 L2 或者较小的权重衰减 (weight decay)
使用 BN 对 Dropout 有什么影响?
- BN 可以实现了丢弃正则化 (regularization) 对模型正则化的作用,因此可以不用 dropout 或较小的丢弃正则化 (Dropout)