基于 PytorchQuantization 对语义分割模型量化
本文基于 PytorchQuantization 库对经典的语义分隔模型 deeplapv3 + 进行量化
量化过程概括如下:
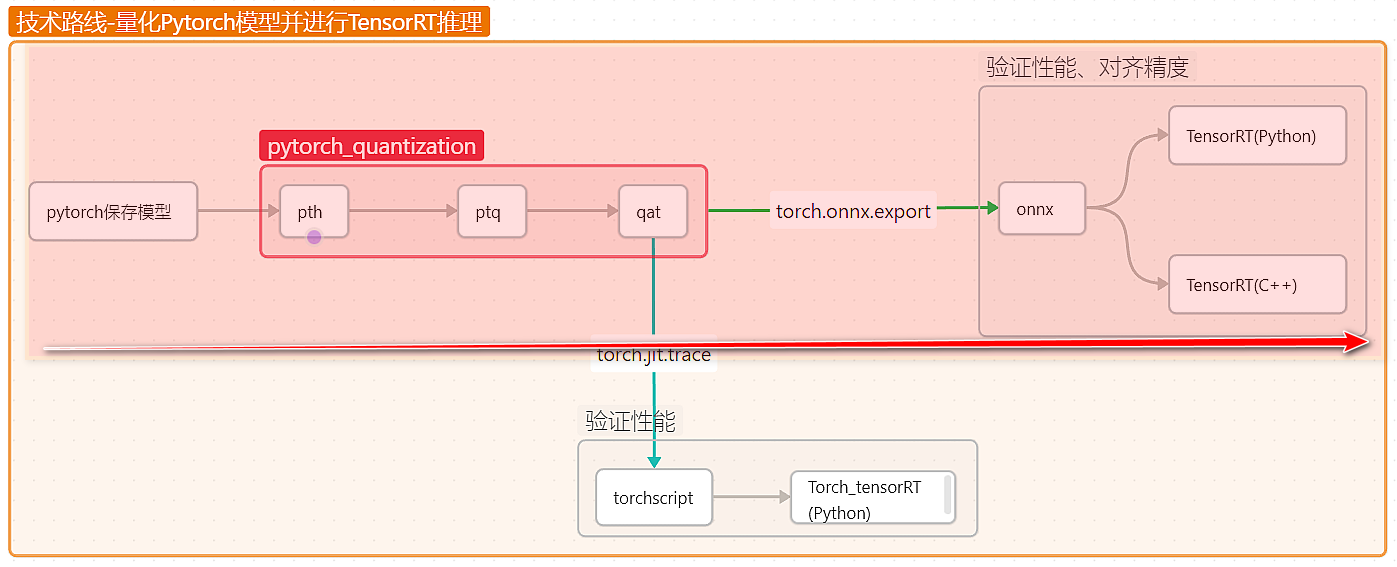
假设已经进行模型训练,并保存了 pth 模型,如 deeplabv3plus_base.pth,后续基于这个模型做量化处理,并且要保存数据加载方式,因为 ptq 量化需要读取数据上来校准模型
首先定义测量评估函数,用于测量推理耗时和模型效果
1 | cudnn.benchmark = True |
ptq 量化
(1)开启量化,并加载模型,此时模型已经被 ptq 量化
1 | quant_modules.initialize() |
(2)读取数据并校准模型
1 | def compute_amax(model, **kwargs): |
得到量化模型后,我们尝试使用 tensorrt 将其转为引擎
1 | # Set static member of TensorQuantizer to use Pytorch’s own fake quantization functions |
QAT 量化
QAT 量化在训练中进行,我们在 PTQ 量化基础上,将训练数据重新输入,校准量化参数
1 | def train(model, dataloader, crit, opt): |
同样地,使用 tensorrt 部署 qat 模型
1 | # Set static member of TensorQuantizer to use Pytorch’s own fake quantization functions |
比较结果
定义以下 tensorrt 推理流程,加载不同的 engine 上来推理,并计算推理时间
1 | import cv2 |
下图展示了量化前、ptq、qat 量化后的模型效果,可以看出效果差别不大
![[Pasted image 20250123185133.png]]
至于量化后的模型效果,展示如下表
| 阶段 | 效果 (%) | 性能 (ms) |
|---|---|---|
| Pytorch(base) | 99.65 | 93.03 |
| pytorch_quantization(base_ptq) | 99.64 | 164.48 |
| pytorch_quantization(base_qat) | 99.64 | 114.94 |
| tensorRT(base_fp32) | - | 6.9 |
| tensorRT(base_fp16) | - | 3.3 |
| tensorRT(ptq_int8) | - | 3.3 |
| tensorRT(ptq_int8_fp16) | - | 3.3 |
| tensorRT(qat_int8) | - | 3.3 |
| tensorRT(qat_int8_fp16) | - | 3.3 |
总结:
- 对于 base 和 ptq 或者 qat 量化后的模型,可以看出其效果不变,但是耗时增加了,这是因为模型插入了很多量化算子
- 使用 tensorrt 部署后,可以看出量化后确实比未量化
base_fp32速度快,但是 tensorrt 的量化base_fp16的效果足够优秀,没看出在 tensorrt 外进行 ptq、qat 量化的优势