VGG:Very Deep Convolutional Networks for Large-Scale Image Recognition
VGGNet 探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了 16~19 层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好
什么是 VGGNet?
![]()
- VGGNet 探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了 16~19 层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好
- VGGNet 使用多个小卷积 替代一个大的卷积核,在减少参数的同时,增加模型容量
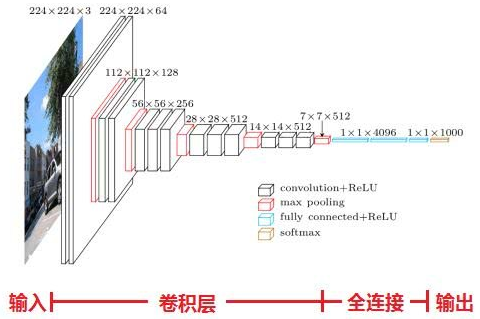
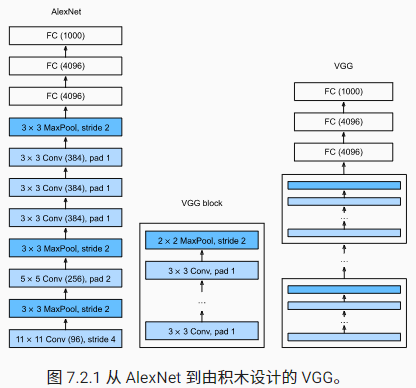
VGGNet 网络结构?
![]()
- VGGNet 模仿 AlexNet 的网络结构,使用 "卷积 + 激活 + 池化" 的方式提取特征, 从头到尾全部使用的是 3x3 的卷积核和 2x2 的池化核 ,按照 VGGNet 的基本块 堆叠
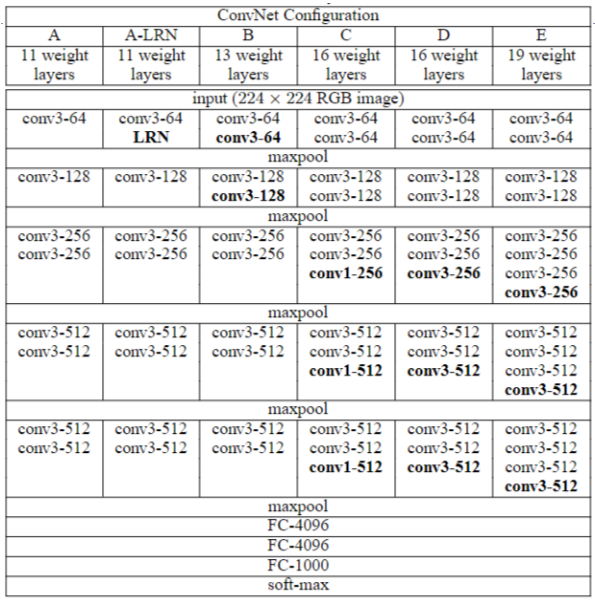
- VGG16 包含了 16 个隐藏层(13 个卷积层 + 3 个全连接层),如图中的 D 列所示
- VGG19 包含了 19 个隐藏层(16 个卷积层 + 3 个全连接层),如图中的 E 列所示
VGGNet 的基本块是怎么样的?
- 一个 VGGNet 块由一系列 "卷积 + 激活 + 最大池化" 组成,使用 3×3、填充为 1 的卷积核(保持高度和宽度)和 2×2 步长为 2 的最大池化(每个块后的分辨率减半)
1
2
3
4
5
6
7
8
9
10
11import torch
from torch import nn
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
VGGNet 的损失函数?
- VGGNet 最后输出 1000 类的分类问题,并使用 softmax 激活函数,计算损失使用负对数似然损失 计算
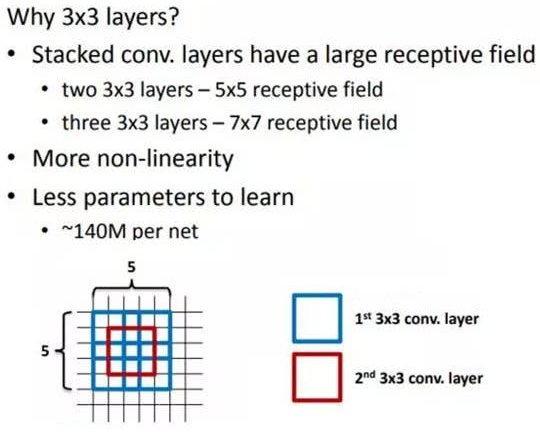
VGGNet 为什么使用小卷积核替代大卷积核?
- 图片的 A、B 采用相似的网络结构,但是 B 使用小卷积核,而 A 使用大卷积核,可以看出:多个小卷积核比单个大核性能好
![]()
- 就感受野 (receptive field) 而言,2 个 3x3 的卷积等价 1 个 5x5 卷积,3 个 3x3 的卷积等价 1 个 7x7 的卷积
![]()
- 除了感受野和参数问题外,ZFNet 有实验证明前期大卷积核导致卷积神经网络的 aliasing 现象 ,进而导致网络学习能力变差
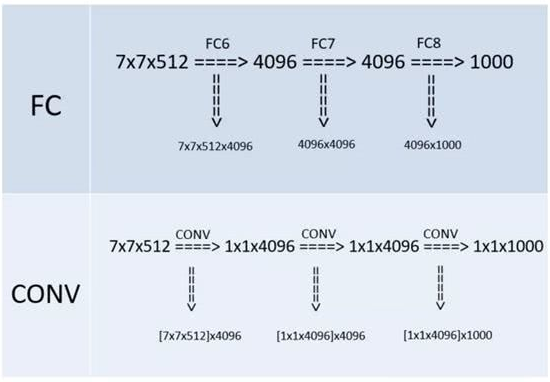
VGGNet 中,如何将全连接转为卷积的?
- 在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入
![]()
- 例如上图 7x7x512 的层要跟 4096 个神经元的层做全连接,则替换为对 7x7x512 的层作通道数为 4096、卷积核为 1x1 的卷积
- “全连接转卷积” 的思路是 VGG 作者参考了 OverFeat 的工作思路
- 经过上面转换,参数量是对等的,但是卷积核的数量大大,实际不使用
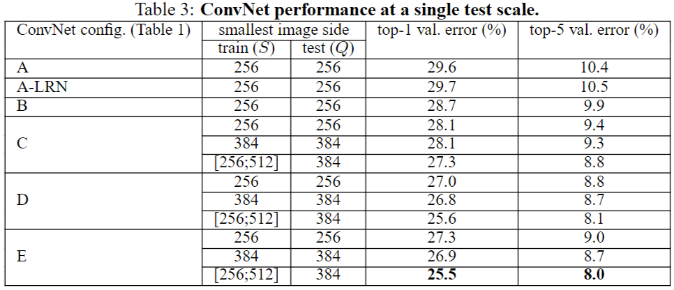
VGGNet 中,随着深度增加,神经网络有什么变化?
![]()
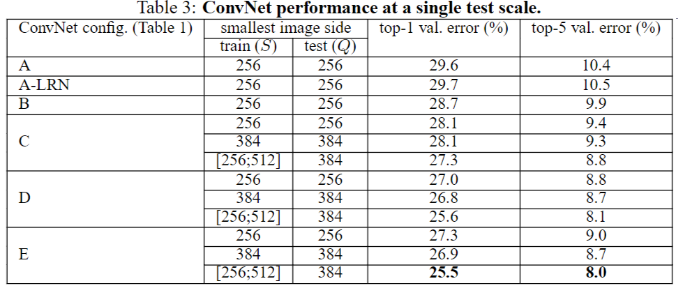
- 从 11 层的 A 到 19 层的 E,无论是单尺度还是多尺度,随着网络深度增加,网络的 top1 和 top5 的错误率下降很明显
VGGNet 实验证明 LRN 对提升网络性能是否有作用?
![]()
- 上图 A-LRN 相比较 A,没有性能提升,说明 AlexNet 使用的 LRN 没有带来性能提升
VGGNet 和 AlexNet 在网络结构上有什么差异?
![]()
- VGGNet 模仿 AlexNet 的网络结构,使用 "卷积 + 激活 + 池化" 的方式提取特征
- VGGNet 卷积全部使用 3x3 的小卷积核,而不是 AlexNet 的 7x7 大卷积核
- VGGNet 池化全部使用 2x2 的池化核 ,而不是 AlexNet 的 3x3
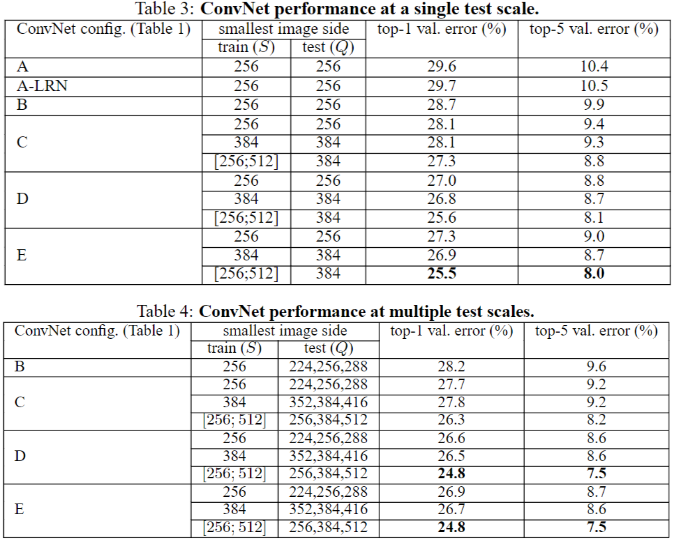
VGGNet 如何做多尺度训练?
- 将原始图像缩放到不同尺寸 S,然后再随机裁切 224′224 的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果
- 方法 1:单尺度,固定 S,取 S=256 和 S=384,384 的网络根据 256 训练的参数作为初始化参数,利用更小的学习率来更新参数
- 方法 2:多尺度训练,S 的取值范围为 [256,512],随机采样 S 来单独地重新缩放每个训练图像(类似于缩放),在 384 网络参数的基础上继续进行训练
- 权重初始化规则:作者定义了不同深度的网络结构,对于最浅深度的网络结构,作者采用随机初始化(作者设置的深度认为是足够浅,浅到利用随机初始化也可以得到不错的结果。)对于更深一级的网络,原有的层级参数使用已经训练好的,新增的网络参数继续使用随机初始化
VGGNet 如何做多尺度预测?
- 单尺度图像的测试:如果训练图像是单尺度,那么将测试图像的大小变成训练图像的尺度。如果训练图像是多尺度,那么测试图像的大小取多尺度的最小值和最大值的平均值
- 多尺度图像的测试: VGG 借鉴 OverFeat 的训练与测试过程 ,根据训练时的输入尺度,选择三个不同的测试图像尺度,对于多尺度训练的,测试尺度选择训练尺度的最小值,最大值,平均值),由于输入图像的不同,最后得到的概率图的空间分辨率不同(取决于输入图像的大小,如果尺寸按照训练时输入,输出是 1x1x1000,大于训练尺寸则使出 nxnx1000) ,所以利用平均池化得到固定的特征向量。此时得到每个尺度图像的概率向量。测试图像还可以进行翻转,将得到的未反转的和反转之后的结果进行平均得到最后的结果。(未反转和反转的各包含 3 个尺度,然后 6 个概率向量求平均值)