MasaCtrl:Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing
通过文本再编辑图片,生成的图片更符合新文本信息
- (图片)+ 文本 1->DDPM-> 条件图片
- (图片)+ 文本 2->DDPM-> 条件图片,文生图
什么是 MasaCtrl ?
![]()
- 是一种无需调整即可实现一致的图像生成和复杂的非刚性图像编辑。具体来说,MasaCtrl 将扩散模型中现有的自注意力转换为相互自注意力,以便它可以从源图像中查询相关的局部内容和纹理以确保一致性。并将掩码引导加入互注意力,实现前景和背景的分离

MasaCtrl 的原理?
![]()
- 模型输入:原始图像 、原始 prompt 和目标 prompt
- 模型输出:原始重构图 、目标重构图
- 模型训练:MasaCtrl 首先使用 VAE encoder 编码图片到潜空间 ,然后使用 DDPM 在潜空间下学习其分布,最终使用 VAE decoder 还原图片。上图展示包括原始 DDPM 过程和目标 DDPM 过程,其中目标 DDPM 可以使用原始的 DDPM 即可,也就对应模型无序训练,即可使用文本调整图片,即对元组 训练得到 ,各个部分分别计算损失
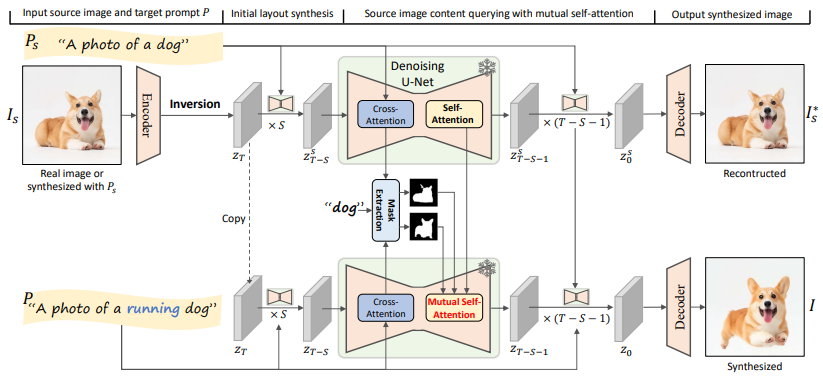
MasaCtrl 的推理过程?
![]()
- 1)遍历 T 个时间步,使用 DDPM 重构
- 2)首先使用模型估计算出 t 时刻源潜空间变量 和源 prompt 的噪声和源交叉注意力
- 3)使用源潜空间变量 和估计噪声生成 t-1 时刻的潜空间变量
- 4)使用模型估计算出 t 时刻目标潜空间变量 和目标 prompt 的噪声和目标交叉注意力
- 5)按以下公式选择新的注意

- 6)使用新的注意力重新估计 t 时刻的目标噪声
- 7)根据 t 时刻目标噪声,还原 t-1 时刻的目标潜空间变量
- 8)遍历完成,返回源潜空间变量 和目标潜空间变量
MasaCtrl 如何构造互注意力?
![]()
- 通过在不同的时间步上使用不同的 QKV 构建交叉注意力的过程叫作互注意力,MasaCtrl 的选择原则如下,其中 是 Source image 的注意力, 是 target image 的注意力
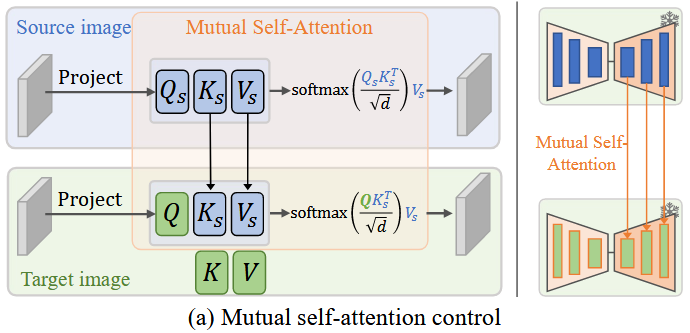
- 下图 a 是互注意力在不同 step 就介入 Unet 过程实现 -> ,可知过早的介入导致 生成效果差,因此上面公式在在时刻 S 时刻后才进行注意力交换;(b) 图进一步观察是不同时间步交叉注意力在 Encoder 和 Decoder 的可视化,可知浅层的交叉注意力无法感知清晰的图片布局,因此不能提前交换注意力
![]()

MasaCtrl 如何做到掩模引导的相互自我关注?
![]()
- 上述合成 / 编辑会失败,因为对象和背景太相似而无法混淆。为了解决这个问题,一种可行的方法是将图像分割为前景和背景部

- 上图 是目标在 上的前景区域, 分别是前景、背景注意力, 是最终注意力
MasaCtrl 和其他使用文本编辑图片模型的区别?
![]()
- 由图可知 MasaCtrl 方法更能保持一致的前景

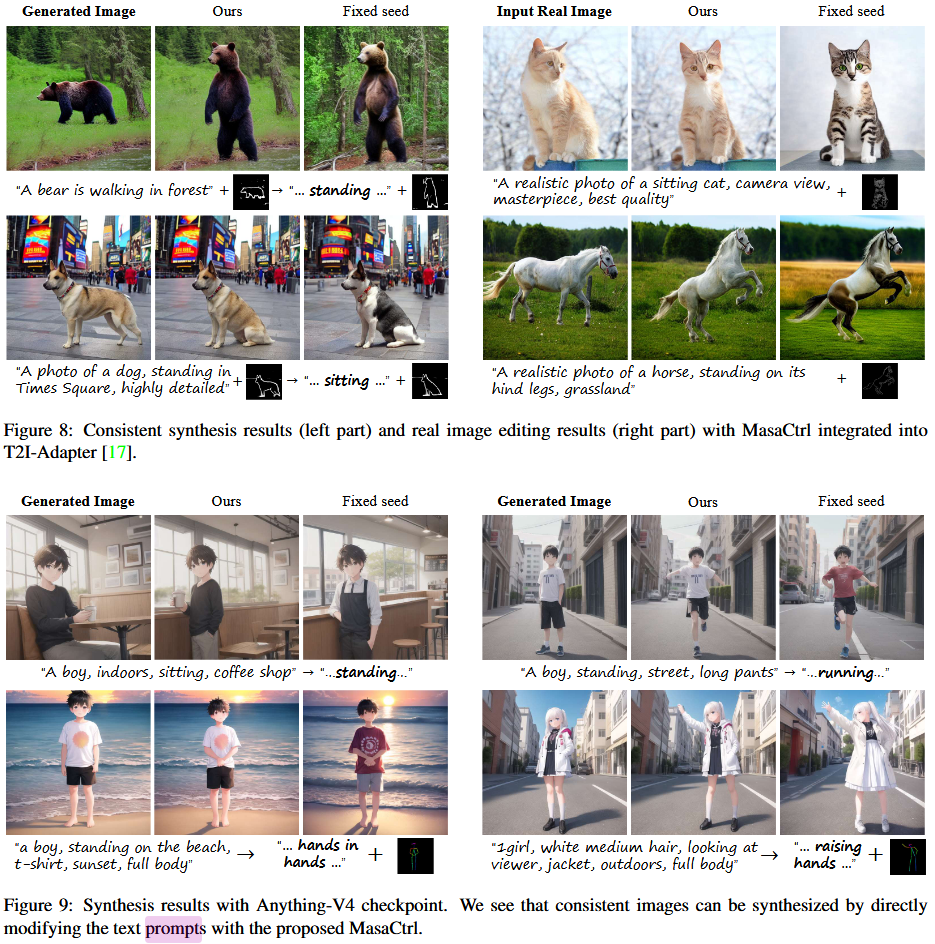
MasaCtrl 的思路结合到现有模型上?
![]()
- 将 MasaCtrl 通过互注意力调整图片的技术应用到其他文生图的模型上,可知 MasaCtrl 的方法生成的图片更能保持前景一致
MasaCtrl 在不同去躁时间步、不同层中其互注意力控制的结果?
![]()
- 在 (a) 图的去躁过程中,目标 prompt 没有立即生效,而是在 step 5 之后生效,即随着步长的增加,合成的所需图像可以保持目标提示的布局和源图像的内容。而图像会逐渐失去源图像内容,最终成为没有相互自注意力控制的图像合成图像
- 在 (b) 图对不同 U-Net 层中进行控制时,也观察到类似的现象。对各层进行控制只能生成与源图像相同的图像。在低分辨率层(例如,层 4∼10)中执行控制无法保留源图像内容和目标布局。而在高分辨率层(例如,层 0∼3、10∼15)中,可以保持目标布局,并且只有在解码器部分控制时才能变换源图像内容
