推荐系统基本认识
什么是推荐系统?
- 推荐系统是信息过滤系统的一个子类,它根据用户的偏好和行为,来向用户呈现他 (或她) 可能感兴趣的物品
- 利用众人的数据协助推断。在实际数据上,这种方法效果一般,原因是类似于亚马逊等网站的商品太多了,用户之间很少能找到有很多重复的商品项,所以相似用户的构造会不准确。因而类似的规则便有很多噪声
推荐系统有几类?
- 协同过滤
- 基于内容的推荐系统
- 基于知识的推荐系统
什么是协同过滤?
- 是首次被用于推荐系统上的技术,至今仍是最简单且最有效的
- 协同过滤的过程分为这三步
- 收集用户信息
- 生成矩阵来计算用户关联
- 作出高可信度的推荐
- 这种技术分为两大类: 基于用户和基于物品
什么是基于用户的协同过滤?
- 基于用户的协同过滤本质上是寻找与我们的目标用户具有相似品味的用户。 如果 Jean-Pierre 和 Jason 曾对几部电影给出了相似的评分,那么我们认为他们就是相似的用户,接着我们就可以使用 Jean Pierre 的评分来预测 Jason 的未知评分。例如,如果 Jean-Pierre 喜欢星球大战 3: 绝地武士归来和星球大战 5: 帝国反击战,Jason 也喜欢绝地武士归来,那么帝国反击战对 Jason 来说是就是一个很好的推荐。一般来说,你只需要一小部分与 Jason 相似的用户来预测他的评价
![]()
- 可能出现的问题
- 用户偏好会随时间的推移而改变,推荐系统生成的许多推荐可能会随之变得过时
- 用户的数量越多,生成推荐的时间就越长
- 基于用户会导致对托攻击敏感,这种攻击方法是指恶意人员通过绕过推荐系统,使得特定物品的排名高于其他物品。(托攻击即 Shilling Attack, 是一种针对协同过滤根据近邻偏好产生推荐的特点,恶意注入伪造的用户模型,推高或打压目标排名,从而达到改变推荐系统结果的攻击方式)

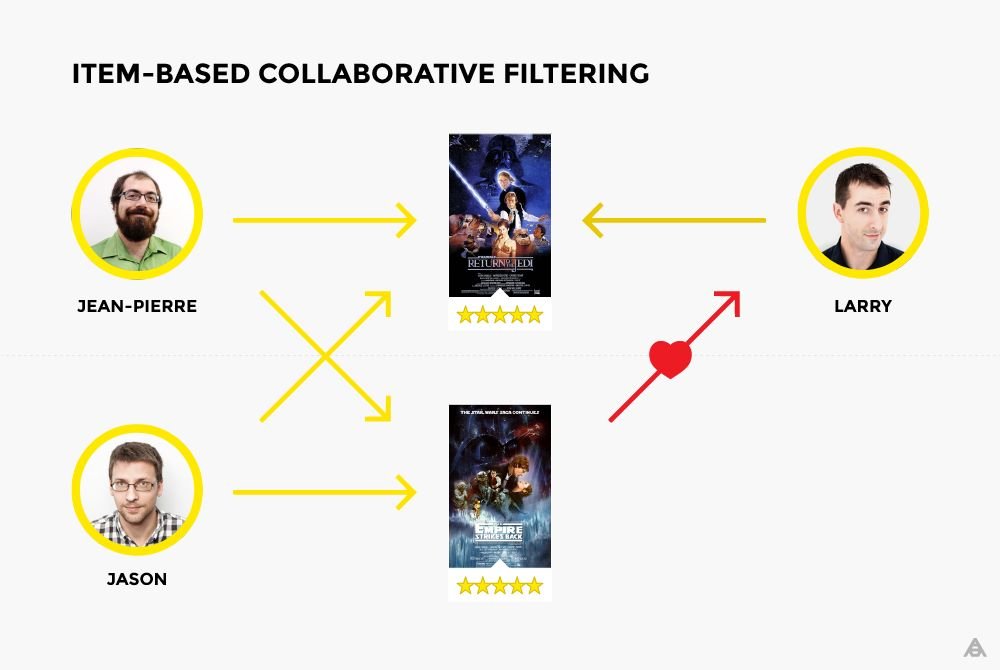
什么是基于物品的协同过滤?
- 基于物品的协同过滤过程很简单。两个物品的相似性基于用户给出的评分来算出,这里的相似度是根据列而不是行来计算的。 回到 Jean-Pierre 与 Jason 的例子,他们两人都喜欢 “绝地武士归来” 和 “帝国反击战”。 因此可以推断,喜欢第一部电影的大多数用户也可能会喜欢第二部电影。所以,对于喜欢 “绝地武士归来” 的第三个人 Larry 来说,” 帝国反击战 “的推荐将是有意义的
![]()
- 相比较基于用户的协同过滤,有以下优点
- 系统中的物品 (电影) 不会随着时间的推移而改变,所以推荐会越来越具有关联性
- 通常推荐系统中的物品都会比用户少,这减少了推荐的处理时间
- 考虑到没有用户能够改变系统中的物品,这种系统要更难于被欺骗或攻击
什么是基于内容的推荐系统?
- 在基于内容的推荐系统中,元素的描述性属性被用来构成推荐。举个例子,根据 Sophie 的听歌历史,推荐系统注意到她似乎喜欢乡村音乐。因此,系统可以推荐相同或相似类型的歌曲。更复杂的推荐系统能够发现多个属性之间的关系,从而产生更高质量的推荐
什么是基于知识的推荐系统?
- 基于知识的推荐系统不使用评价来作出推荐。相反,推荐过程是基于顾客的需求和商品描述之间的相似度,或是对特定用户的需求使用约束来进行的
- 基于知识的推荐系统在物品购买频率很低的情况下特别适用
什么是推荐系统中的冷启动问题?
- 推荐系统中的主要问题之一是最初可用的评价数量相对较小。此时, 协同过滤模型:比较困难基于内容和基于知识的推荐算法:比协同过滤更具有鲁棒性,但基于内容和基于知识并不总是可用的,因此,一些新方法,比如混合系统,已经被设计出用来解决这个问题了
什么是混合推荐系统?
- 一些推荐系统,如基于知识的推荐系统,在数据量有限的冷启动环境下最为有效。其他系统,如协同过滤,在有大量数据可用时则更加有效。可以结合多种不同技术的推荐来提高整个系统的推荐质量。
- 加权:为推荐系统中的每种算法都赋予不同的权重,使得推荐偏向某种算法
- 交叉:将所有的推荐结果集合在一起展现,没有偏重
- 增强:一个系统的推荐将作为下一个系统的输入,循环直至最后一个系统为止
- 切换:随机选择一种推荐方法