P2P:Prompt-to-Prompt Image Editing with Cross Attention Control
- (图片)+ 文本 1->DDPM-> 条件图片
- (图片)+ 文本 2->DDPM-> 条件图片,文生图
什么是 Prompt-to-prompt?
![]()
- 对于文生图模型,如果只是修改文本的某些字符,其生成的图片一般变化很大(如图下,只固定随机种子),Prompt-to-prompt 希望保留图片的大部分区域,让文本变化只作用于目标区域(如图上,固定随机种子和 attention map),蛋糕保持原始输入形状,只是配色和装饰在变化
- Prompt-to-prompt 是基于以下发现,实现对图片空间布局的控制:即控制 DDPM 生成内容的超参除了随机种子 seed 外,还有交叉注意力 attention map,如果在改变文本的生成图像过程中使用未改变文本的 attention map,那么生成的图片能保持空间布局不变
- Prompt-to-prompt 对于任意图片,由于其对应的 prompt 未知,所以直接使用 Prompt-to-prompt 来编辑图片的效果不佳,所以应用场景比较受限

Prompt-to-prompt 的原理?
![]()
- 总的来说,在 DDPM 的第 t 步去躁时,分别求出文本修改前后的 attention map,通过 将修改文本前的 attention map 影响修改文本后的 attention map,再使用新文本生成图片
- 1) 输入:原始 prompt P 、目标 prompt P∗和随机种子
- 2) 输出:原始 P 生成的图像 和目标 prompt 生成的图像
- 3) 用随机种子 s,从高斯分布中随机采样一个
- 4) 用 给 赋值
- 5) for t=T, T-1,…, 1 do(进循环)
- 6) 对于每一个扩散步,根据 计算出上一时间步噪声图 和当前时间使用的 attention map ,
- 7) 对于每一个扩散步,根据 计算出修改 prompt 后的 attention map
- 8) 用 Edit 编辑操作,把中一部分特征图用替换,得到 中一部分特征图用 替换,得到
- 9) 用 替换 ,再重新走一遍去躁过程,得到新的
- 10) end 结束循环;
- 11) 返回和 和 (把它俩喂给 VAE 的 Decoder 就可以得到前后 Prompt 对应的图像)

Prompt-to-prompt 如何控制 attention map?
![]()
- 图片上半部分是文生图过程中,图片 token 和文本 token 构建交叉注意力 attention map ,并基于这个注意力估计噪声;下班部分是利用未修改 prompt 前的交叉注意力 attention map 编辑修改 prompt 后的交叉注意力 attention map ,输出新的交叉注意力 的过程
- Word Swap(替换词): 从 “a big red gicycle” 到 “a big red car”,就把 M 里 “bicycle” 对应的特征图换成 “car” 对应的特征图。最主要的挑战是保持保持原始构图的同时处理新 prompt 的内容,通过限制注入的步数,就可以主导新生成图像的构图,同时对新 prompt 允许自由地采用几何形状
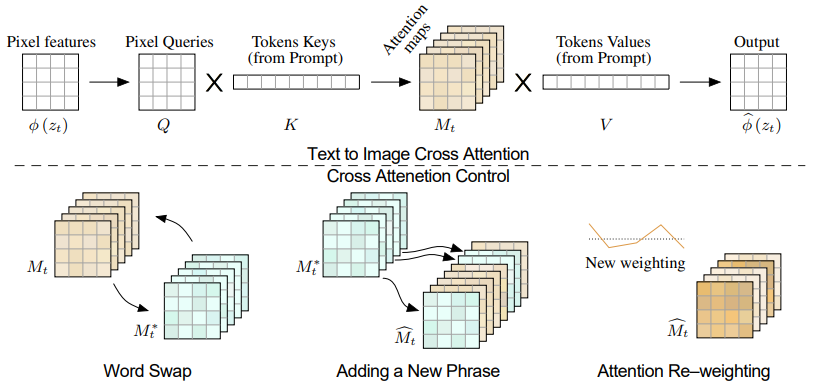
- Adding a New Phrase(新增词) 用户在 prompt 里添加了新 token,例如 P=“a castle next to a river” 到 P^=“children drawing of a castle next to river”。为了保持一般细节,只把 attention 注入进两个 prompt 共有的那些 tokens 里。形式上,这里用一个校准方程 A 来接收目标 prompt P∗ 的 token 索引,输出在 P 中的 token 索引,如果不匹配则直接输出 Non
- Attention Re-weighting(注意力重加权) 用户也许希望增强或减弱某个 token 对最终图像的影响程度。例如,考虑 prompt P=“一个毛茸茸的红色球”,比如我们想让球更毛茸茸或不要那么毛茸茸。为了获得这样的操作,这里用参数 c∈[−2,2] 缩放指定 token,来对结果产生更强或更弱的影响。其他的 attention maps 依然不
Prompt-to-prompt 的 Text-Only Localized Editing(用文本编辑局部图像)?
![]()
- Prompt-to-prompt 可以用文本对图片进行局部修改而不需要画 mask,这张蝴蝶图,不管蝴蝶在什么东西上,蝴蝶本身的构图都没有变化

Prompt-to-prompt 的 attention 的注入的效果分析?
![]()
- 模型不仅限于修改纹理,也可以修改结构,把 “自行车” 改为 “小汽车”。为了分析 attention 的注入的效果,最左边一列是没有用 cross-attention 注入的结果,改了一个词就导致整个画面不同了。从左到右展示了逐步增加 “注入操作” 的扩散步数,也就是说越靠右,就有越多的步数注入了 attention。可以看出有更多注入操作后,图像与原图就有跟高的一致性。然而在所有步骤中都用注入操作未必能让生成效果达到最好,因此可以通过控制注入步数,让用户更好地控制图像与原始图像的一致性

Prompt-to-prompt 的新增 prompt 结果分析?
![]()
- 除了替换某个词,用户可能会加一些新词来生成图像。在这种情况下,保持原来 prompt 的 attention maps 不变,允许生成器处理添加的新词。例如下面这张图,图的第一行增加了对车的描述,使得车变了背景没变

Prompt-to-prompt 的 Global editing(全局编辑)?
![]()
- 不仅能改局部图,也能改整幅图。在这个设置下,编辑操作应该影响图像的所有部分,但任然保持原图的构图,例如目标的位置和样子,看这张图,可以把素描转为真实风格,也可以把真实风格改为艺术风格

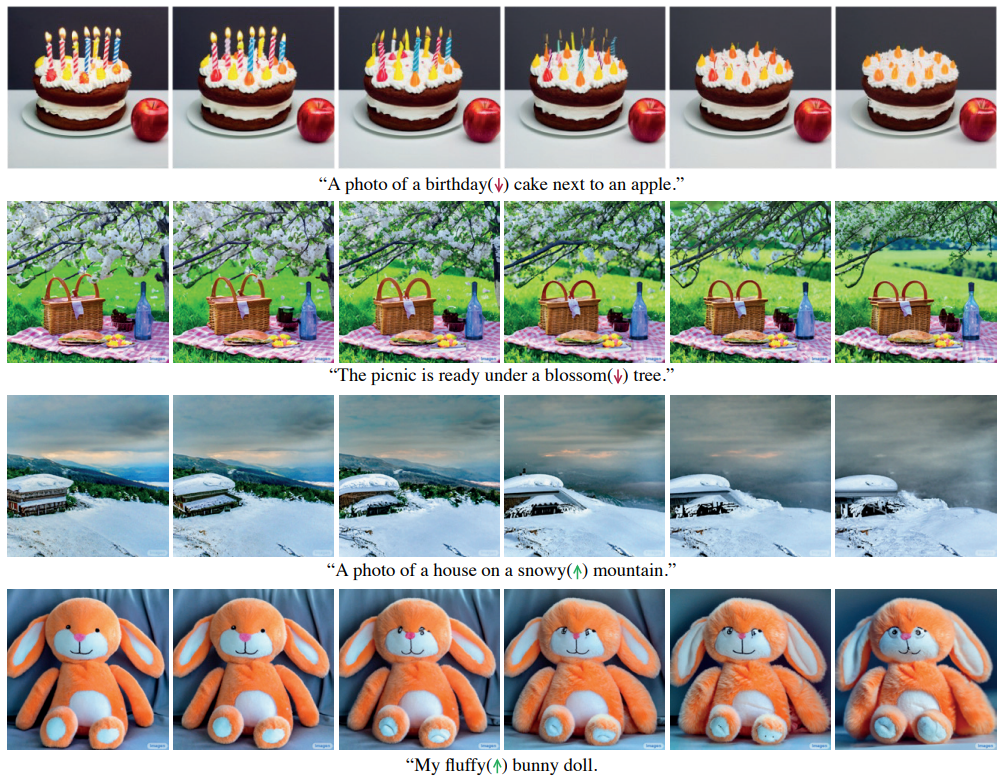
Prompt-to-prompt 的 Fader Control using Attention Re-weighting(使用注意力重加权的 Fader 控制)?
![]()
- 这里证明,通过控制某个词的权重,可以控制这个词对图像的影响大小):尽管用 prompt 控制图像编辑非常有效,但任然不能完全控制图像。考虑 prompt “雪山”,一个用户也许想控制山上的积雪量,然而很难用语言描述期望的雪量,所以这里作者引入 fader 控制,有了它用户就可以控制特定单词的影响大小
Prompt-to-prompt 的 Real Image Editing(真实图像编辑)?
![]()
- 这里说明,直接给一张图,怎么对它进行编辑,这里的难点是给定一张真实图像如何找到给定输入图像的初始噪声,本文采样了一种改进的倒置方法,它基于特定的 DDIM 模型而不是 DDPM 模型,上图是左边是用 DDIM 采样的倒置过程重构的图,右边是用本文方法编辑的图像
- 然而在很多其他情况下这种导致的方式并不成功,出现这种情况一部分原因是保真度和可编辑性的权衡

参考: