Imagen:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
和 DALL-E-2 类似过程,但是 Imagen
直接基于文本信息扩散为低分辨的图片编码,然后再使用超分辨率网络上采样。结构更简单)
- (图片,文本)<->CLIP-> 图片编码,文本编码
- 文本编码 ->DDPM-> 图片编码
- 图片编码 -> 超分辨率网络 -> 高分辨率图
什么是 Imagen ?
![]()
- 继 DALLE2 的后续工作,整体框架比 DALLE2 简单的多,主要是利用大语言模型提取了文本特征,使得生成的图像更加能体现文本内容
- 除此之外,还提出 Efficient U-Net 来节省内存,使用 dynamic thresholding 来改进 diffusion sampling

Imagen 的原理?
![]()
- 1)提取文本信息:把 prompt 输入到 frozen text encoder 中,得到 text embedding
- 2)文生图(64 x 64): 把 text embedding 输入到生成模型中,其实就是给模型信息,让他基于这个信息去生成图像。第一步先成低分辨率的图像
- 3)图像上采样(256 x 256):利用扩散模型上采样图片
- 4)图像上采样(1024 x 1024):利用扩散模型上采样图片
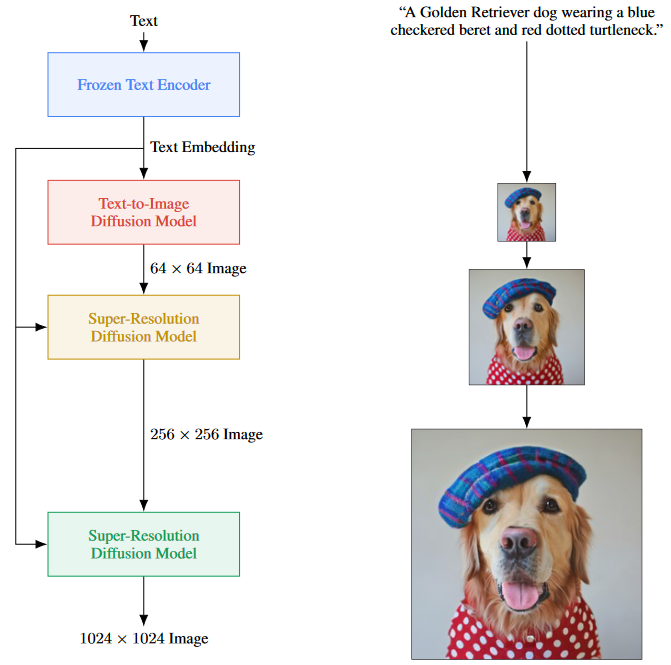
Imagen 中文本如何指导扩散模型?
![]()
- 在文生图模型上,论文使用的是 classifier-free guidance 的 DDPM,这时候会随机将这一引导信息置空,使得文生图模型具备有条件和无条件生成的能
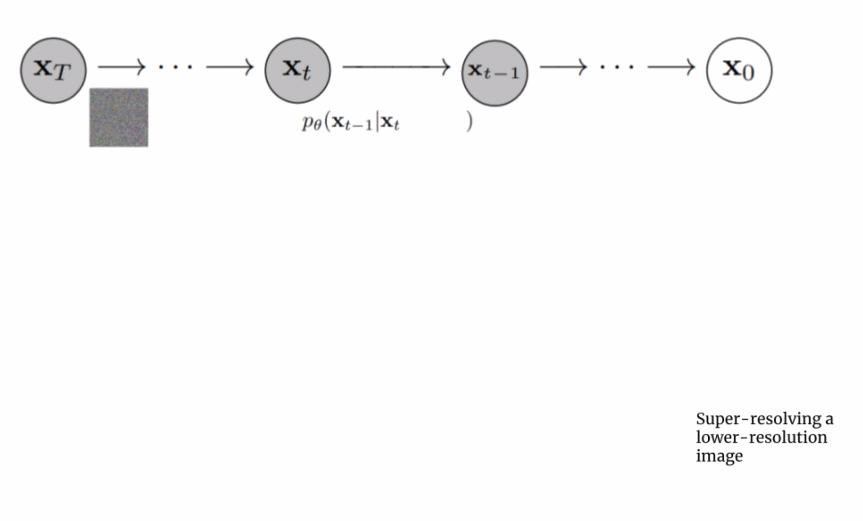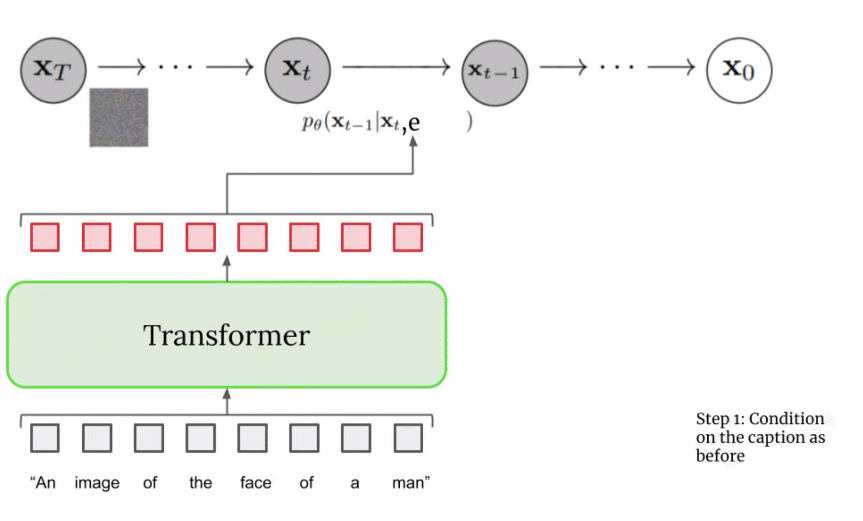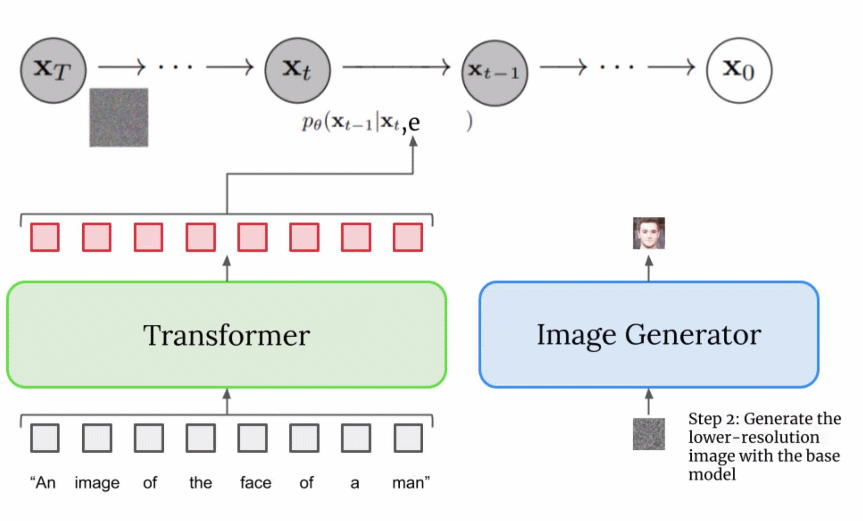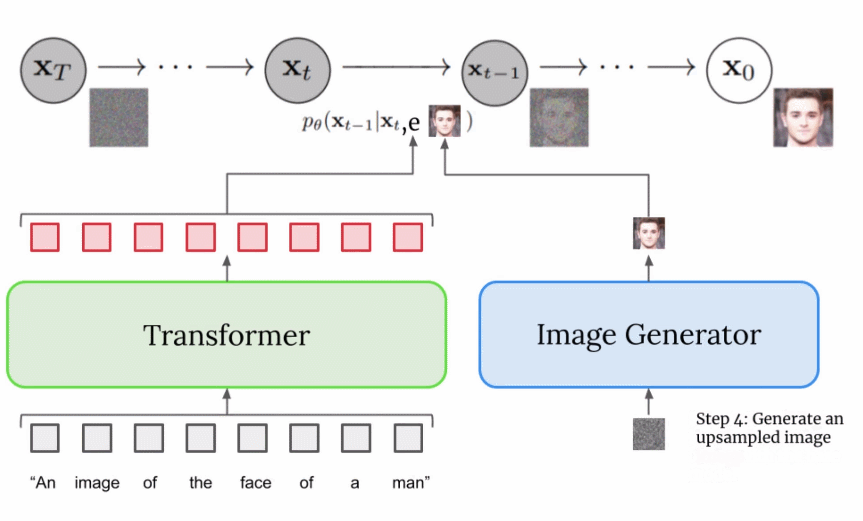
Imagen 如何使用 dynamic thresholding 来改进 diffusion sampling?
