Word2Vecv2
对 Word 2 Vec 的 skip-gram 的改进,主要是通过构造树层次的输出,表示多层 softmax 的问题,减少了输出数量
什么是 Word2Vecv2 ?
- 对 Word2Vec 提出的 Skip-gram 模型的改进,原始模型存在多个 softmax 输出的问题,即 (1) 如果词表很大的情况小,单个 softmax 输出会很大;(2) 整个 softmax 只有一个正样本,并且训练数据出现大量的 "the, a" 等词汇,但是这些词汇作用不大;(3) 无法学习短语
- 解决第一个问题的思路是 Hierarchical Softmax,通过构造二叉树,将 softmax 输出结构化,使得 softmax 只需要计算 log (V) 次即可;针对第二个问题,解决思路是 Negative Sample,通过采样 k 个负样本更新模型,而不是使用整个词汇表;针对第三个问题,
Word2Vecv2 的 Hierarchical Softmax (HS)?
![]()
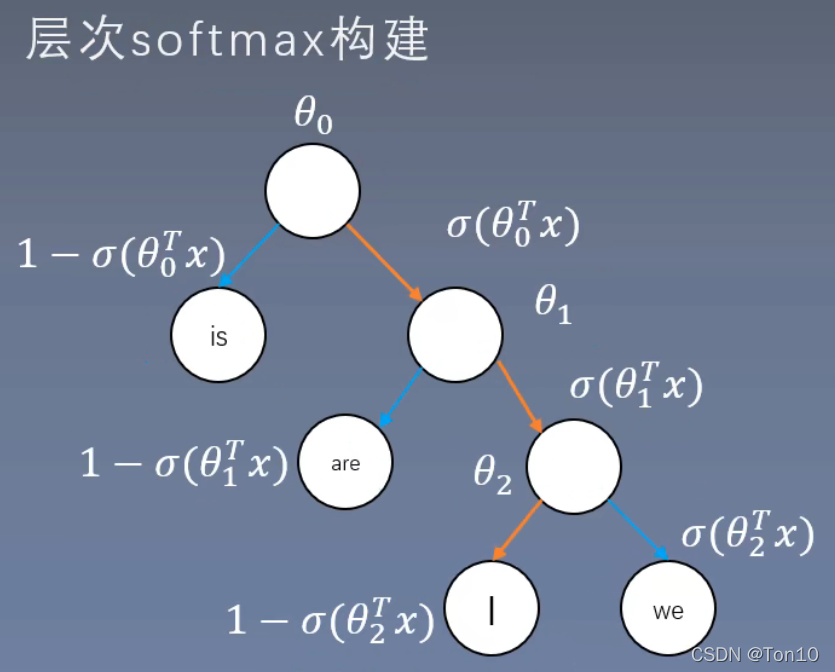
- 层次 Softmax 的核心思想是通过二叉树将求 softmax 的过程转为求 sigmoid,从而将计算量从词汇量 V 转为 log (V)
- Skip-gram 模型的哈夫曼树的构建:1)模型输出是一颗二叉树;2)树的叶子节点是词;3)根据词的频率计算叶子节点的权重,频率越大的层树越浅,频率越小的层数越深
- 求取损失过程:从根节点出发,以一半一半的概率走向左右两个子节点,直到遇到我们要求的词,然后拿出来计算损失。从树根到叶子,最深是 log (V) 的,所以其效率更高
- 注意:在二叉树中,从根节点到某个特定叶子(目标词汇)的路径是唯一的,所以首先每层计算 softmax,然后从根连乘到叶子,就是此处计算的叶子节点概率,如上图是 4 个词汇构成的二叉树
Word2Vecv2 的 Negative Sample (NS)?
![]()
- 负采样的核心是将多分类问题转为二分类,因为多分类和词表大小有关。对于 Skip-gram 模型,正样本是中心词汇,负样本是除中心词汇的任意词汇
- 在计算负样本损失时,不使用全部,而是采样一些负样本损失更新网络
Word2Vecv2 的 Subsampling of Frequent Words?
- 目的是更多训练重要词对,比如训练 "Chinese" 和 "Hangzhou" 的关系,少训练 "Chinese" 和 "the" 之间的关系。因为高频词对很快训练好了,低频则需要更多轮次
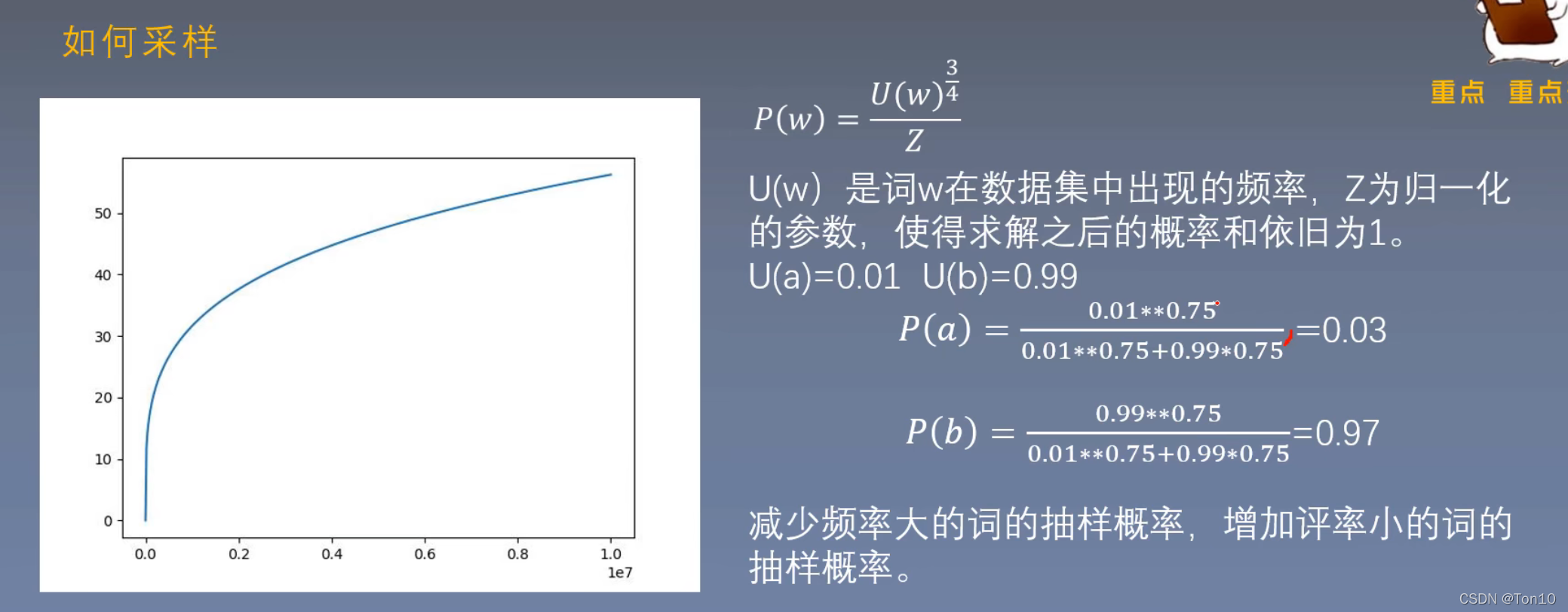
- 重采样方式是根据词的频率计算其删除概率,如果随机值大于删除概率,则从句子中删除该词,以下 t=10e-5,Wi 是词出现的频
参考: