01-TensorRT 快速入门指南
什么是 TensoRT?
![01-TensorRT快速入门指南-20230704212129]()
- TensorRT 的核心是一个旨在加速 NVIDIA 的 GPU 进行高性能推理的 C++ 库
- TensorRT 是一个高性能深度学习推理平台。包括一个深度学习推理优化器和运行时,为深度学习推理应用程序提供低延迟和高吞吐量
- Tensorrt 为深度学习推理应用程序(如视频流、语音识别、推荐和天然语言处理)的生产部署提供了 int8 和 fp16 优化
安装 TensorRT 的 3 种方法?
- 使用容器安装 tensorRT
- NVIDIA 都会发布定制的 GPU 优化虚拟机映像 (VMI),这些 VMI 针对最新一代 NVIDIA GPU 的性能进行了优化。使用这些 VMI 在带有 NVIDIA A100、V100 或 T4 GPU 的云托管虚拟机实例上部署 NGC 托管的容器
- 使用 debian 文件安装 tensorRT
- 根据系统版本及 CPU 架构,从 Installation Guide :: NVIDIA Deep Learning TensorRT Documentation 选择下载 deb 文件
- 使用以下命令安装 tensorrt
1
2
3
4sudo dpkg -i nv-tensorrt-repo-${os}-${tag}_1-1_amd64.deb
sudo apt-key add /var/nv-tensorrt-repo-{os}-${tag}/7fa2af80.pub
sudo apt-get update
sudo apt-get install tensorrt - 使用以下命令安装 python API
1
sudo apt-get install python3-libnvinfer-dev
- 使用以下命令安装解析器
1
2sudo apt-get install uff-converter-tf
sudo apt-get install onnx-graphsurgeon - 验证安装
1
dpkg -l | grep TensorRT
- pip Wheel File Installation 使用独立的 pip 文件安装 tensorRT
- 独立的 pip 安装文件,完全独立于.deb 核.rpm 包,不需要额外安装这些东西
- 独立的 pip 文件安装仅支持 python3.5-3.9、cuda11.3、Linux 操作系统、x86_64 架构
- 安装 nvidia-pyindex
1
2python3 -m pip install --upgrade setuptools pip
python3 -m pip install nvidia-pyindex - 安装 nvidia-tensorrt
1
2# 此命令将拉取所需的cuda及cudnn
python3 -m pip install --upgrade nvidia-tensorrt - 验证安装
1
2
3
4python3
>>> import tensorrt
>>> print(tensorrt.__version__)
>>> assert tensorrt.Builder(tensorrt.Logger())
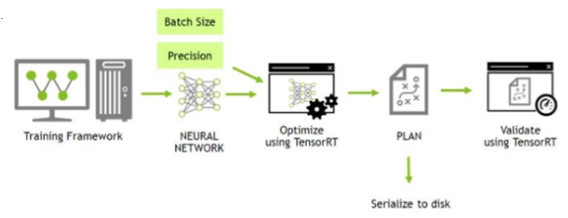
TensorRT 用户必须遵循哪五个基本步骤来转换和部署他们的模型?
- 导出模型: 例如将 Pytorch 模型导出为 onnx 模型
- 选择批大小: 如果优先考虑延迟,则选择小批量;如果优先考虑吞吐量,则选择更大的批量,单次处理时间变长,但是平均请求时间更短
- 选择精度: 较低的精度可以为您提供更快的计算和更低的内存消耗,TensorRT 支持 TF32、FP32、FP16 和 INT8 精度
- 转换模型: ONNX->TensorRT 转换最通用和最高效的路径之一
- 部署模型: 有两种类型:C++ 和 Python
Tensorflow 导出 ONNX 模型
- 加载模型
1
2from tensorflow.keras.applications import ResNet50
model = ResNet50(weights='imagenet') - 使用 keras2onnx 转为 onnx
1
2import keras2onnx
onnx_model = keras2onnx.convert_keras(model, model.name) - 设置批处理大小
1
2
3
4
5
6import onnx
BATCH_SIZE = 64
inputs = onnx_model.graph.input
for input in inputs:
dim1 = input.type.tensor_type.shape.dim[0]
dim1.dim_value = BATCH_SIZE - 保存 onnx
1
2model_name = "resnet50_onnx_model.onnx"
onnx.save_model(onnx_model, model_name)
Pytorch 导出为 ONNX 模型
- pytorch 加载模型
1
2import torchvision.models as models
resnext50_32x4d = models.resnext50_32x4d(pretrained=True) - pytorch 设置批次
1
2
3import torch
BATCH_SIZE = 64
dummy_input=torch.randn(BATCH_SIZE, 3, 224, 224) - pytorch 保存模型
1
2import torch.onnx
torch.onnx.export(resnext50_32x4d, dummy_input, "resnet50_onnx_model.onnx", verbose=False)
如何将 ONNX 转换为 TensorRT 引擎?
- using trtexec 使用可执行文件 trtexec
1
trtexec --onnx=resnet50_onnx_model.onnx --saveEngine=resnet_engine.trt --explicitBatch
TensoRT 的 C++ API 和 Python API 的区别?
- C++ API 应用需求上开销较低,以及安全性非常重要的场景
- Python API 主要优点是数据预处理和后处理都很容易使用,因为您可以使用各种类型的库,如 NumPy 和 SciPy,更易于原型设计,调试,测试
如何使用 C++API 构建模型?
- 从文件反序列化 TensorRT 引擎
1
2
3
4std::vector engineData(fsize);
engineFile.read(engineData.data(), fsize);
util::UniquePtr runtime{nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger())};
util::UniquePtr mEngine(runtime->deserializeCudaEngine(engineData.data(), fsize, nullptr)); - 构建 TensorRT 执行上下文
1
2
3
4
5
6
7
8
9
10// 设置上下文的入口和出口的shape
auto input_idx = mEngine->getBindingIndex("input");
assert(mEngine->getBindingDataType(input_idx) == nvinfer1::DataType::kFLOAT);
auto input_dims = nvinfer1::Dims4{1, 3 /* channels */, height, width};
context->setBindingDimensions(input_idx, input_dims);
auto input_size = util::getMemorySize(input_dims, sizeof(float));
auto output_idx = mEngine->getBindingIndex("output");
assert(mEngine->getBindingDataType(output_idx) == nvinfer1::DataType::kINT32);
auto output_dims = context->getBindingDimensions(output_idx);
auto output_size = util::getMemorySize(output_dims, sizeof(int32_t)); - 拷贝数据到 GPU
1
2
3
4
5
6
7
8
9
10void* input_mem{nullptr};
cudaMalloc(&input_mem, input_size);
void* output_mem{nullptr};
cudaMalloc(&output_mem, output_size);
const std::vector mean{0.485f, 0.456f, 0.406f};
const std::vector stddev{0.229f, 0.224f, 0.225f};
auto input_image{util::RGBImageReader(input_filename, input_dims, mean, stddev)};
input_image.read();
auto input_buffer = input_image.process();
cudaMemcpyAsync(input_mem, input_buffer.get(), input_size, cudaMemcpyHostToDevice, stream); - 执行推理
1
2void* bindings[] = {input_mem, output_mem};
bool status = context->enqueueV2(bindings, stream, nullptr); - 复制结果回内存
1
2
3
4
5auto output_buffer = std::unique_ptr{new int[output_size]};
cudaMemcpyAsync(output_buffer.get(), output_mem, output_size, cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
cudaFree(input_mem);
cudaFree(output_mem);