![]()
- 在文生图模型中,通过 w 控制 Conditional(文本) 参与训练的概率,提升 w 虽然有助于更好的图 - 文对齐,但是会导致生成图像的质量下降,而这一现象是由 w 的变化导致训练数据和测试数据失衡造成的
- 理想情况下,对于归一化到 [-1,1] 之间的训练数据 x ,我们希望在每个采样时间步 t,模型的预测输出 同样满足 [-1,1] 这样的数据分布,然而伴随着 w 的增大,预测的 可能会超出这一范围。为此,作者提出了静态阈值和动态阈值的概念,并发现动态阈值的效果会更好
- 静态阈值(static thresholding):表示将预测的 强制约束到 [-1,1] 中,类似 torch. clip 的操作
- 动态阈值(dynamic thresholding):令阈值系数 s 为百分比的绝对像素值([0, 255]/100=[0, 2.55]),如果 s>1 ,则将预测值归一化到 [-s, s],并除以 s,从而将输出自适应地归一化到 [-1,1] 之间

Imagen 提出的 Efficient U-Net?
![]()
- 上面分别是 Efficient U-Net 的下采样、上采样模块
- 标准 U-Net 做法中,下采样块的下采样操作是在卷积之后,上采样块的上采样操作是在卷积之前。作者颠倒了顺序,即下采样块的下采样操作是在卷积之前,上采样块的上采样操作是在卷积之后。这种做法能提升前向传播的速度,且不影响性能

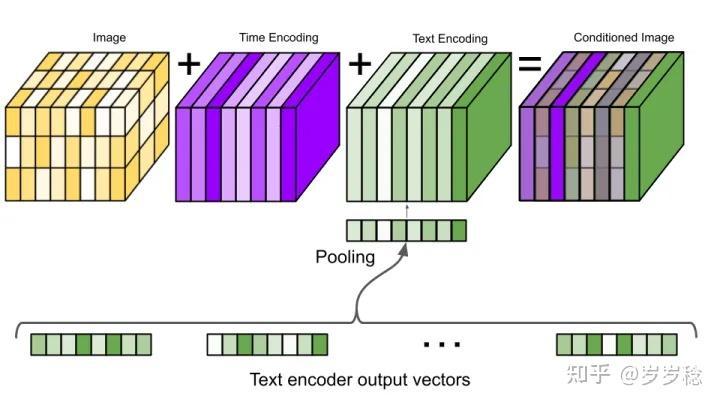
Imagen 的超分模块输入?
![]()
- 在两个超分模块中,除了 text embeddings 作为条件外,作者还将低分辨率的输出图像作为控制生成过程的条件之一。而对于文本编码的使用,则是先 **concat 到图像后面,然后再作 cross attention 处理,** 有点儿类似于 Stable-Diffusion
不同大语言模型的对 Imagen 的影响?
![]()
- 在同一训练步长下,各模型得分有明显差异,CLIP 得分:T5 XXL > CLIP > T5 XL > T5 Base
- 在同一 CLIP 得分下,收敛速度:T5 XXL > CLIP > T5 XL > T5 Base
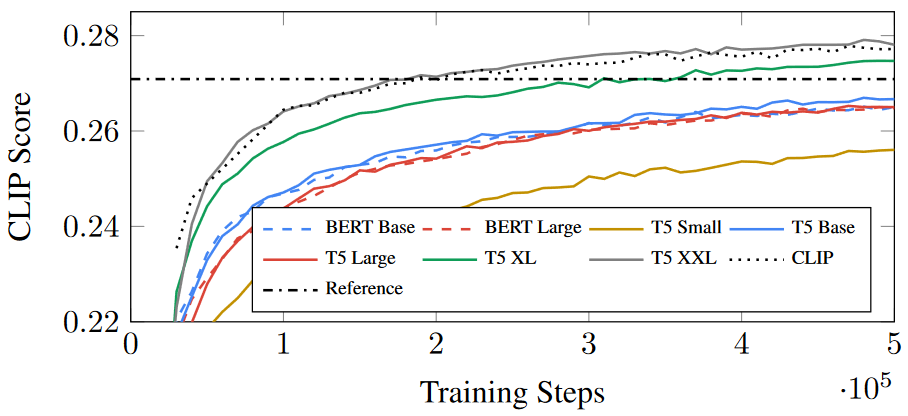
Imagen 与 DALL-E-2 的区别?
- DALL-E-2:使用 CLIP 在 image-text pair 训练的 text encoder(用一个 prior 网络把 text encoder 输出的 embedding 转为 image encoder 的输出,多了一个模型来做图文 embedding 的转换)。直觉上,语言模型训练的数据量远远大于 image-text pair , 并且其模型大小也远远大于当前的 image-text 模型,显然语言模型对于文本的理解能力更强,理解了文本才能生成高质量的图像
- Imagen:直接使用大语言模型编码文本信息
- 大语言模型(large language models-T5-XXL)的训练往往有着更多的数据,因为 text-only 的数据要远远多于成对匹配的 text-image 数据。所以说,大语言模型在理解文本方面往往有着更强大的能力
参考: