Word2vecExplained
一个 3 层的神经网络,使用 one-hot 的方式输入,然后通过权重矩阵学习词的向量表示。学习方式分为 CBOW 和
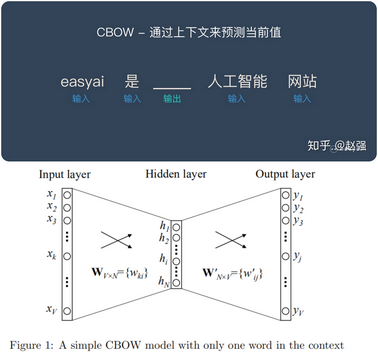
Skip-Gram,从直观上理解,CBOW 是给定上下文,来预测当前值,而 Skip-Gram 是给定当前值来预测上下文
什么是 Word2vecExplained ?
![]()
- 一个 3 层的神经网络,使用 one-hot 的方式输入,然后通过权重矩阵学习词的向量表示。学习方式分为 CBOW 和 Skip-Gram,从直观上理解,CBOW 是给定上下文,来预测当前值,而 Skip-Gram 是给定当前值来预测上下文
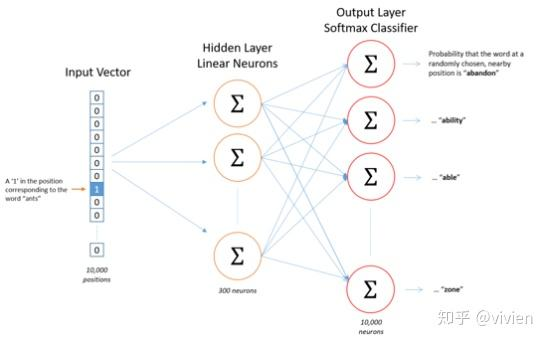
Word2vecExplained 的连续词袋 (continuous bag of words,CBOW) 模型结构?
![]()
- 定上下文,来预测当前值,图示是给定 t 前后的 2 个词,预测 t 位置的词
- 首先通过将上下文的 one-hot 表示累加,然后输入到网络,假设输入是 1 个 V 长度的特征,经过一个 VxN 大小的权重矩阵后,输出 1xN 的隐变量表示,再经过权重矩阵 NxV 后,输出 1 xV 的输出,最后作 softmax 分类即可
Word2vecExplained 的跳字模型 (Skip-gram) 模型结构?
![]()
- 与 CBOW 模型相反。目标词现在在输入层,而上下文词在输出层
- 计算损失时使用多个交差熵即可

Word2vecExplained 模型训练加速方式 - Negative Sample?
- 既然输出层的计算量太大,那么我们随机采样一些计算就可以了。不过对应输出的目标词汇的 one-hot 编码中非 0 的位置,所谓正样本是一定要保留的,而对于其他的目标真实值为 0 的样本,所谓负样本,就可以酌情采样了
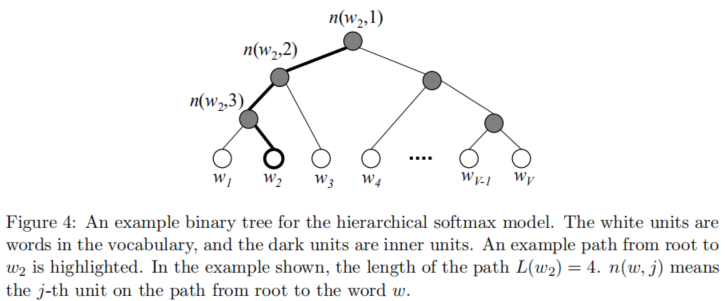
Word2vecExplained 模型训练加速方式 - Hierarchical Softmax?
![]()
- 层次 softmax 是一种高效计算 softmax 的方法,其使用二叉树来表示词表中的所有词,每一个词都必须是树的叶子结点,对于每一个结点,都存在唯一的路径从根结点到当前叶子结点,该路径就被用来估计此叶子结点表示的词出现的概率
- 红色点点代表了所有可能的输出的词汇,也就是一共有 V 个红色点点。这里我们假设 V 正好是 2 的 n 次方。这样就可以很容易地证明黑色点点的个数其实就是 V-1
- 从 root 节点开始向下走,每一步向左还是向右都是一个由某些参数决定的概率,我们的目标是优化这些路径上的参数,使得最终落到 的概率最大。这样的话,每一次梯度优化,我们只需要更新从 root 节点到目标词汇叶子节点上的 个参数就可以了。训练的复杂度也就从 V 下降为
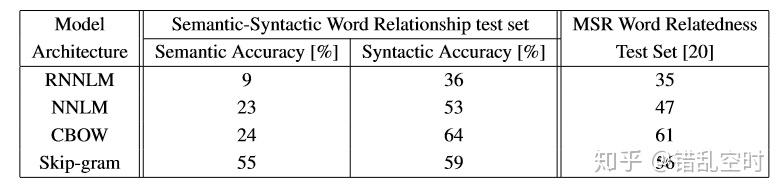
Word2vecExplained 如何验证词向量准确性?
![]()
- 论文中设置了 5 种语义问题与 9 种句法问题来测试向量效果,通过类似 vec (big)-vec (bigger)≈vec (small)-vec (smaller) 的方式来判断
- 测试结果如下图所示,在相同数据上训练的 640 维词向量,CBOW 在句法层面上表现得较好,Skip-gram 在语义层面上表现得更好,总体来说还是 Skip-gram 更好些
- 一般来说,CBOW 比 Skip-gram 训练速度快,训练过程更加稳定,原因是 CBOW 使用上下文 average 的方式进行训练,每个训练 step 会见到更多样本。而在生僻字(出现频率低的字)处理上,skip-gram 比 CBOW 效果更好,原因是 skip-gram 不会刻意回避生僻字 (CBOW 结构中输入中存在生僻字时,生僻字会被其它非生僻字的权重冲淡)
Word2vecExplained 如何使用?
- 无论是 CBOW 还是 Skip-Gram 中,都有两个权重矩阵 W 和 W‘,其中 W 反映的是一个词本身的词义,W’ 反映的是其他词与该词的搭配状况。上下文词向量的意思不是上下文单词的词向量,而是用来反映单词搭配状况(而非这个词的词义本身)的向量。一般来说词向量是指 W
参考: